Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.

Increasing Ingress Message Throughput
By Kamil Popielarz and Yvonne-Anne Pignolet
In this 3-part series, we will unveil the technical achievements that will enable significant data handling improvements for applications running on the Internet Computer Protocol (ICP).
This upgrade refers to the Stellarator milestone of the ICP roadmap, which is now being rolled out across the network. Stellarator is a breakthrough in on-chain data storage and throughput, enabling each subnet to host over 1TB of memory per subnet and to upload data more quickly, unlocking opportunities for data-rich applications previously limited by storage and throughput constraints.
This advancement allows developers to build sophisticated applications requiring large-scale data processing, bringing a new level of utility to blockchain technology.
For the last installment of this series, Kamil Popielarz and Yvonne-Anne Pignolet will share the latest on increasing ingress message throughput on the Internet Computer. If you missed the previous parts of this series, you can find them here and here.
Increasing Ingress Message Throughput
If you’re like us, then waiting for data to be uploaded to a dapp is not your favorite pastime. Therefore, we are thrilled to announce that the Network Nervous System (NNS) is rolling out an optimization of the Internet Computer Protocol to improve the consensus throughput.
These protocol changes reduce the bandwidth consumption and time necessary to disseminate blocks while maintaining ICP’s security properties. As a consequence, users will spend more time enjoying the interactions with ICP dapps more swiftly.
Background
The Internet Computer Protocol coordinates its network nodes to provide a decentralized computing service even when some nodes deviate from the protocol.
As you know, ICP can host arbitrary applications combining code and data, known as canisters. Canisters can process ingress messages submitted by users as well as interact with other canisters by exchanging and executing messages.
Instead of replicating each canister’s execution on all nodes, the network’s nodes are partitioned into shards, called subnets. Every subnet employs a robust consensus protocol to ensure the consistent execution and state of the canisters hosted on its nodes.
The consensus protocol is responsible for the creation and validation of blocks, each containing a set of canister messages. After agreeing on the order and content of these blocks, the nodes can execute the corresponding canister code in a deterministic and consistent manner, preserving the integrity of the computing service.
The block payload contains ingress messages users submitted to trigger replicated canister calls. Upon receiving an ingress message from a user, the node performs a series of checks (e.g., signature, size, expiry). If these checks are successful, the node then adds the message to its ingress pool and broadcasts the message to the other nodes in the subnet using ICP’s peer-to-peer (P2P) protocol.
When it’s a node’s turn to create a block proposal, the node includes a set of ingress messages from its ingress pool. Subsequently, the node broadcasts this proposal to its peers.
However, since most peers already possess the majority of these ingress messages in their local pools, this process wastes bandwidth.
Another drawback of this approach is the fact that it takes much more time to send a proposal with let’s say 1000 messages of 4KB each instead of a proposal with 1000 hashes to all peers.
Consider the case when replicas have the recommended minimum bandwidth of 300Mbit/s, then broadcasting a block proposal with 4MB payload to all peers in a subnet with 13 nodes should take: 4MB * (13–1) / 300Mbit/s = 1.28s. With hashes of less than 50 bytes each, the same proposal can be delivered to all nodes more than 800 times faster. For larger subnets, these differences accumulate and thus matter even more.
Optimization
To reduce proposal delivery time and bandwidth consumptions, the protocol has been improved to let nodes include references (hashes) to ingress messages in the blocks instead of the full messages. Since nodes broadcast ingress messages with the P2P protocol anyway, replicas should be able to reconstruct block proposals by retrieving all ingress messages from their respective Ingress Pools using the references.
However, some ingress messages may be missing in a node’s local ingress pool. This can happen due to bad networking conditions, pools being full, nodes crashing or malicious node behavior. Nodes need to have all ingress messages of a proposal to be able to validate and/or execute a proposal. To get missing ingress messages, nodes can request the messages they don’t have yet from the peers who advertise the proposal.
To increase the chance that all the ingress messages are present in all peers’ ingress pools before a block containing their hashes is proposed, a few aspects of the ingress pool implementation was changed.
First of all, nodes now send ingress messages to peers directly, instead of adverts for them and waiting for the peers to request them. This saves at least one roundtrip, thus making broadcasting of ingress messages to peers faster.
Moreover, the management of the ingress pool size was refined. Up until now there were global bounds on the number of messages and on the total size they can occupy. If these bounds were exceeded, a node would reject any ingress messages broadcast by peers.
As a consequence, under a very heavy load, nodes on a single subnet may have ended up with mutually almost disjoint ingress pools. In this case, for each block proposal, all nodes would have to request all messages from the block maker, increasing the latency and decreasing the throughput.
To combat this issue, the global bounds were replaced with per-peer bounds. As of now, a node will accept ingress messages from a peer as long as there is still space for that peer in the ingress pool.
