Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Using PyTorch, FastAI and the CIFAR-10 image dataset
In this article, we’ll try to replicate the approach used by the FastAI team to win the Stanford DAWNBench competition by training a model that achieves 94% accuracy on the CIFAR-10 dataset in under 3 minutes.
NOTE: Some basic familiarity with PyTorch and the FastAI library is assumed here. If you want to follow along, see these instructions for a quick setup.
Dataset
The CIFAR-10 dataset consists of 60,000 32x32 color images in 10 classes, with 6,000 images per class. There are 50,000 training images (5,000 per class) and 10,000 test images. Here are 10 random images from each class:

You can download the data here or by running the following commands:
cd datawget http://files.fast.ai/data/cifar10.tgztar -xf cifar10.tgz
Once the data is downloaded, start the Jupyter notebook server using the jupyter notebook command and create a new notebook called cifar10-fast.ipynb inside fastai/courses/dl1.
Let’s define a helper function to create data loaders with data augmentation:
A few things to note about get_data:
- We’re using the data/test as the validation dataset, to keep things simple. Typically, you should use a subset of the training data for validation.
- We’re using multiple workers to leverage multi-core CPUs. This helps load the images and apply transformations faster.
- The variable stats contains channel-wise means and standard deviations for entire dataset, and is used to normalize the data.
- The data loader aug_dl applies data augmentation to the validation dataset. It is used for test time augmentation (TTA).
Network Architecture
We’ll use a model called WideResNet-22, inspired from the family of architectures introduced in the paper Wide Residual Networks. It has the following architecture:
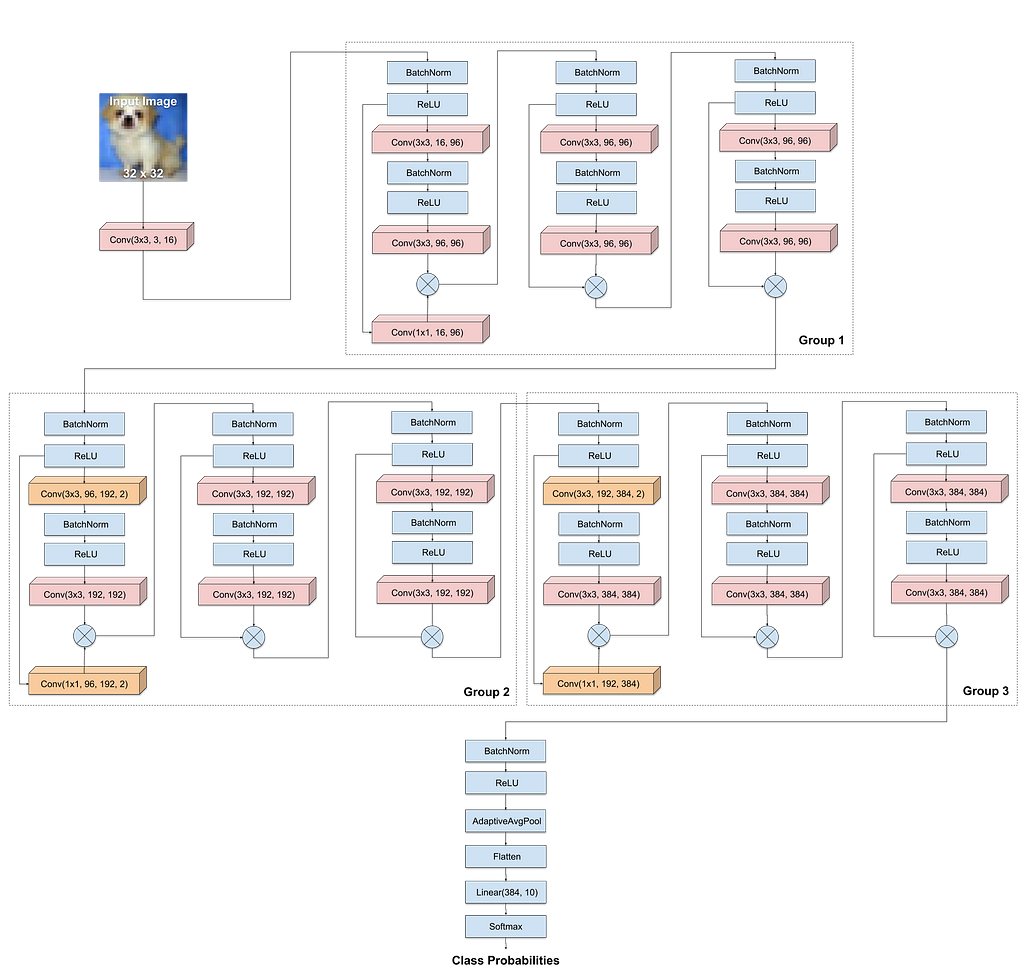
A few notable aspects of the architecture:
- It’s quite similar to popular ResNet architectures, except that the intermediate layers have a lot more channels (96, 192 & 384)
- It has 22 convolutional layers, indicated in the diagram as Conv(size, input_channels, output_channels, stride=1).
