Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
 Introduction
Introduction
Over the past decade, blockchains have risen to become the leading form of distributed ledger technology. Despite their current dominance, however, a growing number of projects are proposing alternative solutions to solve certain scalability issues inherent to blockchains. One of these proposed technologies is the DAG, or Directed Acyclic Graph, which has been promoted by a number of alternative layer 1s as a more efficient solution than traditional blockchains. However, there is still a lot of confusion in the web3 space about what exactly a DAG is and how it compares to existing blockchain technology. By clearly explaining how DAGs work and the ways they can be used within crypto applications, this research report aims to educate readers on alternative layer 1s which use DAG technology, while providing a framework to classify different uses of DAG technology and improving knowledge of how they operate.
What exactly does “DAG” mean?
The acronym “DAG” stands for Directed Acyclic Graph. For those unfamiliar with computer science concepts, this may be a mouthful, so we’ve broken down each term below:
- Directed: The data structure only moves in one direction
- Acyclic: The data structure cannot return to a previous state from the current state; it is “non-cyclical”
- Graph: When visualized, the data structure appears as an interconnected set of relationships between vertices
What exactly does a DAG structure look like? The best way to determine whether a data structure is a DAG or a blockchain is by checking how the data is ordered. Ordering refers to how we sequence transactions in time. Because our understanding of how time works is linear, we traditionally think about events occurring in a specific sequence. Humans typically all agree on a time, and we all agree events happen sequentially.
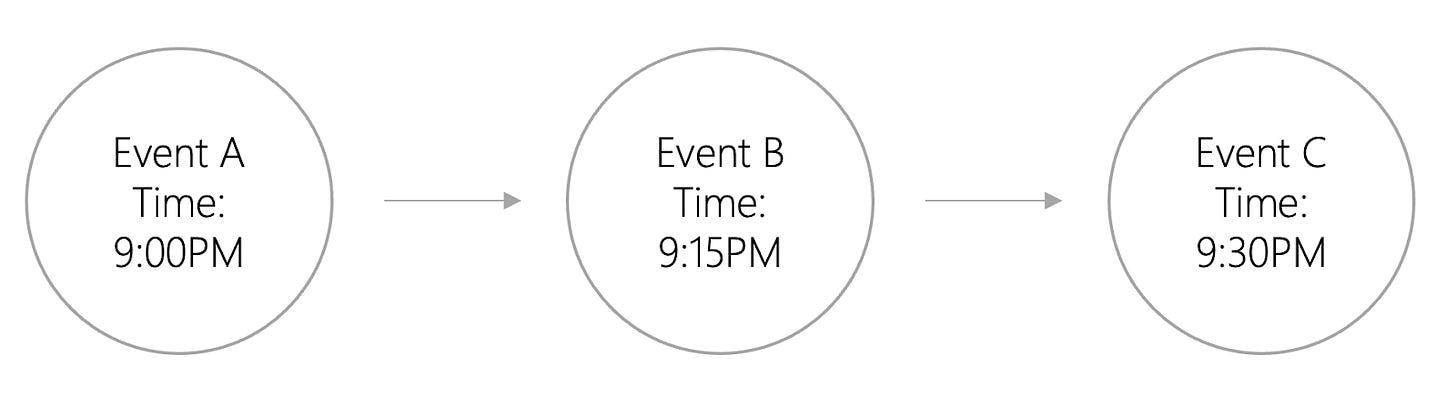
The above diagram is an example of “total ordering”. Events will always have an exact order based on which event occurred first. In a set of events that are totally-ordered, we know the exact total order of every one of the events. Using a total order, Event A comes first, then Event B, and then Event C. This is how events are recorded in a blockchain.
However, a total ordering of a distributed ledger may limit scalability in terms of throughput and latency. We may look to “partially order” the ledger to solve some of these issues. This is where the exact ordering of each event in relation to every other event is not known. Rather, only the order of related events is known. We aren't sure of the order of all events, but we can be sure about the order of events which rely upon one another.

For example, we can say we are certain that Event B happened before Event C. However, in a partially ordered system, we are not sure when Event A occurred. It could have before, after, or even between these events. Event A is unrelated to the other events.
Generally speaking, why would we want to know how these transactions are ordered? The purpose of ordering events is so we can figure out how one event caused another event to happen. Partial ordering has no concept of time, so how can we sequence events without struggling to figure out the times at which each event occured?
“Causal ordering” is the answer to this problem. Causal ordering is a partial order and does not take into account when the events occurred, but rather, it only takes into account the cause and effect relationship between events. If we can determine which events caused other events, we can order the events.

An example of causal ordering can be seen above. It may not be possible to figure out when these events exactly occured, as they have no timestamps. However, we can see that A caused B to happen, and that B caused C and E to happen. It can then be derived that A eventually led to D and F to occur. Because C caused D and E caused F, we can determine the causal order of C in relation to D and the causal order of E in relation to F. However, we do not need to determine the order of C in relation to E or F, or the order of E in relation to C or D. Not all events have causal relationships to each other and are only partially ordered, and that is okay because unrelated events do not need to be ordered in relation to one another.
By using causal ordering, we are no longer constrained to a “chain of events”-like structure, allowing us to build a DAG structure instead. Events which have nothing to do with one another do not need to be ordered at all. A distributed ledger that has causally-ordered transactions is structured as a DAG, while a totally-ordered ledger is structured as a blockchain. Because causal ordering allows certain transactions to skip sequencing entirely, a DAG-based ledger may offer a scalability advantage in terms of throughput and latency compared to a blockchain-based ledger.
Many layer 1s today tout DAG technology as a differentiating factor in their design, but not all of them use DAGs to enable causal ordering. Unfortunately, there is no existing framework to subdivide the DAG space. For the purpose of this paper, we will figure out what truly makes a DAG layer 1 and try to group relevant projects in two categories based on how their transactions are ordered. First, we discuss layer 1s which use DAGs to process their transactions, but whose ledgers are totally ordered. Then, we will cover layer 1s whose ledgers are causally-ordered and which use DAGs as the data structures in which they store events and transactions. It is important to differentiate between protocols which use a DAG-based ledger and protocols that use a DAG as part of their transaction processing, as the latter may not gain the same increase in transactional throughput.
Blockchains which use DAGsHow do certain totally-ordered blockchains use DAGs?
