Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.

Data Persistence on the Internet Computer
By Stefan Schneider
In this 3-part series, we will unveil the technical achievements that will enable significant data handling improvements for applications running on the Internet Computer Protocol (ICP).
This upgrade refers to the Stellarator milestone of the ICP roadmap, which is now being rolled out across the network. Stellarator is a breakthrough in on-chain data storage, enabling each subnet to host over 1TB of memory per subnet, unlocking opportunities for data-rich applications previously limited by storage constraints.
This advancement allows developers to build sophisticated applications requiring large-scale data processing, bringing a new level of utility to blockchain technology.
Without further ado, let’s start this series by looking at how ICP stores data now, with the Stellarator update.
Data Persistence on the Internet Computer
This blog post gives an overview over how storage works on the replica machines of the Internet Computer with a particular focus on recent changes introducing log-structured merge trees (LSMT) based storage, which, among others, enables more replicated storage on Internet Computer subnets and allows them to better handle heavy workloads.
The Internet Computer consists of subnets, virtual machines identically replicated across 13–40 replica machines. Each of these replicas is responsible to execute all messages to canisters on that subnet, as well as store all canister data. All replicas therefore have the entire, and same, state of the subnet.
Developers can deploy canisters to the Internet Computer. Canisters are similar to smart contracts on other blockchains but can do more general computations and store orders of magnitude more data than smart contracts on other chains.
The data held by canisters needs to ultimately be stored on some physical hardware. A subnet on the Internet Computer can store up to 1TB of canister data, thanks to the recent introduction of the LSMT based storage layer and many other optimizations and improvements.
The majority of a canister’s data is stored either in its heap memory (at the time of writing up to 4GB) or its stable memory (at the time of writing up to 500GB). There are also other forms of data associated with a canister, such as the canister code, messages in flight, and assorted information such as the list of controllers and the cycle balance.
The storage layer of ICP bridges the gap between the canister’s storage, such as heap and stable memory, and the underlying replica machine’s storage hardware, such as its disks and RAM.
As part of the Stellarator milestone, the storage layer underwent an extensive redesign and reimplementation to set ICP up for future scalability challenges and fixing the most important scalability bottlenecks of the old storage layer. All the related changes were recently completed and the Internet Computer has now been running the new storage layer implementation for a couple months.
The remainder of this blog post describes the redesign of the storage layer as a log-structured merge tree data structure. The redesign aims to lift storage related bottlenecks, and opens the door for a better experience for both users and developers of storage-heavy canisters.
Most notably for users of ICP, this work enabled the recent bump to 1TB of replicated state on a single subnet. In addition, the redesign also allows the Internet Computer to better handle canisters that write significant amounts of data.
Checkpoints
In general, the storage layer of the Internet Computer uses a combination of persistent storage on disk and ephemeral storage in RAM. A key concept of how the Internet Computer stores its state are so called checkpoints. A checkpoint is a logical point in time where the entire subnet state is stored on disk. Checkpoints are created every 500 blocks, or every couple of minutes, in a deterministic manner, meaning all replicas will write the same checkpoint at the same heights. A checkpoint is stored on the disks of each replica node in the form of a file directory and the directory structure looks something like this (heavily simplified):
<checkpoint_height>
canisters
<canister_id_1>
heap_memory
stable_memory
message_queue
<canister_id_2>
heap_memory
stable_memory
message_queue
…
In this structure, each canister is stored in its own subdirectory, and each canister directory contains separate files for heap memory, stable memory, and other information such as messages in flight.
There are several reasons why data is persisted to disk in the form of checkpoints.
1. Data Persistence: A replica machine might restart at any point. There could be a software bug in the replica code, or the hardware might be faulty, or there might be a problem with the power supply at a data center. When this happens the latest checkpoint can be loaded back.
Note that even though checkpoints are only created every 500 rounds, a replica can recreate states for non-checkpoint height. A replica only needs the latest checkpoint plus all finalized blocks between the checkpoint and the latest state. As all executions are deterministic, these blocks can be replayed and the recreated state is guaranteed to be exactly the same. The necessary blocks are either persisted to disk separately from the checkpoint or fetched from other replicas.
