Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
 Audio Spatializer, submission for BrickHack4
Audio Spatializer, submission for BrickHack4Some Background Information
I spent last weekend hacking at RIT’s BrickHack 4. Normally, I love to spend my hackathons building multiplayer games, but this time, I wanted to try working on an idea that I’d had in the back of my TODO list for a while. This idea came to me after I was listening to some nightcore (a remixed track of a song that speeds it up, increases its pitch, and puts more emphasis on a strong beat). Specifically, I was listening to this one on YouTube:
If you skip to the 0:36 mark, you can hear an interesting audio effect if you’re wearing headphones. The beat jumps between the left and right ear (this also happens at a few other points in this video). This was such an interesting effect that I wondered if it was possible to algorithmically create this effect for other songs. My end goal for this project was to be able take some dubstep and use stereo effects to switch the beat between the left and right ear and create an immersive listening experience. During the hackathon, I worked with my friend Andrew Searns to try and create a web application to do this (Andrew also showed me other interesting songs where the artist played around with stereo effects).
While it wasn’t as successful as we expected, we had a lot of fun coming up with an architecture to do this and I personally learned quite a bit of CSS Flexbox while designing the application interface. In this techsploration, I’ll take you through my thought process and show you how to generalize the code we wrote to build an audio processing framework in the browser.
The Audio Streaming Architecture
Okay, let’s figure out what we need to make this work. Ideally, we want users to simply paste a YouTube link into our application, which will handle streaming the audio, spatializing it, and then playing it.
Obviously, the first thing we’ll need is some way to do that audio streaming. I’ll discuss how we set that up in this section, and we’ll talk about the audio spatialization part later.
Because we wanted to develop and iterate quickly, we used

(also because I happen to like node.js very much). During the hackathon, we found two well documented ways to do audio streaming from YouTube. One option was the package youtube-audio-stream, and the other option was the package ytdl-core (which youtube-audio-stream actually depends on). After a lot of iteration and testing, we settled on using youtube-audio-stream to pipe the audio stream directly to the client.
To do this, the client sends the YouTube video ID to our server, which uses youtube-audio-stream to fetch it from YouTube and then pipe it back to the client.
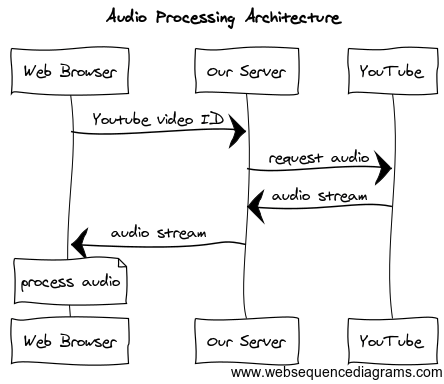 Diagram created using websequencediagrams.com
Diagram created using websequencediagrams.com
We decided to offload the audio processing to the client to reduce the load on our server. This turned out to be the most pragmatic solution for our purpose and was simple to code and put together.
Now you might be looking at this and asking why we didn’t cut out the middleman and have the web browser directly request the audio stream from YouTube. Cross-Origin Resource Sharing (CORS) prevents us from making a request from the client directly to YouTube. Additionally, we wanted our server to provide a communication channel between all the clients (for reasons we will discuss in a later section).
Below is a minimal working example of the architecture described above:
This might look like a lot of code to digest, but it’s actually quite simple and most of it is just boilerplate. Let’s run through it.
audio-processor-server.js is a pretty standard boilerplate express.js server with two routes defined: one for serving the HTML page to the client, and one for serving the audio stream to the client. The server will also statically serve files in the/client folder, which is where we will store audio-processor.js.
audio-processor.html is a plain HTML page with nothing but an input field for a YouTube video ID and a submit button.
audio-processor.js is the client side script loaded into the HTML page to send a request to the server for an audio stream. We’re using an XHR request to request the audio stream so that we can specify a return type of arraybuffer. Using the Web Audio API’s AudioContext object, we can decode the arraybuffer into an AudioBuffer object containing the decoded PCM audio data. This buffer is passed into the processAudio() method (not defined in the example stub above) which you can substitute that with any function you want.
Here’s an example processAudio() function that we used to do some naive beat detection. We passed the audio data through a low pass filter and isolated all points above a certain relative value. We’d like to thank Joe Sullivan for his fantastic article explaining and providing the low pass filter code below.
Here’s a link to a branch of our project containing the sample code above. You can do all sorts of interesting things using the PCM audio data in the AudioBuffer.
Note that the code in audio-processor.js is still relevant even if you don’t want to load audio from YouTube. You can apply it to statically loaded audio files or any other audio sources you may want to use. I recommend browsing through the Web Audio API documentation to explore all the cool things you can do with an audio buffer.
An Alternative Audio Streaming Architecture
Suppose however, you want to perform the audio processing part on the server. This has several advantages to doing the processing on the client: server side caching, architecture specific processing libraries, or simply convenience. The disadvantage however, is that many concurrent requests will put a lot of load on your server.