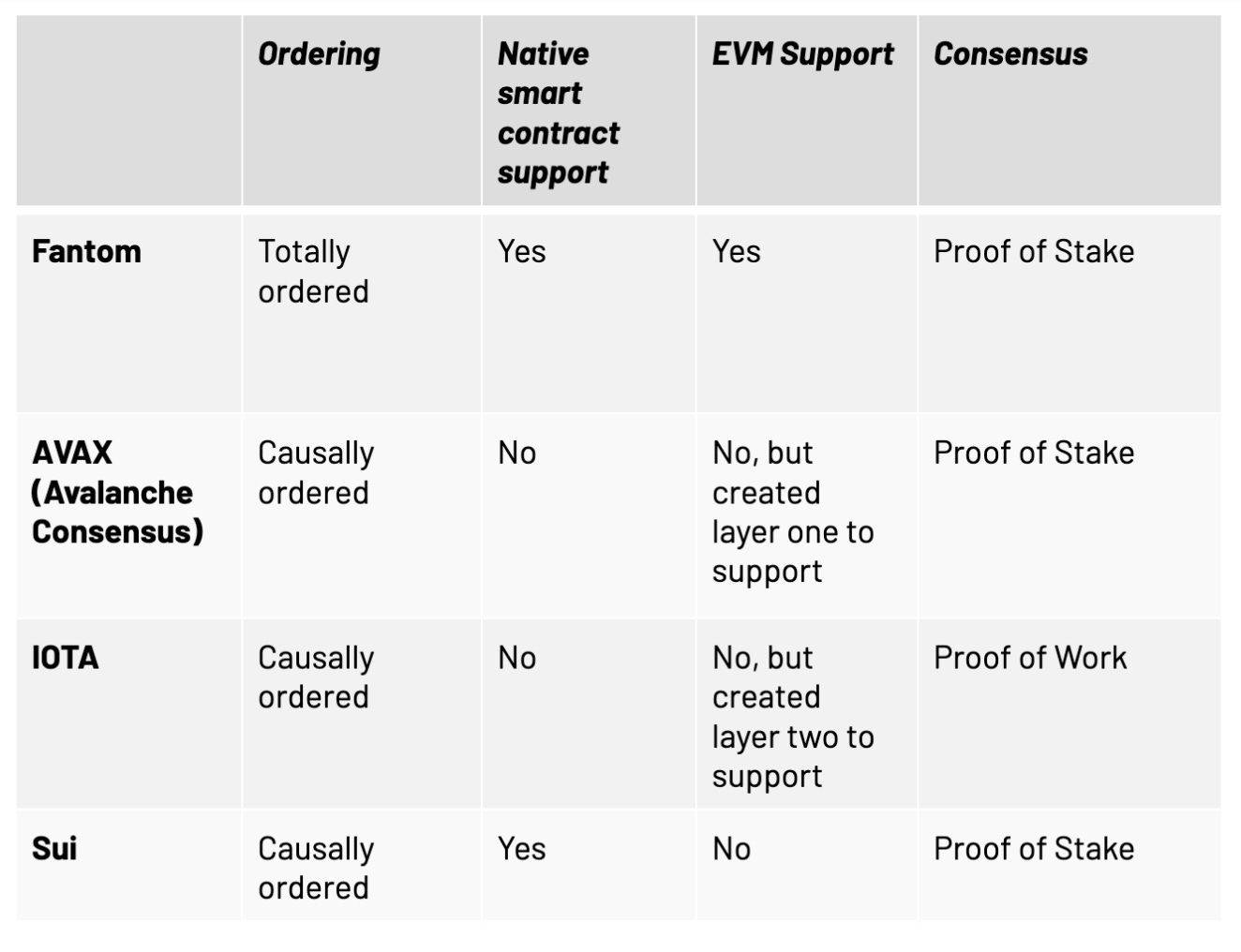
Fantom is an example of a blockchain that utilizes a DAG to speed up its consensus protocol while outputting the results in a traditional, totally-ordered blockchain structure. If a blockchain claims to be DAG-based, it is commonly the case that the layer 1 is using a DAG-based consensus mechanism rather than a DAG-based ledger.
Fantom: a gossip-based blockchain that uses DAG technology
Fantom’s consensus protocol, Lachesis, forms a DAG-based structure called the Opera Chain. The Opera Chain network is made up of nodes, which are computers running Fantom’s software. The building blocks of the Fantom’s consensus mechanism are called “event blocks”. Fantom’s concept of blocks is different from the term “blocks” as we commonly refer to them.
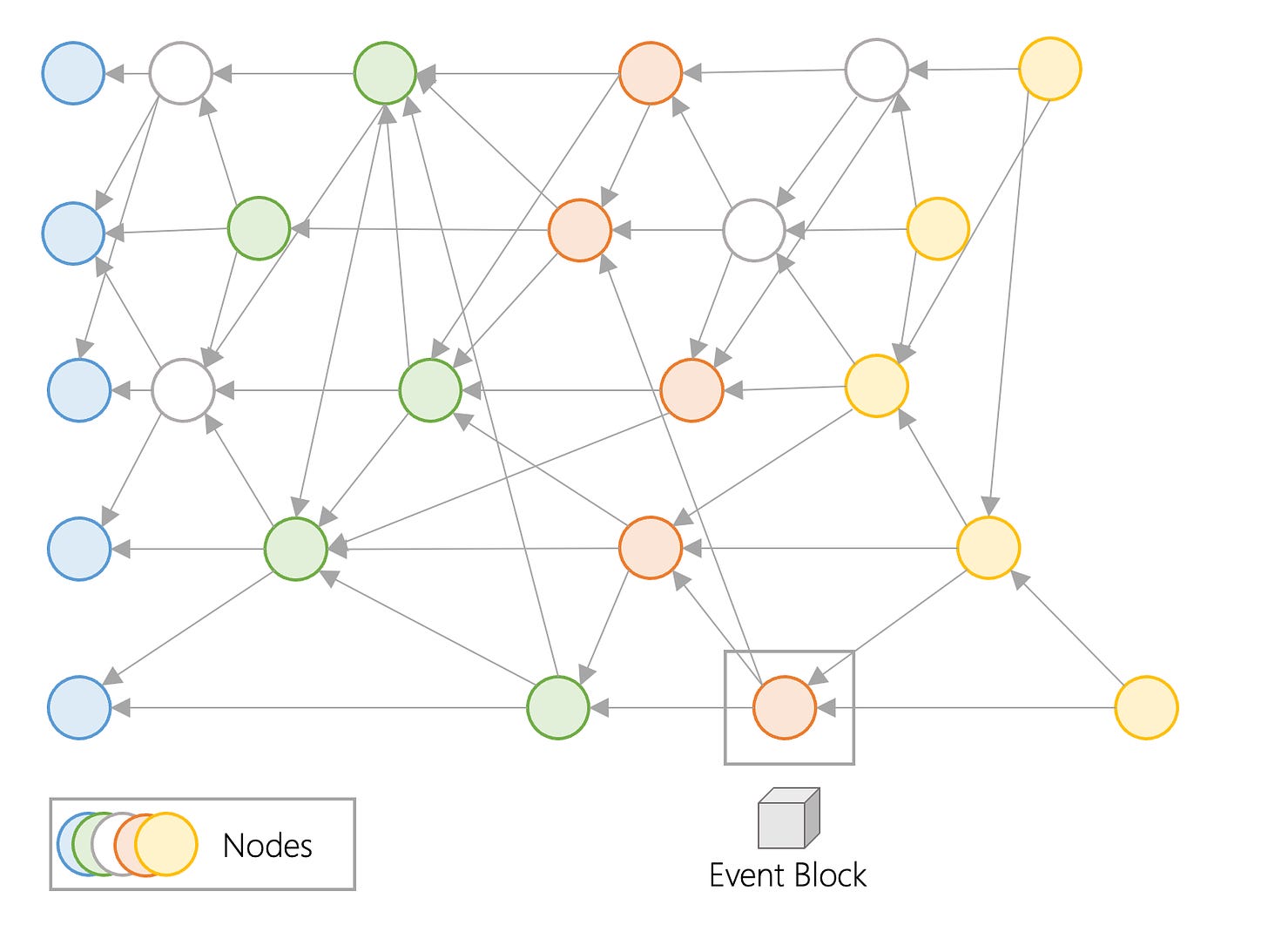
At a high level, nodes create event blocks, which form a DAG. Fantom uses a DAG of event blocks and generates a blockchain (a chain of confirmed blocks).
Fantom stores data in event blocks which contain financial, technical, and other information. Event blocks are data structures created by a single node to share transaction and user information with the rest of the network. In the picture above, we can see the DAG structure, with event blocks spawned by nodes represented as circles. It’s not represented above, but every node is producing event blocks. Every time nodes exchange transactions, they create a new shared event block. Event blocks are shared throughout the network. When one event block communicates to another, the event block that was communicated to stores the prior event block’s transactional information, which then creates a new event block. This information is then communicated to the next event block. Transactional information is hashed, and each event block contains a hashed value of one or more previous event blocks. This causes the data to be immutable, as it is not possible to modify or delete previous event blocks without changing their hashes.
