Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Written by Ryan Kim (@chokobole33)
The aim of this article is to provide the motivation of the Tachyon project and present our current status and future roadmap. Consequently, more people can engage with and utilize the Tachyon for their own uses.
TL;DR
- The TwoAdicFri commitment scheme from Plonky3 has been introduced, making it about 1.6 times faster than Plonky3’s op-succinct-0.1.4.
- Witness generation in Circom using C++ is now feasible for large circuits.
Overview
Kroma aims to solve problems from using fault proofs in Optimistic Rollups and, consequently, became the first to commercialize the ZKFaultProof technology. Key improvements include:
- Reducing interaction costs on L1 using ZK.
- Increasing decentralization of validators by reducing the necessary bond.
Challenges arose from choosing the Scroll-based zkEVM, including:
- Maintenance issues to keep compatibility between Optimism Geth and Scroll’s ZKTrie.
- Circuit maintenance difficulties as changes in Optimism Geth happen more frequently than in Scroll Geth.
- Lack of derivation logic from Optimism in Scroll zkEVM-based circuits.
- Expensive withdrawals because verification using ZKTrie consumes more gas compared to MPT-based verification.
Because of these reasons, Stage 1 hasn’t been achieved yet. Additionally, although ZKTrie is designed for efficient ZK proof generation with reliance on Poseidon hash, it is slower and less optimized compared to Keccak-based MPT. This results in slower block generation and a reduction in TPS for Kroma’s FaultProof, where ZKProof generation is only needed when a challenge happens.
In the new zkVM Fault Proof, Kroma intends to overcome these challenges and achieve Stage 1 by next year, focusing on improvements in maintainability and cost efficiency. The Tachyon 0.4.0 release has enabled faster SP1 proof generation, supporting Kroma’s transition.
What’s Optimized in v0.4.0?
Witness generation in Circom using C++ is now feasible for large circuits
To generate a proof using Circom, a .wtns file is required. This file can be created in two ways, as outlined below.
C++ Method
- Run Circom on <circuit>.circom to produce <circuit>.cpp.
- Compile <circuit>.cpp and main.cpp to create <circuit>.exe.
- Run <circuit>.exe on input.json to generate <circuit>.wtns.
WASM Method
- Run Circom on <circuit>.circom to produce <circuit>.wasm.
- Run <circuit>.wasm and generate_witness.js on input.json to generate <circuit>.wtns.
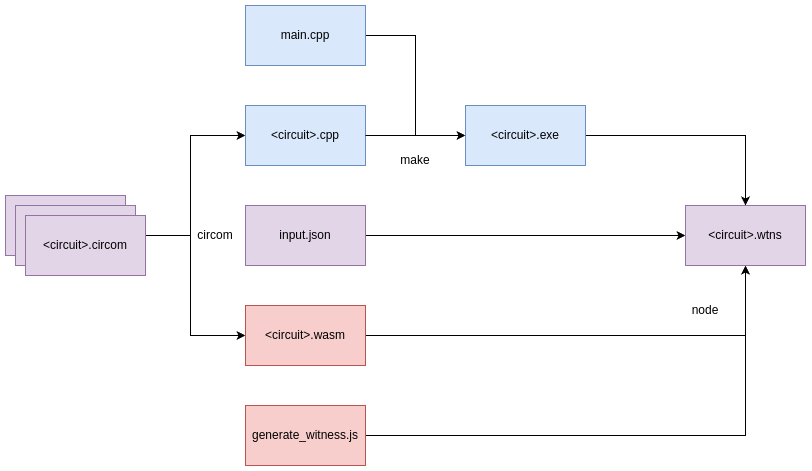
Fig 1. Witness Generation Flow
In production environments, <circuit>.exe is typically used to generate the witness due to its speed; however, it could require expensive compilation costs, which may prompt some users to switch to the WASM method. For example, in the zkEmail team’s case, a <circuit>.cpp file generated from a Circom file was around 4 million lines, resulting in a 6-hour compilation time that ultimately crashed. Consequently, they switched to the WASM method, which took only 40 seconds to generate the witness.
The structure of <circuit.cpp> is as shown below. The majority of this file consists of circuit specific functions. By distributing these functions across multiple .cpp files, the compile time for witness generation from a single large <circuit.cpp> was reduced to 10 minutes, and the witness itself could be generated in just 1.4 seconds. Considering that the circuit is usually compiled only once before generating multiple witnesses, the 10-minute compile time is negligible, and witness generation speed has been improved by approximately 28 times than WASM method. You can refer to the Circom witness generator compilation guide for usage instructions.
// == circuit specific function declartion start ==
void f1();
void f2();
...
// == circuit specific function declartion end ==
// == common function definition start ==
uint get_main_input_signal_start() { ... }
...
// == common function definition end ==
// == circuit specific function definition start ==
void f1() {}
void f2() {}
...