2. Synchronization: All (replicated) messages are executed by all replicas. As a consequence, for any given height h, all replicas are supposed to have the same state. The protocol prevents divergence (i.e. when some honest replicas end up with a different state from the consensus state) by first hashing the state and then threshold signing the resulting hash. Only if at least ⅔ (more precisely 2f + 1) of replicas agree on the same hash, such a threshold signature can be created and the subnet can move on.
However, subnets of the Internet Computer can have large states. At the time of writing this article the limit is 1TB. It would be infeasible to hash that much data after every block while maintaining up to 2.5 blocks per second as the fastest subnets on the Internet Computer currently do. Because of this, the Internet Computer only hashes selected parts of the state for non-checkpoint heights — for example, including some basic information on each canister, recent responses to ingress messages, and XNet messages addressed at other subnets.
For checkpoints the protocol hashes the entire state to obtain a data structure called manifest. This manifest is computed by hashing all files in the checkpoint directory and contains hashes of all the individual files chunked up into 1MB chunks. At the end of manifest computation a root hash of the manifest, covering all the individual hashes in the manifest, is computed which will then be threshold signed by the subnets. Computing the manifest can take tens of seconds, but that work only needs to happen every 500 blocks and is performed in the background and in parallel to canister execution.
3. State Sync: The Internet Computer allows changes to subnet topology via NNS proposals. When a replica node joins a subnet, it can fetch the most recent checkpoint from other replica nodes. Recall that checkpoints are a collection of files. So after verifying the manifest using its root hash and the subnet’s threshold signature on it, the state sync protocol can obtain the files chunk by chunk while comparing the hashes of the obtained chunks to the ones in the manifest. If all checks succeed the replica can conclude that the obtained state corresponds to the agreed-upon state of the respective subnet at the checkpoint height. State sync can also trigger if a replica falls behind for other reasons, and the gap to the healthy state is too large to catch up with pure replaying of blocks.
4. Large State Size: Currently, the maximum state size is 1TB, while the replica node machines have 512GB of RAM. It is therefore not possible for the entire state to be loaded to RAM. The Internet Computer uses the RAM mostly to hold recent data that has not been persisted yet, and for caching data to improve performance.
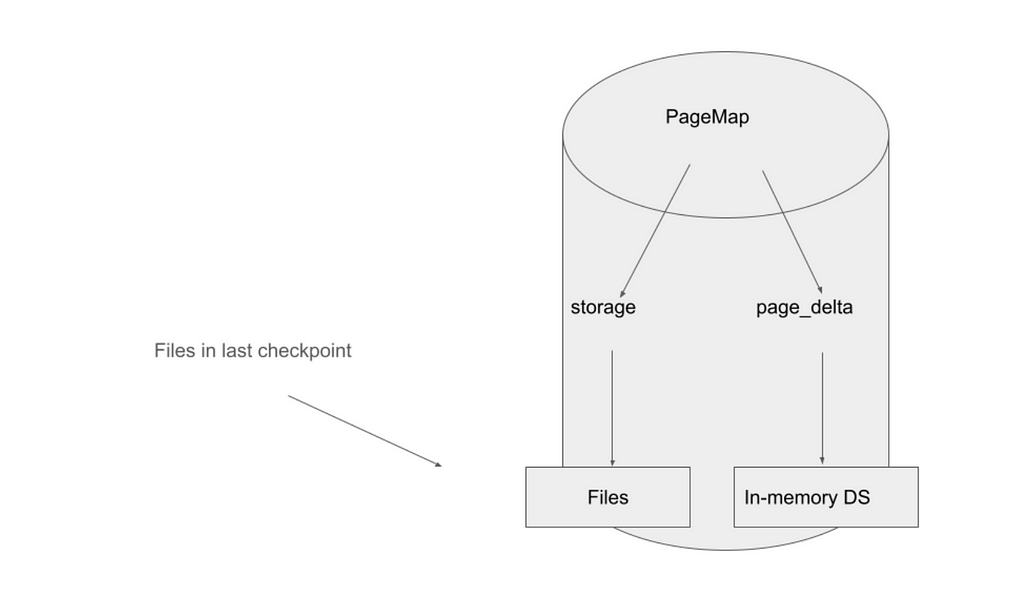
PageMap and Non-Checkpoint Heights
As checkpoints are only created every 500 blocks, ICP needs to make storage available to the canisters differently for non-checkpoint heights. The basic idea that the storage layer follows for this is that this data is stored as a combination of the last checkpoint, on disk, and any changes since then stored in RAM.