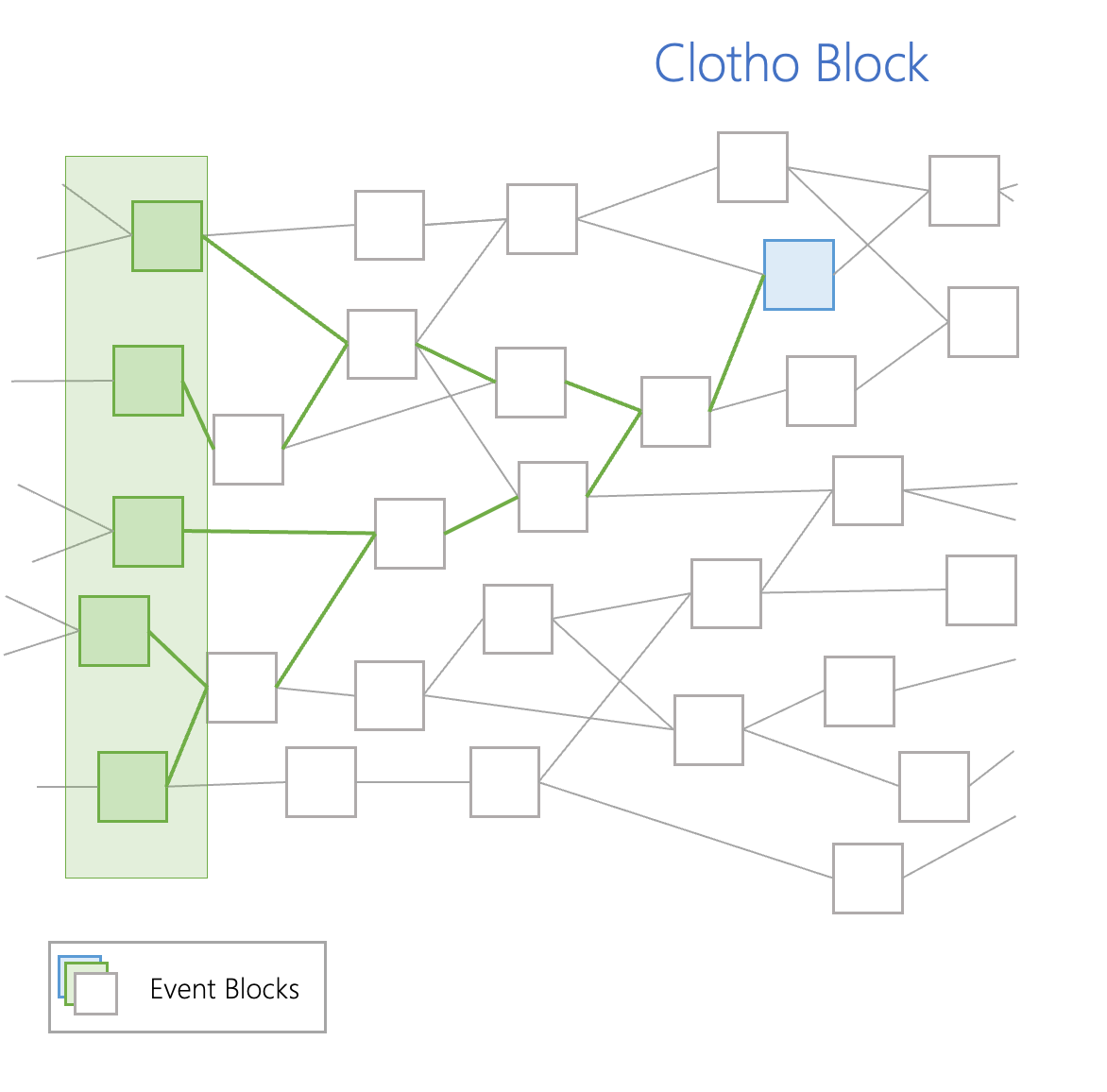
The green highlighted areas of the Opera Chain DAG are event blocks that communicate with one another until they find a single event block called a “Clotho” block (the blue block in the above graph). The Clotho block contains a “flag table,” which is a data structure that saves all the connection data between specific event blocks. To be considered a Clotho block, the Clotho must have a supra majority of more than ⅔ connections to a previous set event block. The Clotho Blocks communicate with other Clotho blocks in the DAG Structure, using the flag table data structure.
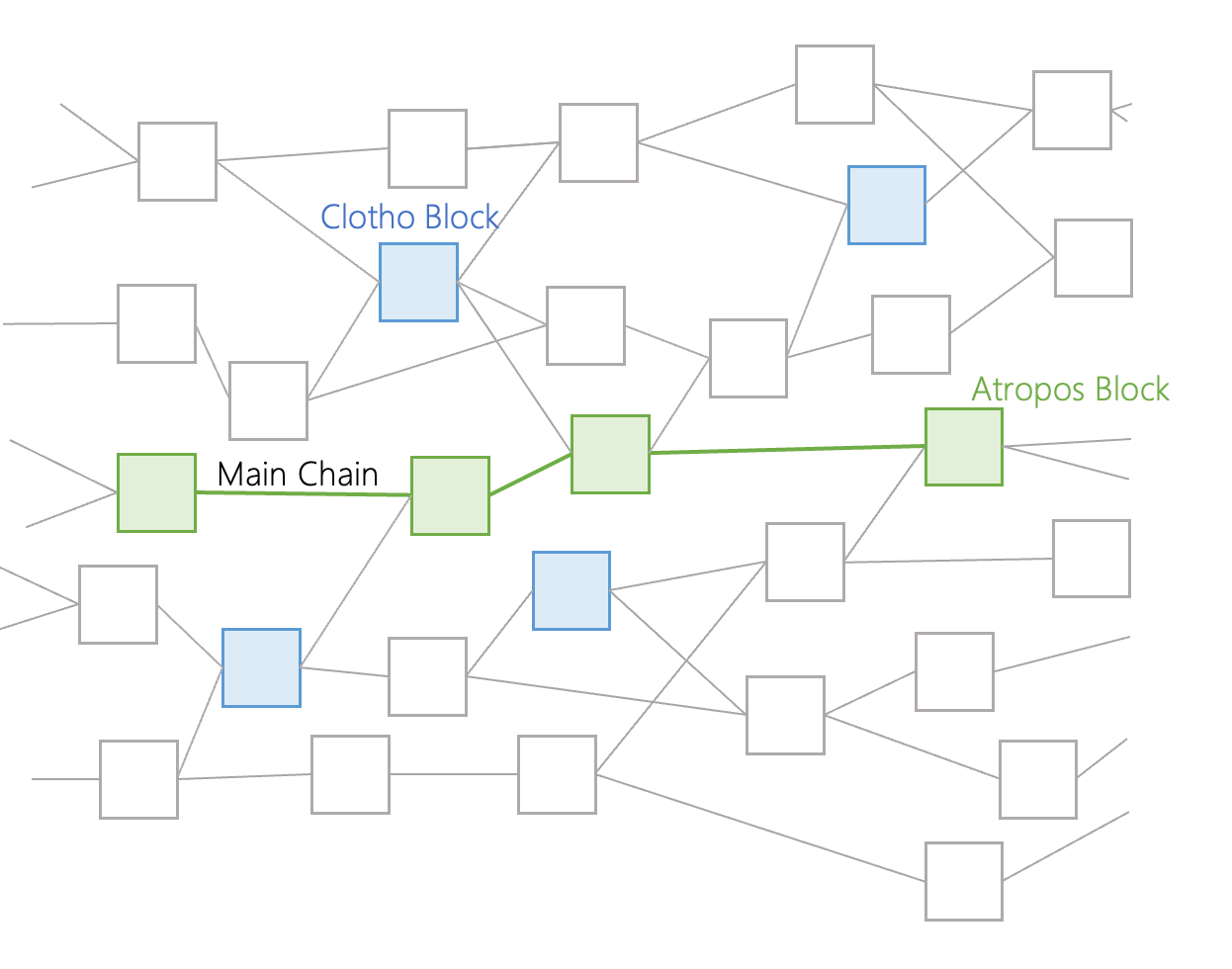
Based on the information provided from communicating between each other, Clotho Blocks come to a consensus to create another event block, called an “Atropos” block (green blocks in the above chart). Each Clotho block has a specific timestamp when it was created. If at least ⅔ of all nodes have the same time, the Clotho block becomes an Atropos block. These Atropos blocks are strung together to make up the “Main Chain.” The Main Chain can be viewed as a blockchain within the DAG structure. Each Atropos is connected to other Atropos blocks, sharing the information gathered from all other event blocks, which is gathered from the Clothos blocks.