Since at any given time an honest replica will broadcast ingress messages up to the per-peer bounds, we can expect with high confidence that nodes on the same subnet will have highly intersecting ingress pools, even under heavy load.
To minimize changes to the overall protocol, a new component was added between P2P and Consensus, responsible for stripping ingress messages from proposals on the sender side and adding them back on the receiver side. The rest of the P2P and consensus logic remains unchanged.
Performance Evaluation
To illustrate the optimizations’ impact, we conducted experiments in testnet subnets with 13 nodes and imposing 300ms RTT between nodes, limiting the bandwidth to 300 Mbps.
The experiments show that with many small (roughly 4KB) messages the throughput increases from 2MB/s to 6MB/s.
Similarly, in the experiments where we send big (slightly below 2MB) messages, the throughput also increases from 2MB/s to 7MB/s.
Note that in the experiments we only focused on the consensus throughput and the canisters we sent the messages to didn’t do any meaningful work.
The figures below show what the throughput was during aforementioned experiments.
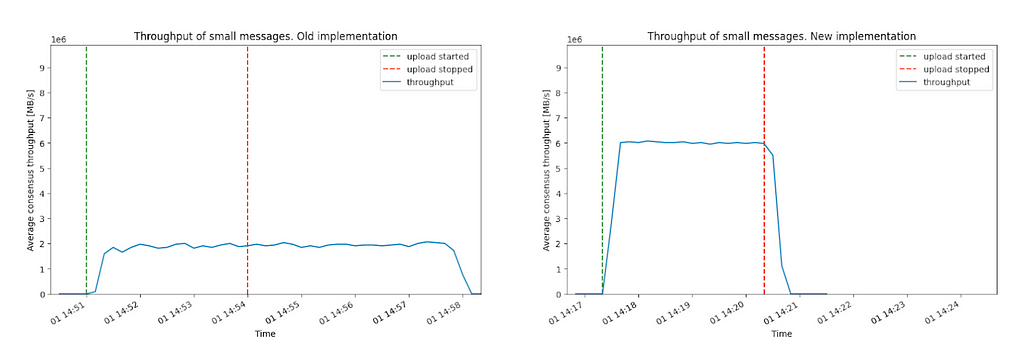
Figure 1: Throughput of small messages. The current implementation can sustain roughly 2MB/s of messages of size 4KB each, whereas the new implementation can sustain roughly 6MB/s of messages of size 4KB. Notice that in the old implementation, the subnet needs additional three minutes to process the data.
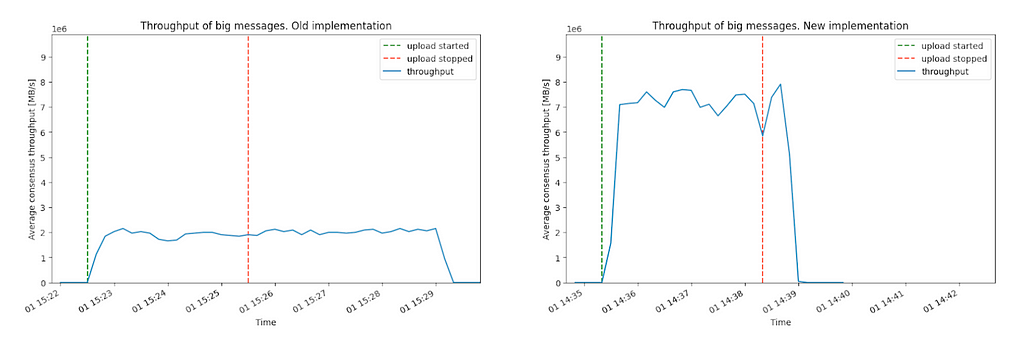
Figure 2: Baseline throughput of big messages. The current implementation can sustain 2MB/s of messages of size 2MB, whereas the new implementation can sustain around 7MB/s of messages of size 2MB. Notice that in the old implementation, the subnet needs additional three minutes to process the data.
We also ran experiments which demonstrate that the performance for nodes joining subnets (catching up) and node failures as well as for subnets with many canisters or many nodes is at least as good as before (and in many cases much better).
Conclusion
These protocol changes improve the user experience of the Internet Computer, laying the basis for further changes to allow processing more and larger messages.
The changes have been enabled on certain mainnet subnets already. On these you can experience yourself that the benefits also apply for real networking conditions and varying load, not just small experiments with synthetic traffic patterns.
Please let us know your feedback. You can always share your thoughts on the DFINITY Developers X channel and on the Developer Forum, and stay tuned for more Tech Roadmap updates coming up.
A Journey into Stellarator: Part 3 was originally published in The Internet Computer Review on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.