PageMap is the replica’s implementation of this for the largest parts of a subnet’s state. The vast majority of a subnet’s state is canister state, particularly a canister’s heap and stable memory.
Currently a canister can have up to 4GB of heap memory, 500GB of stable memory, and the total subnet state is limited to 1TB, but all of these limits might change in the future. Both memories can be read by replicated (update) and non-replicated (query) canister calls, and can be modified by replicated calls.
The PageMap data structure is designed to allow efficient reads and writes to a memory, as well as support efficient writing of checkpoints. A particular goal is that performance is independent of the total size of the memory. Note that the name PageMap derives from the fact that the granularity of all reads and writes is in pages of 4KB, which is the same page size the underlying operating system uses.
A PageMap stores the state in two layers. The first layer, called storage, is the files from the last checkpoint. They represent the state at the last checkpoint height. The second layer, the page delta, represents all changes since that checkpoint and is stored in RAM.
When reading from a PageMap, the returned data is either fetched from the page delta, or read from the checkpoint files if missing. Writing to a PageMap is done by modifying the page delta with the new data.
Checkpointing Lifecycle
The storage layer’s main task is to write checkpoints to disk and keep all PageMaps up to date. When new checkpoints are written, all page deltas are flushed to disk, thus updating the storage part of all PageMaps.
To guarantee that all data is preserved, the replica needs to keep the latest checkpoint that has been threshold signed at all times. This means it is not possible to simply overwrite the old checkpoint files, as any such modification would alter the previous checkpoint before the new checkpoint can be completely written, which would risk losing data. At the same time, writing a full checkpoint to disk (up to 1TB) every 500 rounds would be prohibitively expensive. Instead, creating a new checkpoint consists of 3 basic steps:
- “Copy” the old checkpoint to a temporary folder, called the tip.
- Modify the tip to represent the data of the new checkpoint.
- Rename the tip to the new checkpoint directory (so the new checkpoint is created atomically).
The first step is potentially the most expensive step, as the larger the state, the longer it takes to copy files , and therefore the larger the checkpoint files.
However, this is where the file format of checkpoints and log-structured merge trees come in. By using LSMT, this step is cheap and does not scale with the state size. In contrast, before the LSMT redesign of the storage layer, this step was slow and unpredictable.
Log-Structured Merge Trees
Log-structured merge trees (LSMT) are a widely used data structure, particularly popular for databases. On the Internet Computer, they are used as the basis for the storage part of PageMaps. A particular problem it can solve is that it simplifies the “copy” step of the checkpointing lifecycle, as all files are written once, and never modified.
With LSMT, modifications to the (logical) state are done by writing an additional overlay file. To read the value of a page, the algorithm then first checks the most recently written overlay file if that page is present in the file. If it is, the value of the page is read from that overlay file. Otherwise, the next older overlay file is checked. In the implementation used by the Internet Computer, if a page is not present in any overlay file, it is read as all zeros.
The image below shows a set of three overlay files representing the state of a canister and the vertical arrows show different reads to the data and the file that the data is ultimately read from.