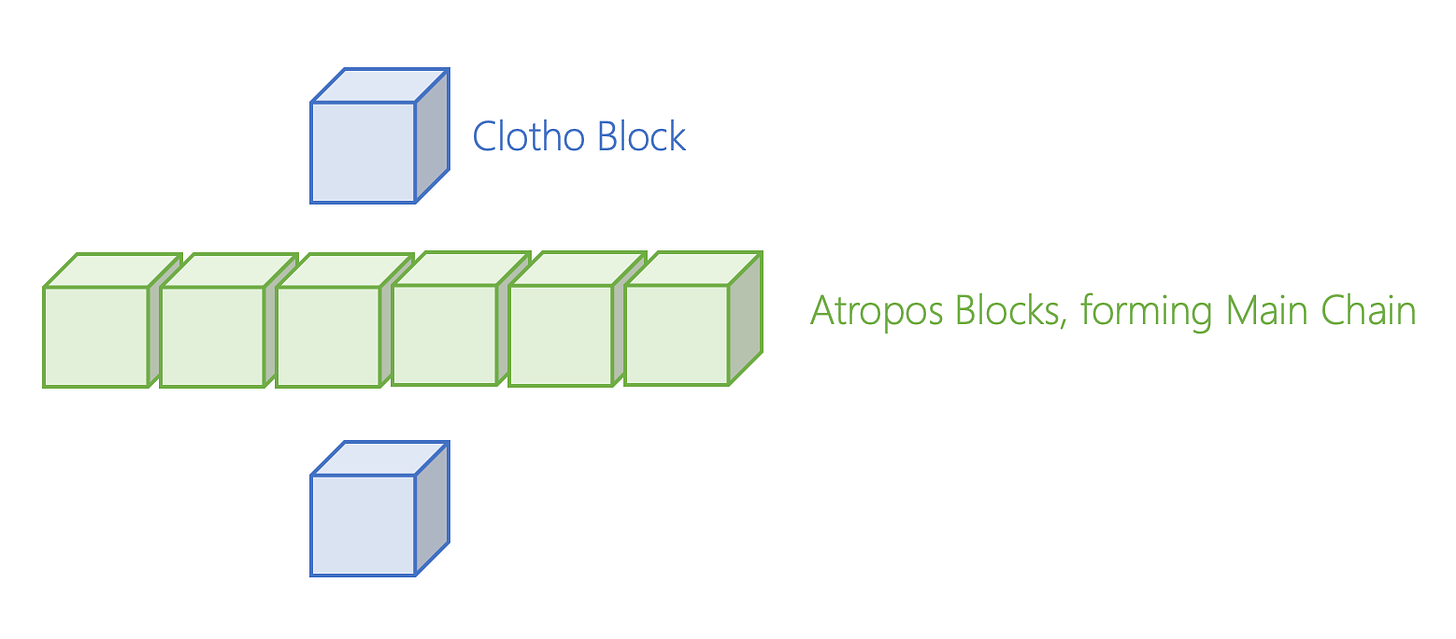
This Main Chain contains a total order of all the events. All participating nodes have a copy of the Main Chain, and can search for the historical position of its own blocks in the Lachesis consensus protocol. Nodes do not need to store all the information of every event block and can just reference the Main Chain. This leads to fast access to the ordering of the previous events.
It is important to understand that not having the correct recorded time of transactions and partially ordering transactions prevents most DAG protocols from incorporating smart contracts, since smart contracts typically require sequencing of all transactions which interact with them in order to operate properly. This can be seen with IOTA and Avalanche’s X-Chain. In contrast, the Opera Chain is constructed to allow for the correct time and ordering of transactions. However, while the Fantom Opera Chain does offer an increase in transaction throughput compared to Ethereum Mainnet, it may not offer the same latency and throughput as other causally-ordered DAGs. This is due to the Ethereum Virtual Machine (EVM), which Fantom’s Opera Chain uses, being a limiting factor in itself. Fantom’s Opera Chain does make it possible to remove some of this bottleneck by allowing the Cosmos SDK to be built on top of Lachesis instead of the EVM. In the future, Fantom plans to create the Fantom Virtual Machine (FVM), which should further improve scalability. Since Fantom’s rise, new Layer 2 scaling solutions have been built upon Ethereum. Fantom’s EVM layer is losing relevance in this wave of new scaling solutions, and it makes sense for Fantom to focus on the FVM to exceed the limits of what is currently possible with its existing solutions.
DAGs that have a causally ordered outputWhen most people say "DAG," what they're actually referring to is a causally-ordered distributed ledger. How do these DAGs work, and what differentiates them from their totally-ordered counterparts? Avalanche’s X-Chain, IOTA, and Sui are examples of distributed ledgers which have a causal order.
Avalanche X-Chain, a UTXO-based DAG.
Bitcoin introduced the unspent transaction output (UTXO) model to record the state of transfers between wallets. Each UTXO is a chain of ownership where the current owner signs the transaction to transfer the UTXO ownership to the address of the new holder. In the context of UTXO, Bitcoin would best be described as a blockchain, while Avalanche’s X-Chain would best be described as a DAG. The X-Chain uses the Avalanche consensus protocol, which is causally-ordered. If you send someone AVAX, you are using the X-Chain. To understand how Avalanche’s DAG works, the first step is understanding how the DAG structure of Avalanche is formed.