- There are 9 residual blocks with shortcut connections, organized into 3 groups. The first block of each group increase the number of channels to 96, 192 and 384 respectively.
- The first blocks of groups 2 & 3 also downsample the feature map from 32x32 to 16x16 and 8x8 respectively using convolutional layers with stride 2 (highlighted in orange).
Let’s first implement a generic module class for creating the residual blocks:
Next, let’s define a generic WideResNet class which will allow us to create a network with n_groups groups, N blocks per group and a factor k which can be used to adjust the width of the network i.e. the number of channels. It also adds the pooling and linear layers at the end.
Finally, we can also create a helper function for WideResNet-22, which has 3 groups, 3 residual blocks per group and k=6. It’s always a good idea to define flexible and generic models, so that you can easily experiment with deeper or wider networks.
Training and Evaluation
Let’s define a couple of helper functions for instantiating the model and evaluating the results:
Finally, let’s train the model using the 1 cycle policy, which involves gradually increasing the learning rate and decreasing the momentum till about halfway into the cycle, and then doing the opposite. Here’s what it looks like:
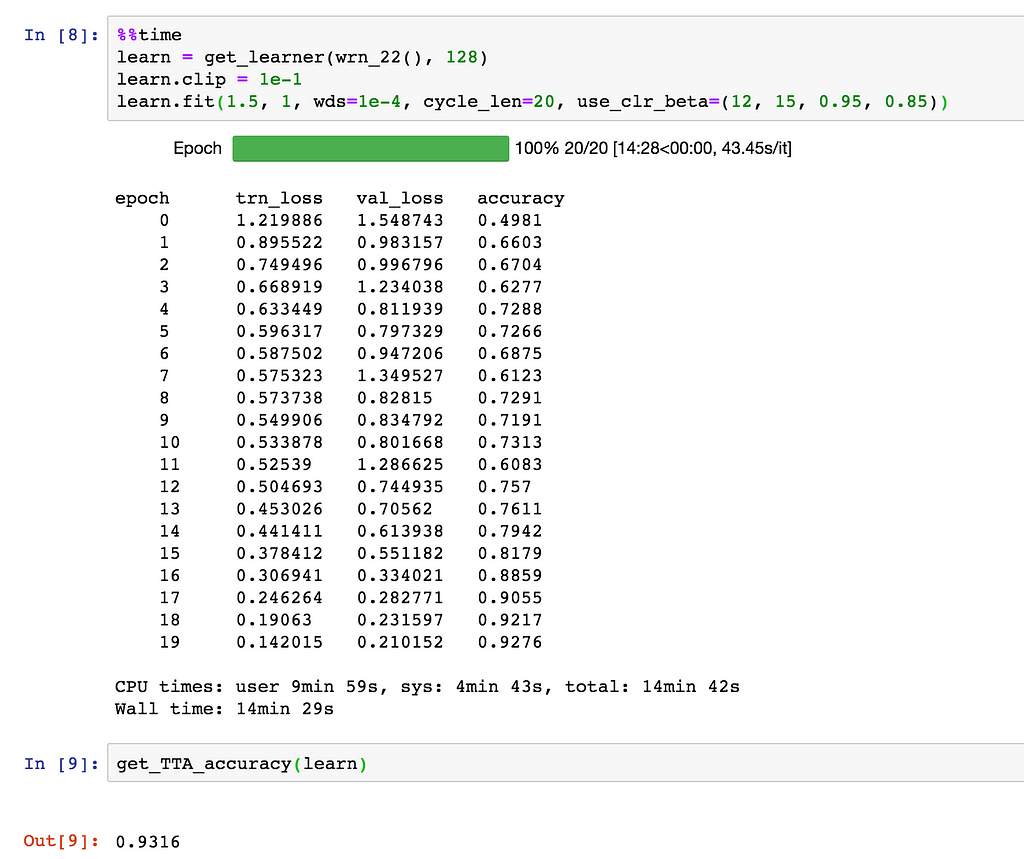
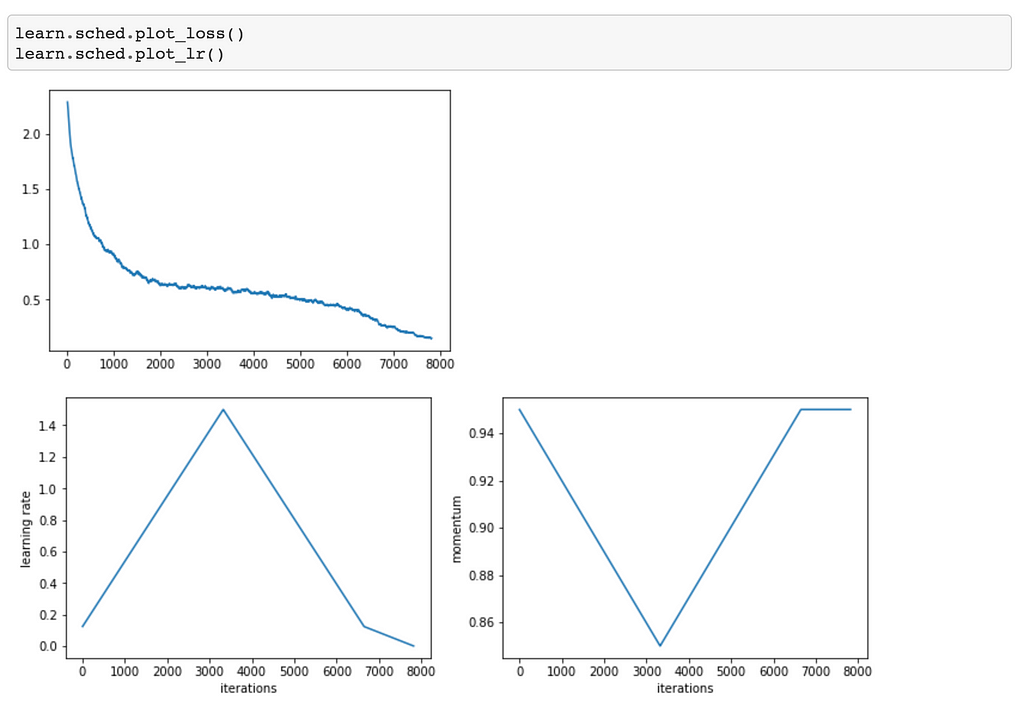
On a 6-core Intel i5 CPU and NVIDIA GTX 1080 Ti, the training takes about 15 minutes. You might see slightly different results depending on your hardware. Here’s a plot of the loss, learning rate and momentum over time:
And that’s it! Feel free to play around with the network architecture, learning rate, cycle length and other factors to try and get a better result in a shorter time. You can find the entire code for this post in this Github gist.

Training an Image Classifier from scratch in 15 minutes was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.