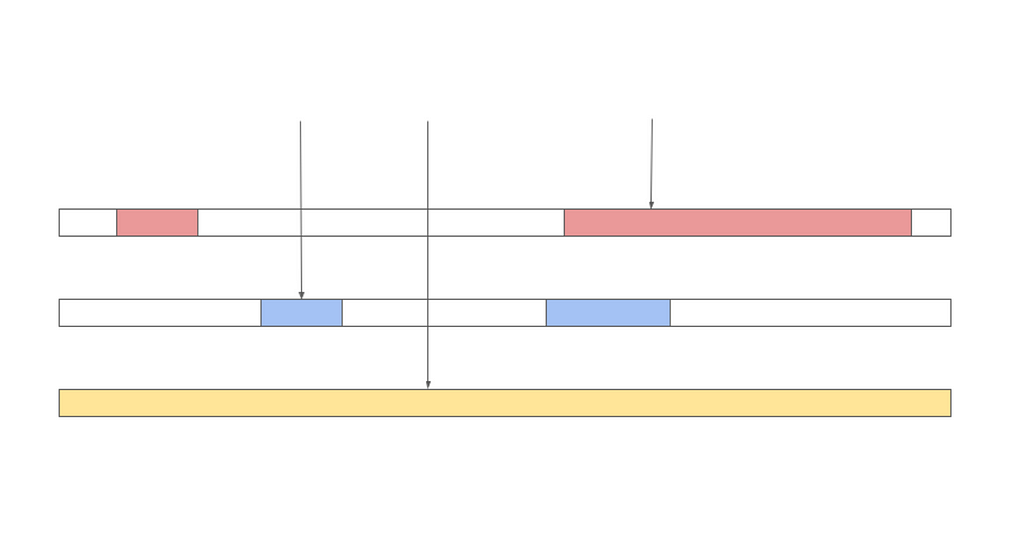
The checkpointing life cycle with LSMT then looks like this:
- Hardlink all files from the previous checkpoint to a temporary folder, called the tip.
- Write new overlay files containing all changes since the last checkpoint.
- Rename the tip to the new checkpoint directory (for atomicity).
The key is that each overlay file is written exactly once, and never modified. This makes it safe to have multiple checkpoints on disk with some files shared between them via hardlinks. Note that if the checkpointing life cycle attempted to modify any files, this same process would not work. If a file has multiple hardlinks, modifying any of them changes the data in all of them. This would tamper with previous, already certified, checkpoints.
Log-structured merge trees may store multiple versions of the same data range. This leads to a storage overhead defined as the ratio of the sizes of all overlay files over the logical size of the data represented. Furthermore, the data might be spread over several files.
As the storage overhead or number of overlay files grows, the storage layer implementation will schedule a merge. A merge reorganizes data by taking a set of overlay files and replacing them with a single file containing only the latest version of each piece of data. Merges are scheduled for PageMaps with a particularly high storage overhead or number of files and are performed in the background so that they do not interfere with the execution of canister messages.
Previous Design using Reflinks
The original storage layer of the Internet Computer did not rely on LSMT. From the Internet Computer’s genesis in 2021 until 2024 the storage layer relied heavily on reflinking instead.
Reflinking, sometimes called copy-on-write, is a file system operation to copy a file. It is supported by some file systems. The replicas of the Internet Computer use the XFS file system, which does support it. Reflinking differs from a normal file copy in that it does not duplicate the entire file contents. Instead, the file system remembers which data is shared between the original and the new file. Reflinking also differs from hardlinking in that both files can be modified independently from each other.
In this old design of the storage layer, the checkpointing life cycle worked as follows:
- Reflink all files from the previous checkpoint to a temporary folder, called the tip.
- Modify the files in the tip to based on all changes since the last checkpoint.
- Rename the tip to the new checkpoint directory.
A potential advantage was that a PageMap would be represented in a checkpoint by a single file, avoiding storage overhead. However, to modify the file for a new checkpoint height, the corresponding file from the previous checkpoint would need to be reflinked as opposed to hardlinked.
Advantages of LSMT over Reflinks
In principle, reflinking promises the speed of hardlinking and the usability of copying. Unfortunately, as the data needs of the Internet Computer increased, both in terms of I/O throughput and total amount of data, reflinks turned out to be a performance bottleneck for several reasons.
1. Slow Reflink Speed: The time it takes to reflink a file can vary a lot. It can take just a few seconds in certain cases, but in experiments we also observed up to 10 hours to reflink 370GB. In the context of the Internet Computer’s old checkpointing logic, a 10 hour reflink step would have caused a 10 hour stall of the entire subnet.
Bad reflink speeds are triggered by fragmentation. Internally, the XFS file system maintains data structures that map parts of files to actual data blocks on disk. Fragmentation, and slow reflinking speeds, occur when these data structures become expensive to traverse.