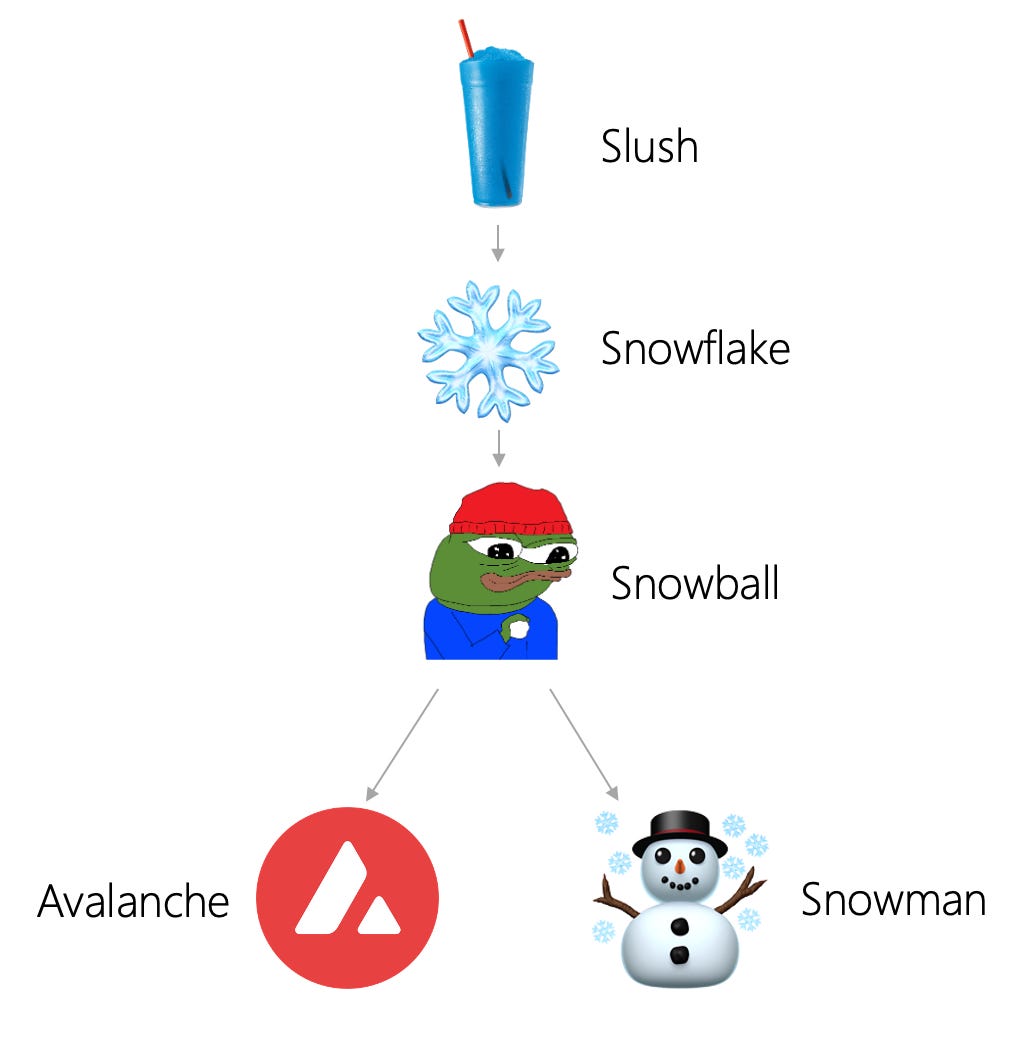
There are four major building blocks that make up the Avalanche consensus: Slush, Snowflake, Snowball, and Avalanche. Separate from Avalanche is Snowman, which we will discuss later. Let's first look at how Slush consensus operates. The Avalanche network consists of many nodes. Each node has three states: neutral, true, and false. This can better be represented in terms of color: uncolored, blue, and red.
Every node starts off uncolored, where it faces a decision to vote true or false (red or blue). Once a color is chosen, the node communicates with many other nodes in the network. If those nodes do not yet have a color, they will adopt the color of the node which communicated with them. If a majority of the nodes have the same color, the original node keeps its vote the same. If a majority of the nodes are a different color, the original node will flip its vote to that color.

Multiple rounds of communication will occur between nodes until all the nodes are all on the same page. The goal is to have everyone reach consensus on what the color is. The nodes that have the most of a certain color should dictate what the correct color is. This concept is the general building block of Avalanche and everything builds from it.
The second building block of Avalanche is Snowflake consensus. This is when memory is implemented into the nodes. Each node is given a counter. For every Slush communication which returns the same color, the counter increments. Everytime the node flips its color, the counter resets. Once the counter reaches a high enough number, it will lock its state and prevent the node from changing color. This helps solidify what the true color is.
Nodes start to gain a larger memory in the third building block, Snowball. Snowball builds on top of Snowflake by adding a state of confidence. Rather than changing color based on the nodes it communicates with, it will look back on all of its own color changes and will change its color based on the confidence state of the node, as measured by its vote change history.
This all leads up to Avalanche. Avalanche is an append-only (transactions add on to previous ones) DAG. Avalanche can function without having a DAG structure, as seen with the linearization of Avalanche on the Contract chain (C-Chain) and Platform chain (P-Chain). Team Rocket, the entity behind Avalanche consensus, felt that the DAG architecture was superior to a blockchain approach because it allowed voting to be more efficient, as one transaction is a vote for all transactions it is appended to.
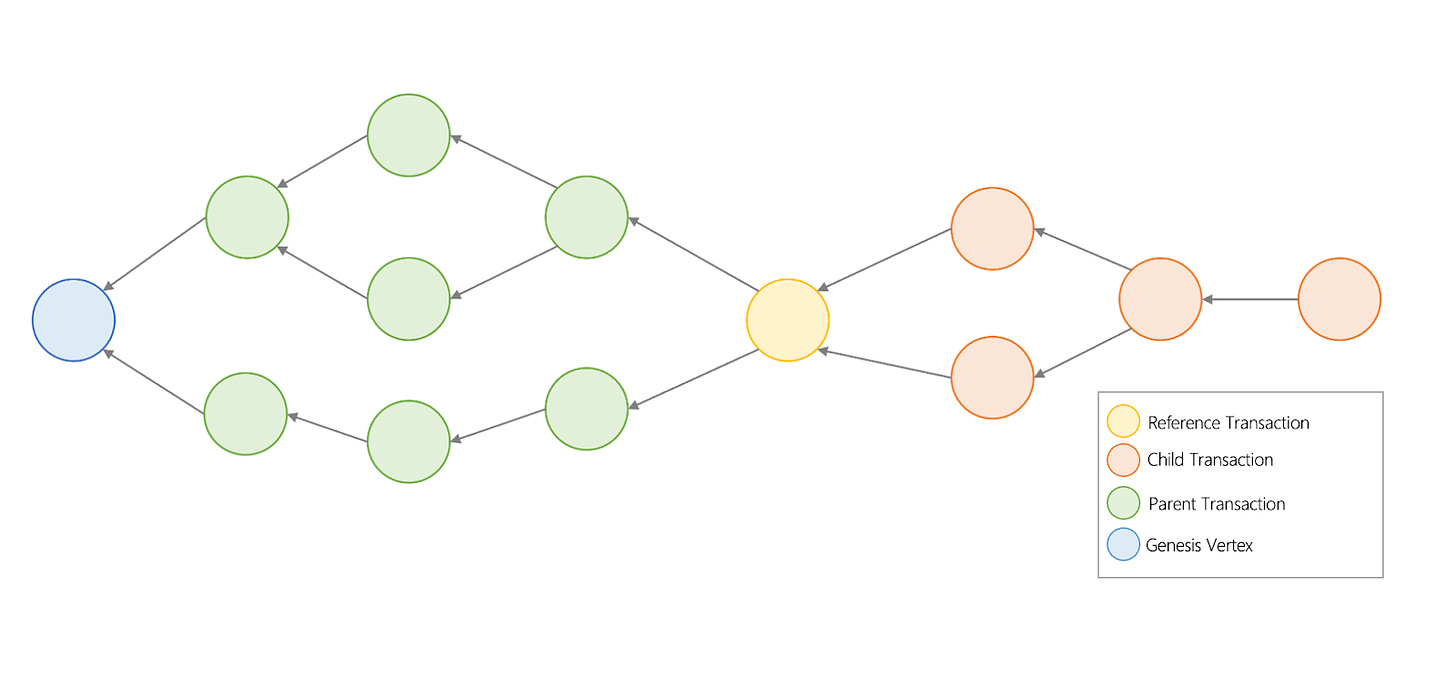
The Avalanche consensus consists of multiple Snowball instances to build a dynamic DAG of all known transactions -- each Snowball instance is a vertex in a graph. A vertex is like a block in a linear blockchain. It contains the hashes of its parents, and it contains a list of transactions. Avalanche consensus builds on top of Snowball, and the idea of confidence counters but applies it to nodes on a DAG. Instead of red and blue decisions, as previously discussed, nodes in the Avalanche consensus reach a consensus on whether a transaction is correct or if it conflicts with another transaction. Each transaction links onto a parent transaction which all links back to a genesis vertex. A transaction can have child transactions, which reference it and all of its parents. A genesis vertex is needed as one transaction is needed to act as the basis for the rest (IOTA also has a genesis vertex); this is important, as all append-only transactions need to add onto something. However, one unsolved problem caused by directly applying Snowball to a DAG of nodes is handling conflicting transactions, or double spends. Avalanche builds upon Snowball by adding the concept of “chits”. When a confidence threshold is reached, a counter called chit is added to a transaction, giving a value of “1.” If it was not given a value, the chit counter is “0.” The node will count the sum of chit values as an additional confidence method, similar to Snowball. The sum of chits is then used by nodes to determine a confidence in not just the specific transaction, but also in all of its children (new transactions appended onto the node).