// == circuit specific function definition end ==
void <circuit>_create() {
// ...
}
void <circuit>_run() {
// call f1(), f2(), ...
}
void run(Circom_CalcWit* ctx) {
<circuit>_create(...);
<circuit>_run(...);
}
What’s New in v0.4.0?
Support for Plonky3’s TwoAdicFri
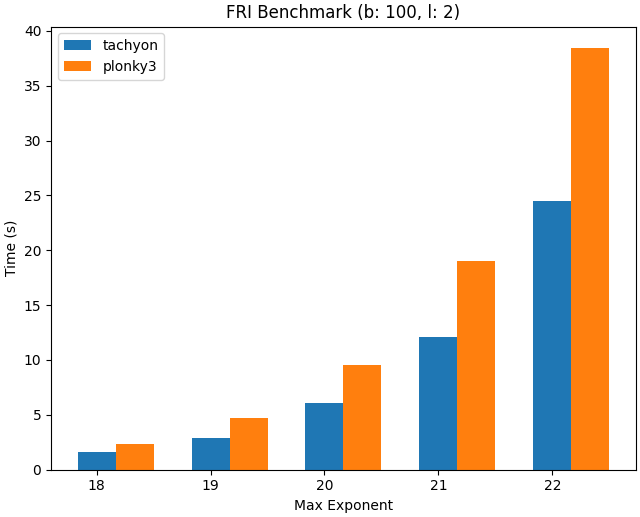
Fig 3. FRI Benchmark when b(batch_size) = 100 and l(log_blowup_factor) = 2
In this release, the TwoAdicFri commitment scheme from Plonky3 has been implemented. Benchmarking with a log blowup factor of 2 and using 100 polynomials at various degrees, showed that Tachyon performed 1.6 times faster than Plonky3. This test was conducted using the latest 0.1.4-succinct version available at the time of writing, and this branch can be executed by anyone.
The improved speed over Plonky3 can be attributed to several key factors, as outlined below.
Faster CosetLDE
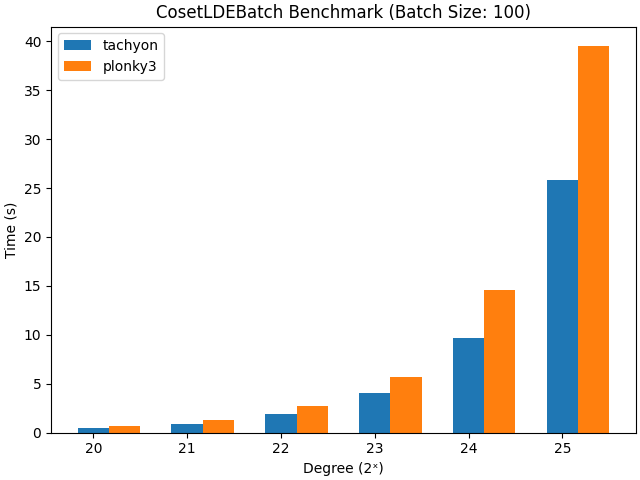
Fig 4. FRI Benchmark when batch size is 100
TwoAdicFri is an IOPP (Interactive Oracle Proof of Proximity) based on RS(Reed-Solomon) codes, requiring the polynomial to be expanded by a factor determined by the log_blowup_factor (a low-degree extension). This means that function values need to be calculated on a domain larger than the polynomial’s degree. Typically, parameters range between 1 and 2, where higher values yield slower but more secure proofs, while lower values are faster but less secure. For ZK(Zero-Knowledge) properties, the function values are calculated within a coset domain, hence the function name CosetLDEBatch().
Tachyon outperforms Plonky3 by parallelizing the multiplication of all rows in the matrix by powers of the coset_shift value, improving speed. This difference is expected to be addressed in a new Plonky3’s commit; however, Tachyon has still been measured to be slightly faster.