Fragmentation can be particularly triggered by a sequence of heavily writing to a file, then reflinking it, heavily writing to one of the copies, reflinking it again, etc. Unfortunately, given the checkpointing workflow on the Internet Computer, a heavily used canister can trigger exactly this behavior.
On the other hand, hardlinks have consistent performance, independent of any fragmentation issues.
Before introducing log-structured merge trees, a number of stop-gap mitigations were implemented. These included manually defragmenting files by reading them and writing them back, and writing files in larger contiguous sections. Both of these methods come at the cost of large write amplification, and could still result in stalls of up to 30 minutes.
2. Maximum State Size: Beyond very long reflinking time due to excessive fragmentation, even for moderate levels of fragmentation the reflinking time scales with the total amount of data stored by the subnet. With the previous implementation of the storage layer, the Internet Computer imposed a limit of 700GB stored per subnet. This number is largely a function of how much moderately fragmented data can be reflinked within at most 20–30 seconds.
With hardlinks, the checkpointing time does not scale with the size of the data in the same way, lifting this bottleneck.
3. Poor Multithreading: One of the goals of the checkpointing logic is to avoid synchronous operations where possible, where canister executions are stalled for the duration of checkpointing. Naturally, a consideration was whether reflinking, even if slow, could be performed in the background while execution continues. Unfortunately, the experience was that it was not possible to reflink and read from a file at the same time. As such, reflinking in parallel to execution would simply result in slow execution.
In the new design of the storage layer, hardlinks are performed in parallel to execution and they do not slow each other down.
4. Caching: As described above, reading from a canister’s memory results in a combination of reading data from RAM, and reading data from the underlying checkpoint files. Repeatedly reading from the same file does typically not result in having to read the data multiple times from the actual hard drive or SSD. Instead, such data is cached by the operating system. Unfortunately, reflinks interfere with caching, in that first reflinking a file and then reading from the new copy does not make use of the cache. As a result, on the Internet Computer one would see large (and slow) spikes in disk reads right after a checkpoint had been written, as all reads would switch over to the new files. Furthermore, manifest computations, i.e. computing the hashes of all checkpoint files for the purpose of consensus, also heavily benefits from better caching.
In contrast, when hardlinking files, all caches are preserved. Any data that has been recently read or written, even if it happened in previous checkpoint intervals, will still be cached and therefore fast to retrieve.
Results
The LSMT storage layer was rolled out to all subnets of the Internet Computer over several weeks in Q2 2024. The graphs below show metrics around the time of the replica code upgrade, with a red vertical line denoting when the LSMT storage layer was enabled.
The first graph shows the checkpointing time of the w4rem subnet, which hosts the canisters for the bitcoin integration. Compared to many other subnets, the bitcoin subnet hosts canisters with a write-heavy workload for both their heap and stable memory. As a consequence, fragmentation was a particular concern on that subnet.
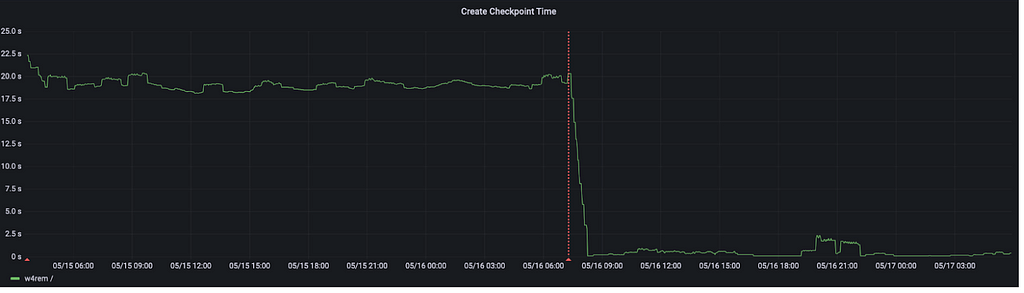
As the metrics show, the checkpointing time drops from over 20 seconds to just 1–2 seconds. This is mainly due to eliminating the reflinking step, which occupied the vast majority of the 20 seconds.