Avalanche is capable of taking the building blocks of Slush, Snowflake, and Snowball and adapting them to linear chains. Avalanche does this for its Snowman consensus, which is completely separate from Avalanche consensus. Snowman consensus is account-based, which differs from Avalanche’s UTXO model. The Snowman consensus is used for the Platform chain (P-chain) and Contract chain (C-chain) of the Avalanche networks. The protocol is the same as described above, but each vertex only has one parent instead of multiple. This gives a total ordering of vertices. This causes the overall structure to be a blockchain, not a DAG. This is useful for applications where it is needed to know if a transaction came before another transaction, and also easily supports smart contracts.
The Avalanche consensus protocol is amazing for monetary transfers, and can be applied to various other protocols. It was once used as the pre-consensus mechanism for Bitcoin Cash before being hard forked into its own project, Bitcoin ABC. The DAG structure of Avalanche provided increases in transaction speed, and the lack of smart contracts provided no hindrance to Bitcoin Cash, as it has no need for such applications. In a world of payments, disregarding smart contract needs, Avalanche highlights how a DAG-based ledger can scale efficiently.
IOTA, a transaction-based DAG using Proof of Work
IOTA’s causally ordered structure is Tangle, which is a network of parallel-processed transactions. The Tangle is the data structure behind IOTA which forms the DAG. IOTA’s tangle holds transactions, where each transaction is represented by a vertex in the graph. When a new transaction joins the Tangle, it chooses two previous transactions to approve, adding two new connections to the graph.
In the diagram below, transaction G approves transactions E and F. Transactions hold information such as “Alice gave Bob ten IOTA coins.” Unapproved transactions are called “tips.” Transaction G is a tip, because it has not been approved yet. Each incoming transaction’s goal is to connect to two tips to approve. There are strategies to choose which two tips to approve, but the simplest is to choose two at random. For new transactions selecting tips to approve, this process is highly scalable.
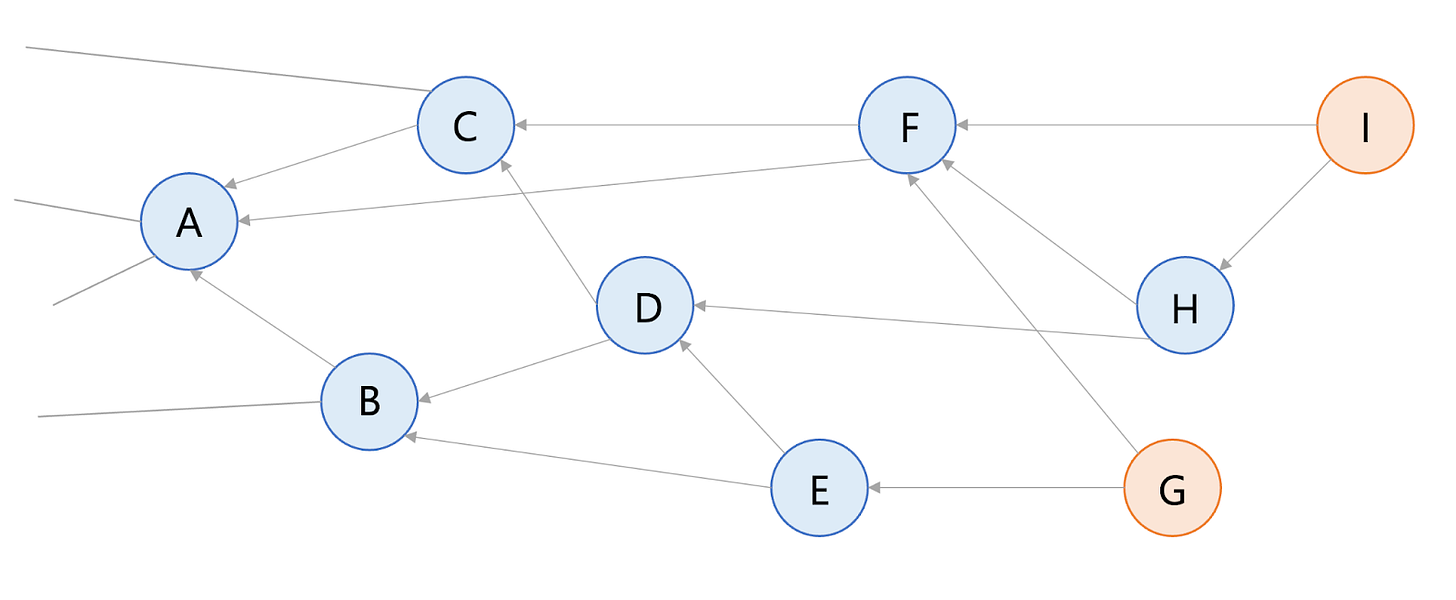
The red transactions, I and G, are unapproved tips as they do not have any other transactions connected to them. Every other transaction is approved, as each has a transaction connected to it.
However, another important concept that strengthens the DAG architecture of IOTA is the implementation of weights. How can we know if a transaction is trusted or not? In a typical blockchain, it is common to see how many confirmations a blockchain has. IOTA implements a similar technique by seeing how much weight a transaction has.
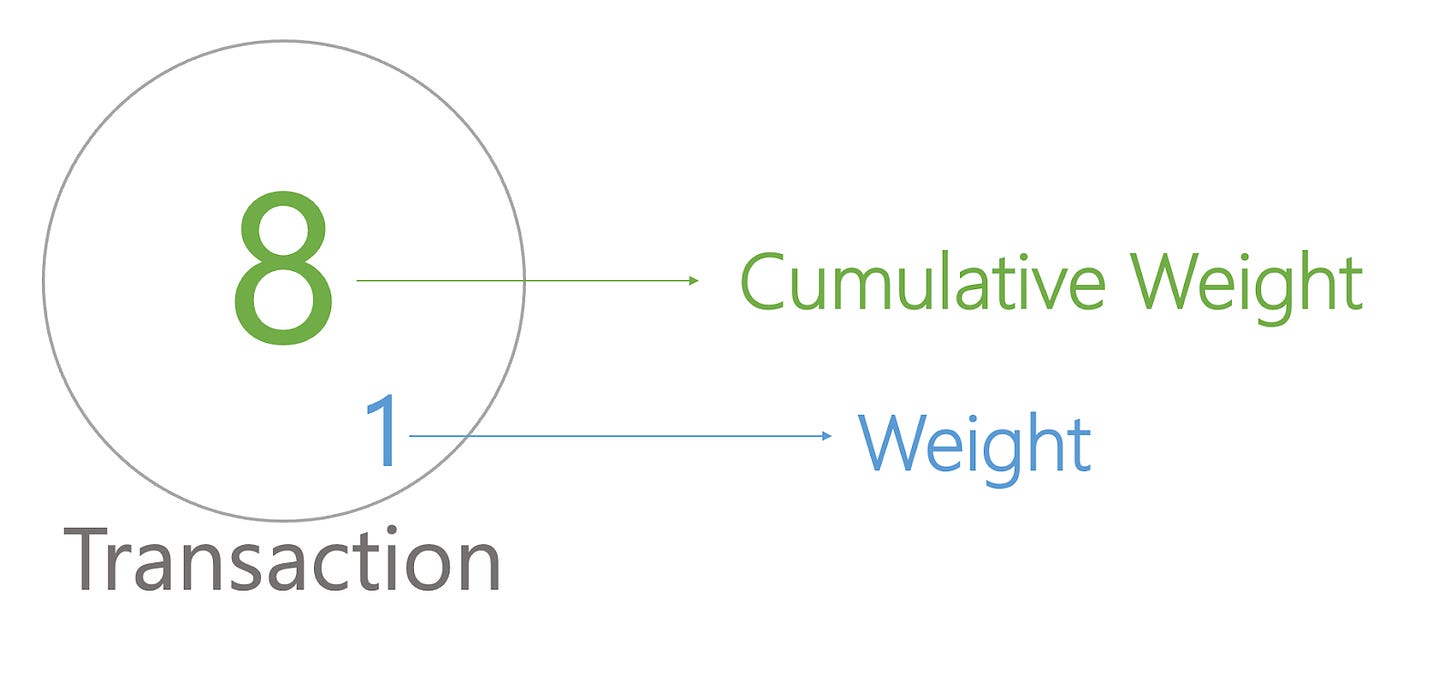
The weight of a transaction signifies how much work a node has done to create this transaction. Each transaction has an initial weight, and the value can be 1, 3, 9, etc (n3). A higher weighted transaction tells us that the node spent more work on the transaction. Each transaction also has a cumulative weight; this is a score of its own weight plus all transactions which directly or indirectly approve it. Let’s dive into how this mechanism works.