Improved Parallel Processing with OpenMP
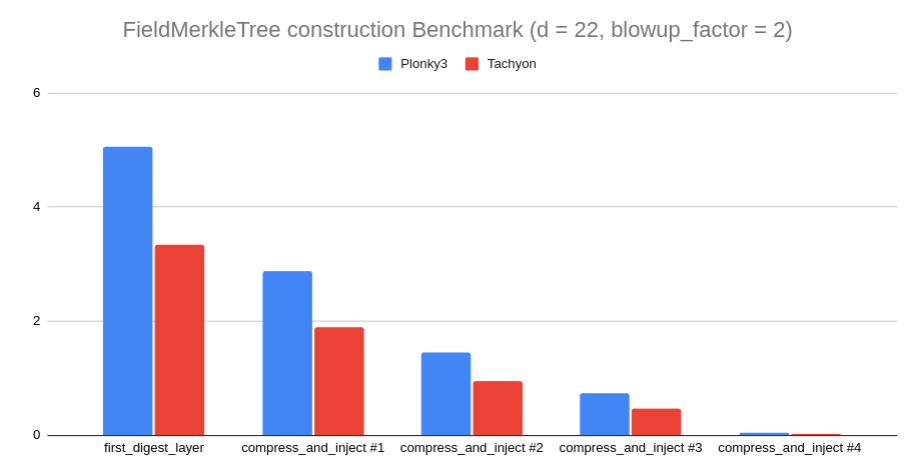
Fig 5. FieldMerkleTree construction Benchmark when d(degree) = 100 and log_blowup_factor = 2
While Tachyon’s Open() function is faster than Plonky3’s, Commit(), which is called more frequently than Open(), is the more critical function to optimize. Commit() involves both CosetLDEBatch() and MerkleTree creation. Creating a MerkleTree in Tachyon is about 1.5 times faster due to OpenMP’s superior thread utilization compared to Rayon.In this release, we introduced a profiler called Perfetto, which enabled further performance improvements through engineering optimizations focused on enhancing thread utilization like below.
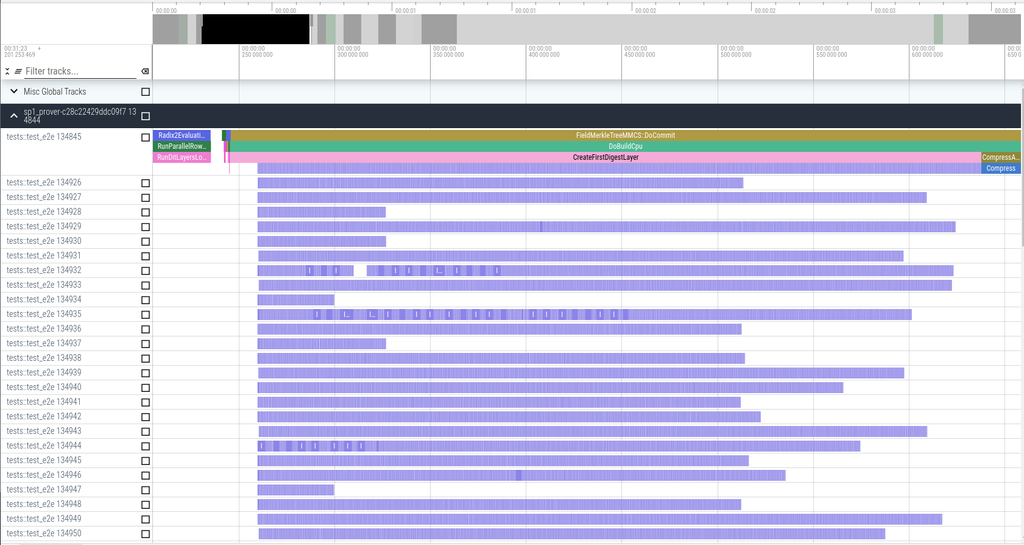
Fig 6. Profiling of CreateFirstDigestLayer with static scheduling
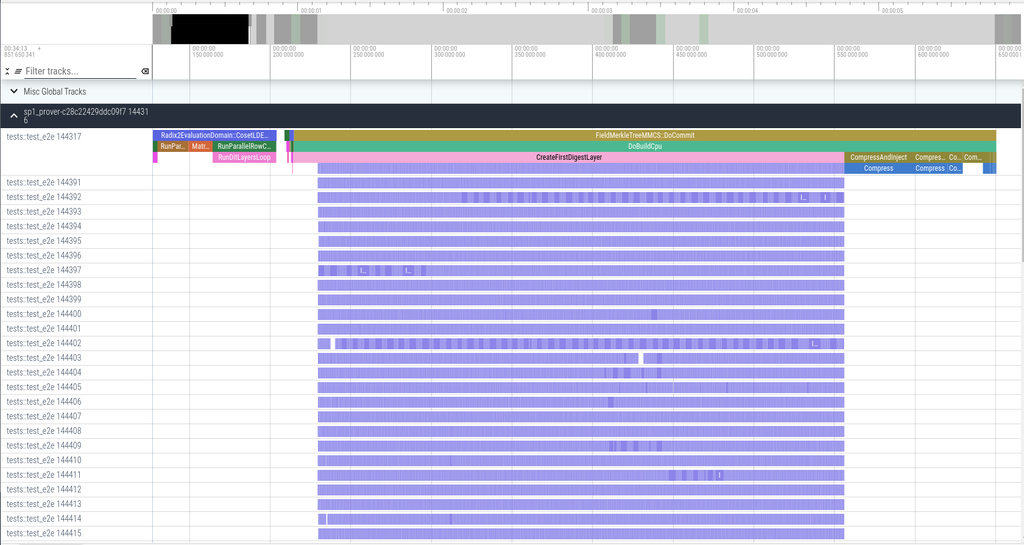
Fig 7. Profiling of CreateFirstDigestLayer with dynamic scheduling
Limitation
Slower Poseidon2
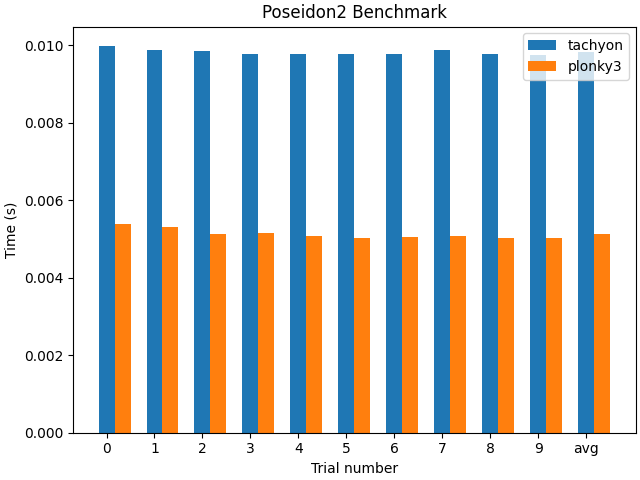
Fig 8. Poseidon2 Benchmark with g++-11.4.0
(This is the time taken to run the Poseidon2 hash 10,000 times.)
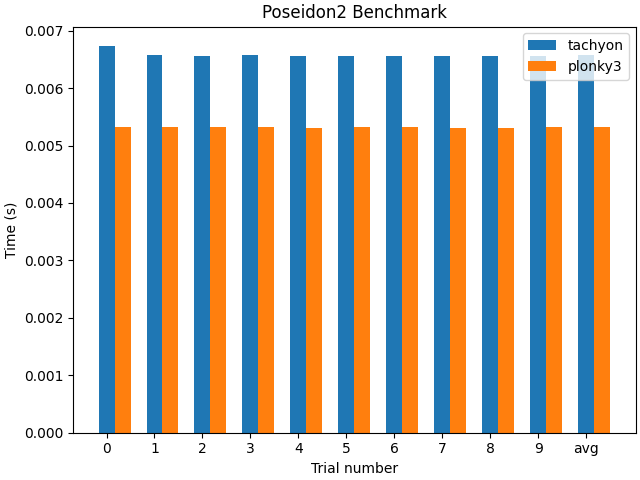
Fig 9. Poseidon2 Benchmark with clang-15.0.7
(This is the time taken to run the Poseidon2 hash 10,000 times.)
Though Tachyon introduced numerous improvements, its performance in all areas was not superior to Plonky3. For example, the Poseidon2 function itself is slower than Plonky3, and given the number of times the Poseidon2 hash is used, this is a notable drawback. We’ve been still figuring out why it happens.
Inefficient Thread Scheduling
Let’s take another look at the dynamic scheduling diagram shown earlier. Based on the profiling results, it may seem that CPU resources are being fully utilized. However, as illustrated in the Medium article on how FieldMerkleTree calculations work, to compute the hash of the leftmost node