The benefit for the users of the bitcoin canisters is a snappier response. During checkpointing, a subnet does not process any update calls or replicated queries. If a user sent an update call or replicated query to the bitcoin canister right when checkpointing started, it took at least 20 seconds to receive a response. Inconsistent response times like this are essentially eliminated with the LSMT storage layer.
The second graph shows the finalization rate on the k44fs subnet. The finalization rate, or block rate, is the number of blocks the subnet produces per second.
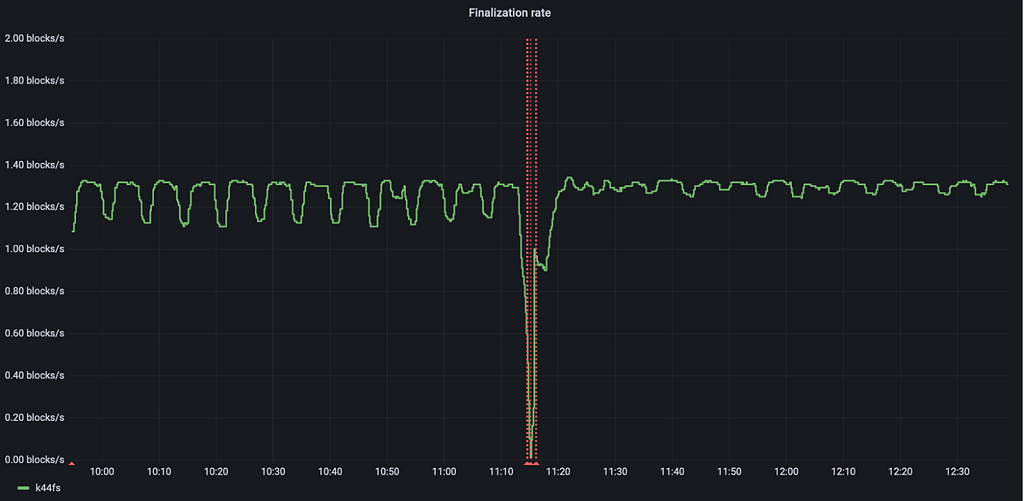
The Internet Computer limits the number of instructions executed per round to a value that roughly corresponds to the amount of work it can do in one second, so that the finalization rate can stay above 1 block per second.
Before the upgrade to the LSMT storage layer, the finalization rate had regular dips which correspond exactly to checkpointing. Checkpoints affect the finalization rate for two main reasons. The first is the time it takes to create the checkpoint, during which no blocks are executed. The impact of this aspect is reduced after the upgrade because checkpointing times are generally much smaller. The second reason is better caching behavior of the LSMT storage layer. In particular, the reflinking step in the old storage layer implementation caused invalidation of caches. So after checkpointing any canisters reading from their memory would cause the replica to fetch that data from the disks, which is orders of magnitude slower than if the same data is available in a cache stored in RAM. This issue is not present in the new LSMT storage layer.
As the metrics show, the dips in finalization rate are considerably smaller after the upgrade, both because the checkpointing itself is faster as it no longer needs to do reflinking, and because the file caches are no longer invalidated.
For the users of the canisters on that subnet this means a quicker response time and increased throughput.
Conclusion
Redesigning the Internet Computer’s storage layer around the log-structured merge tree data structure was a crucial investment in the scalability and performance of the platform. Not only does it make possible some memory heavy workloads, it also allows the Internet Computer to offer larger states to canisters.
Canisters that operate on large data are particularly interesting in the context of artificial intelligence and running large language models onchain. Such canisters not only rely on a lot of data storage, they also heavily rely on I/O throughput.
Furthermore, it forms the basis of follow-up improvements such as making the Internet Computer more responsive by making better use of concurrency to take heavy workloads off of the critical path. The experience with the original storage layer showed that avoiding reflinking is crucial to achieve this and the LSMT data structure does this.
Did you enjoy this article? Share your thoughts on the DFINITY Developers X channel. Join us tomorrow for Part 2 of A Journey into Stellarator, with Luc Bläser on Enhanced Orthogonal Persistence.
A Journey into Stellarator: Part 1 was originally published in The Internet Computer Review on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.