Each transaction has its own weight assigned to it and a cumulative weight that increases every time a tip is added onto the tangle.
In the figure above, we can see that transaction D is directly approved by transactions E and H, while also being indirectly approved by G and I. The cumulative weight of D is 3 + 1 + 3 + 1 + 1 = 9, which is the sum of its own weight plus the weights of E, H, G, and I.
A transaction with a larger cumulative weight is more important than a transaction with a smaller cumulative weight. Each new transaction added to the tangle increases the ancestors cumulative weight by the weight of its own transaction. Older transactions grow in importance over time. The use of cumulative weights avoids spamming and other attack vectors, as it is assumed no entity can generate many transactions with a large enough weight in a short period of time.
Despite being highly scalable, similar to Avalanche’s X-Chain, this method makes it nearly impossible to integrate smart contracts. In an effort to compete with other smart contract chains, IOTA is releasing a separate smart contract layer, dubbed “Assembly.” Assembly is a totally-ordered layer 2 which aims to support both EVM and WASM smart contracts.
Sui, a smart contract DAG using Proof of Stake
While Sui was included in the causally-ordered section of this report, it actually employs both total and causal ordering. Sui’s transaction processing architecture can be viewed as two parts: one part for dependent transactions that are totally-ordered and executed sequentially, and one part for independent transactions that are causally-ordered and executed in parallel. Transactions that are dependent utilize Sui’s Narwhal and Bullshark protocol. Narwhal is a DAG-based mempool, while Bullshark is a consensus protocol that integrates with Narwhal to reach consensus. Dependent transactions only have to be totally-ordered with other transactions they depend on. However, Sui has another method which it employs when transactions are entirely independent. For these transactions, Sui does not use Narwhal and Bullshark. Instead, it uses a method called Byzantine Consistent Broadcast (BCB). Using this method, there is no need for global consensus, so transactions are processed and written to the ledger nearly instantaneously.
Whereas most distributed ledgers are centered around addresses, Sui’s ledger is centered around “objects”. It is important to understand that objects can be NFTs, dapps, tokens, or basically anything you can build as a smart contract on a traditional blockchain. Every object has an assigned “owner” property, which states who can interact with the object. An object can have 4 distinct types of ownership. The first type is an object owned by an address, so that a user can possess something on Sui, such as holding coins in their wallet. The second type of ownership is an object owned by another object, such as a token object being held inside of a multisig smart contract object. The third type of ownership is an object being immutable, essentially having no owner. Nobody can change an immutable object, but anybody can interact with it. The fourth and final type of ownership is an object that is shared. Anybody can read or write to a shared object, an example of this being an AMM.
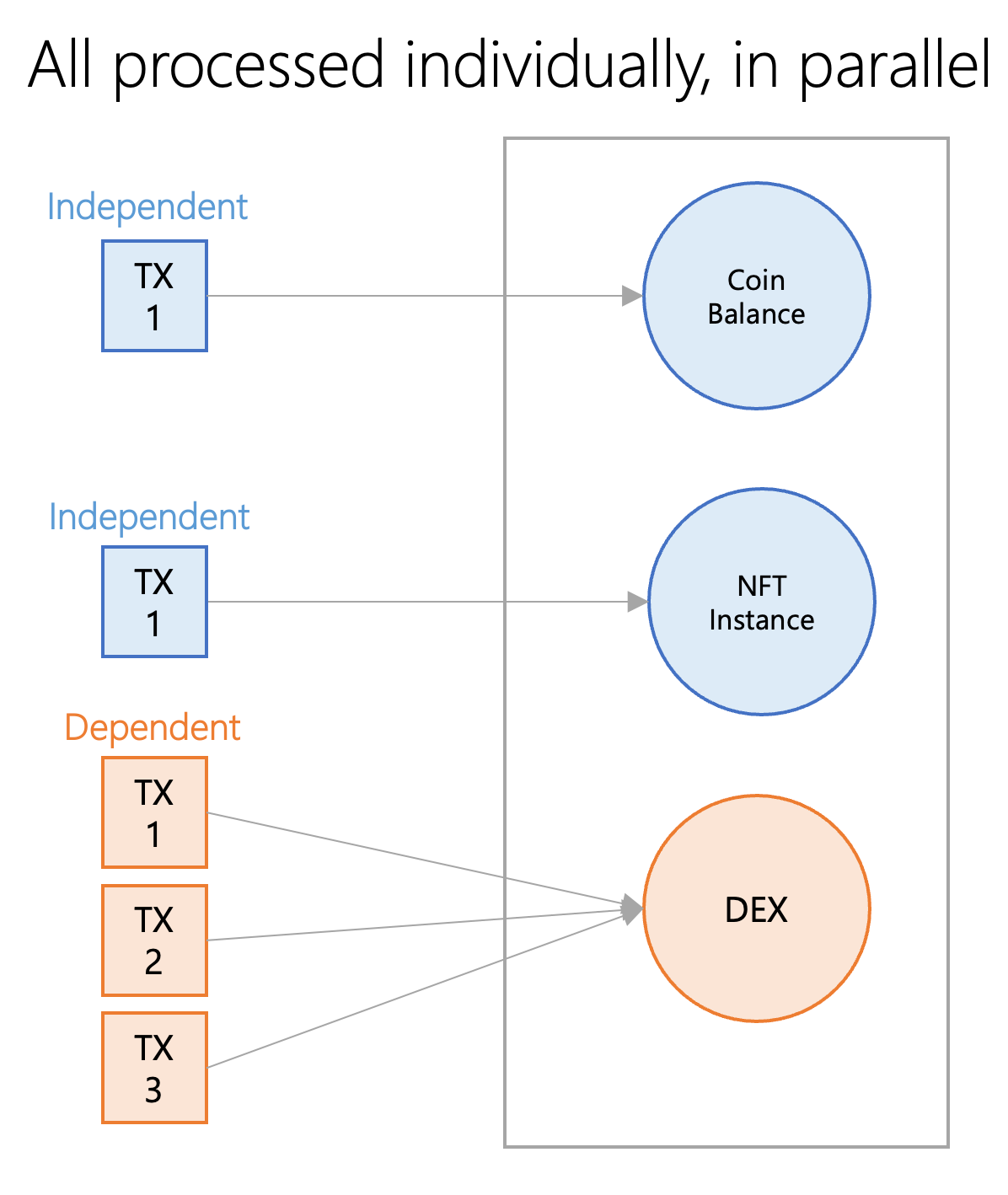
No matter how the transactions are ordered, all transactions are processed in parallel on the same network.