in the second layer, only its children in the first layer are needed. Currently, neither Plonky3 nor Kroma reflect these dependencies. When accelerating ZK proof generation on heterogeneous devices, expressing these dependencies is essential. Additionally, without such dependency relationships, all required memory may be loaded at once, creating inefficiencies from a memory management perspective.
Conclusion
Kroma is progressing steadily toward achieving Stage 1 as it transitions from a zkEVM to a zkVM. This transition, along with optimizations from Tachyon, aims to reduce costs in the challenge process and lower validator bond requirements, ultimately strengthening the Permissionless Validator System. As part of these efforts, the implementation of Plonky3’s FieldMerkleTree has enabled faster SP1 proof generation.
Recently, Plonky3 has also pursued CPU optimizations for greater speed, as noted in this update. Meanwhile, the Kroma team is designing Tachyon 2.0 to address not only the issues mentioned earlier but also various challenges across the ZK landscape. We look forward to sharing the results in an upcoming article.
About Kroma
As Asia’s leading Layer 2 solution built on the Superchain, Kroma is the first OP Stack rollup with an active fault proof system utilizing zkEVM.
Kroma will transition to a universal ZK Rollup once the generation of ZK proofs becomes more cost-efficient and faster — using its original modular ZK backend library, Tachyon.
Kroma plans to push for gamified web3 experience backed by its strengths in gaming, consumer applications, Asia market, and technical capabilities for true universal web3 adoption.
Follow us:
Website | Twitter | Discord | Warpcast | Github | Docs | Ecosystem | Brand Kit | Grant
Tachyon: Much Faster than Plonky3 was originally published in Kroma on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.