Transactions, which are simply a change to the metadata of a specific instance of an object, take objects as inputs and read, write, or mutate these inputted objects to produce freshly-created/updated objects as outputs. Each object knows the hash of the last object that produced it as an output.
Objects can either fit into Sui’s totally-ordered or Sui’s causally-ordered consensus architecture. Total ordering must be present in transactions with shared objects, as any user’s transaction can change the object they are interacting with, so the transaction ordering does matter. However, if an object is owned by an address, only that address is capable of changing it in a transaction. Therefore, transactions written to this object have no relation to any other transactions, which means that it can use Byzantine Consistent Broadcast. While the combination of Narwhal and Bullshark produces a fast consensus architecture, BCB is nearly instant.
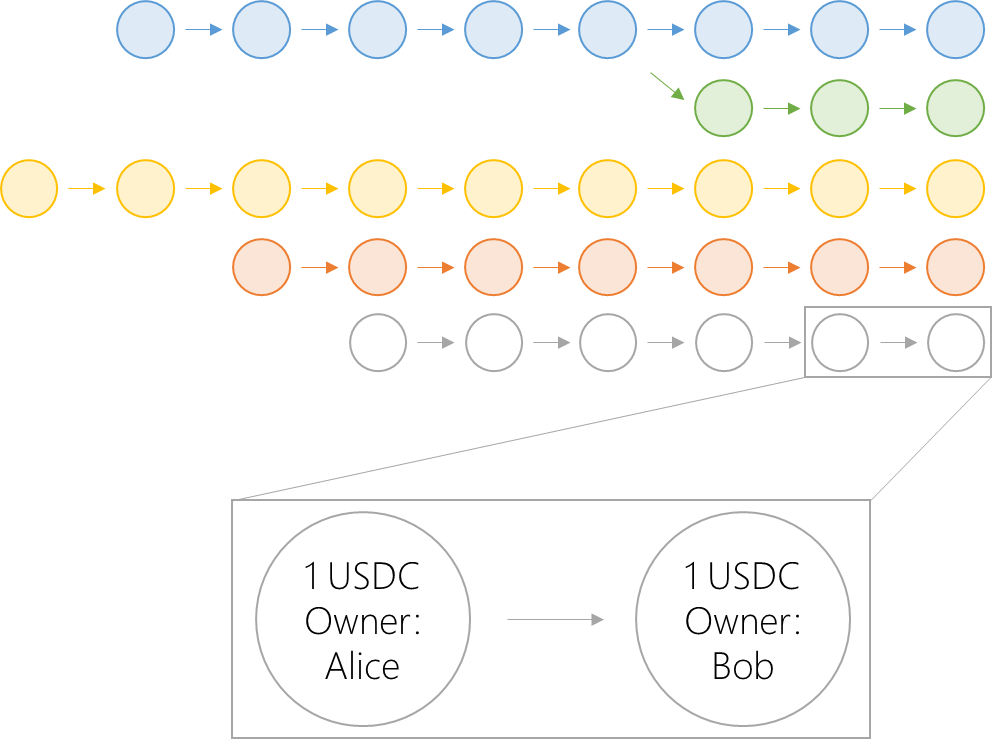
Sui’s ledger is an “object store” or “object pool” whose data is stored in a DAG. The act of sending USDC, for example, is the act of updating the “owner” attribute of an object, which has no effect on the other objects.
Sui’s ledger is an “object store” or “object pool” whose data is stored in a DAG. In this DAG, the nodes are objects, while each arrow in the diagram represents a transaction which updates the attributes of a given object or objects. Not represented in this figure is the Genesis transaction, which is a transaction that takes no inputs and produces the objects that exist in the initial state of the system.
While other distributed ledgers with a DAG structure have failed to offer an integrated smart contract solution, Sui seems to have solved these roadblocks with an innovative approach. Sui’s smart contract language, Move, naturally supports the object typing and parallel execution of Sui’s transaction. Without Move, Sui’s smart contract architecture may not have been possible.
Key TakeawaysCausal ordering of transactions seems to offer a number of advantages versus total ordering, in terms of both speed and throughput. However, the lack of ordering creates issues when trying to create applications which require strict time-based ordering, and many projects have been unable to properly get smart contracts to work on their DAG architecture. Fantom’s totally-ordered, blockchain-like structure allows for EVM and smart contract support. Despite having a totally-ordered output, the developers of Fantom still have found ways to optimize their layer 1 using a DAG-based consensus mechanism. Avalanche chose a different method and created a separate consensus mechanism, Snowman, to support the EVM and add easy-to-develop smart contract support. IOTA also chose another method, and is creating the framework to easily deploy blockchain instances on top of IOTA to support the EVM, effectively creating a totally-ordered layer 2 infrastructure. Sui’s unique design seems promising, and transactions can both be totally-ordered or causally-ordered as needed, allowing for smart contract capabilities on the network while also reducing latency.
Sui is the latest DAG-based layer 1, but it seems to differentiate itself enough and iterate on flaws previously seen in the space, to a point where DAGs as a structure may truly gain adoption as a distributed ledger. Even if causally ordering transactions does not become the future, DAG-based technology helps scale existing blockchains. While DAGs as a scaling method may not be optimal for every scenario, it has seemed to work well for Avalanche’s X-Chain and IOTA in terms of latency and throughput. However, the lack of smart contract support lessens its importance in the current competitive landscape, especially in the age of layer 2 roll-ups and off-chain Zero Knowledge scaling solutions. While most DAG-based ledgers do reduce latency with a low loss of decentralization, both blockchains and DAGs as distributed ledgers are designed where every node on the network needs to process every transaction. This is one of the biggest problems any distributed ledger needs to tackle to be fully scalable. Sui was able to combat this with its unique design of BCB, allowing for transactions to skip consensus. This is not necessarily a key aspect for every DAG-based architecture though, and should not be used as an argument to say all DAG-based architectures are better than all blockchain-based architectures. However, a DAG is just a data structure at the end of the day, and we are seeing use cases of it across distributed ledger technology. Sui’s Mysten Labs is currently working with Celo, a layer 1 blockchain, to implement the Narwhal architecture into its mempool. Narwhal is a mempool protocol which itself is designed as a DAG. Everything about Celo as a ledger is a blockchain, but it has achieved performance improvements using a DAG as a component in its backend. It’s possible that the argument of DAG vs. blockchain ledgers is made less relevant by more modern scaling solutions. This paper’s purpose is to inform readers about architectures that currently exist. With applications like Narwhal, this may be where we see the most usage of DAG’s going forward. It is impossible to predict how widely used DAGs will become in distributed ledgers, but they certainly appear to be growing in relevance as a technology.
About the author
Robert McTague is an Investment Associate for Amber Group's Eco Fund, the company's early stage crypto venture fund. Prior to joining Amber, he graduated with a bachelor’s degree in electrical engineering and worked for a DeFi company where he focused on business development. Outside of his studies, he developed a passion for developing smart contracts and learning about the web3 space as a whole.
Disclaimer
The information contained in this post (the “Information”) has been prepared solely for informational purposes, is in summary form, and does not purport to be complete. The Information is not, and is not intended to be, an offer to sell, or a solicitation of an offer to purchase, any securities. The Information does not provide and should not be treated as giving investment advice. The Information does not take into account specific investment objectives, financial situation or the particular needs of any prospective investor. No representation or warranty is made, expressed or implied, with respect to the fairness, correctness, accuracy, reasonableness or completeness of the Information. We do not undertake to update the Information. It should not be regarded by prospective investors as a substitute for the exercise of their own judgment or research. Prospective investors should consult with their own legal, regulatory, tax, business, investment, financial and accounting advisers to the extent that they deem it necessary, and make any investment decisions based upon their own judgment and advice from such advisers as they deem necessary and not upon any view expressed herein.
Thanks for reading Amber Labs! Subscribe for free to receive new posts and support my work.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.