We also experimented with doing the processing server side during the hackathon using an architecture like this:
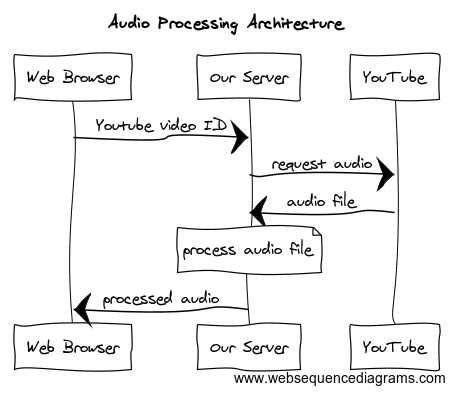 Diagram created using websequencediagrams.com
Diagram created using websequencediagrams.com
We chose not to do this to reduce server load, but I’ll give sample code for this architecture as well if you would like to replicate this for your own projects.
audio-processor-server.js is again a simple express.js boilerplate server, but with a few extra pieces this time. In this version, we save the audio stream to the file system as a .flv file. This is not necessary if you want to just pipe the audio stream into your custom audio processor, but we found that this allowed for more flexibility and control. Like before, this server has two routes defined: one for serving the HTML page and one for serving the audio streams. Again, the server will also statically serve files in the /client folder.
audio-processor.html is the same plain HTML page with an input field for the YouTube video ID and a submit button.
audio-processor.js is a client side script loaded into the HTML page that simply requests an audio file using an HTMLAudioElement and plays it.
If you choose to do the processing server side, be aware that the Web Audio API is a web JavaScript API that is not part of the JavaScript language. Therefore, it is not available to the node.js server running on the server side.
If you want even more granularity, you can actually combine the two methods described above to do processing on the server and additional post-processing on the client. We didn’t try this but you can probably do a lot of cool things by combining backend specific libraries with the power of the Web Audio API.
If you were only interested in building an in-browser audio processing architecture, then you can stop reading here or skip to the end. The rest of the techsploration will be about how we connected this audio streaming architecture to the Resonance Audio API for our hack.
Spatializing The Audio Stream
Once we got past the challenge of figuring out the best way to manipulate an audio stream, we needed to figure out how to move the audio in stereo to create the effect we wanted. We used the Google Resonance Audio API to do this. Given an audio source and a vector position, this API allowed us to position the audio source around the listener in 3D space. You can explore this effect in their demos (best experienced with headphones).
Our plan was to generate a list of vector values based on the audio data and use the Resonance Audio API to move the sound source around while the audio was playing. This was pretty trivial to do using setInterval() and synchronizing the list of vector positions using the current frame in the audio. We could calculate exactly which vector position to position the audio source at since the sampling rate of the audio buffer was known.
The hard part (and the coolest part) was figuring out how to generate the list of vector positions properly so that the stereo panning was in sync with the beat. We didn’t want to just oscillate between left and right and we didn’t want the movement pattern to be repetitive and boring. Andrew and I experimented with various movement patterns and developed a scheme to encode them.
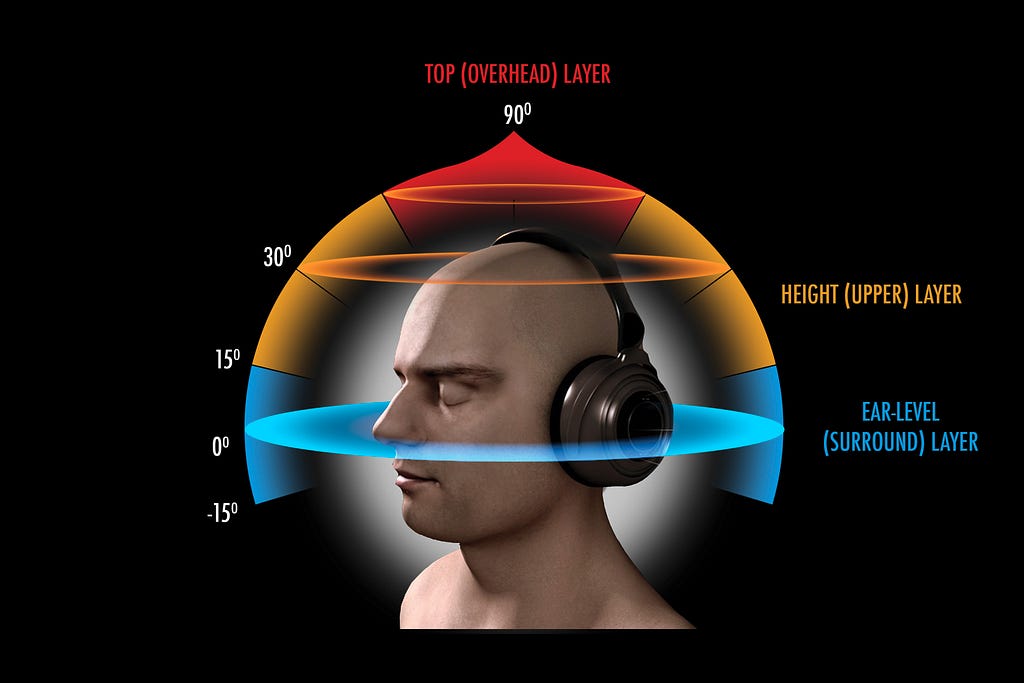 Locations around the head which we can place the audio source. Image from 3D audio experience — Imgur.
Locations around the head which we can place the audio source. Image from 3D audio experience — Imgur.
We named the movements patterns as Transforms and decided on 5 distinct ways in which we could move the audio around the listener: Jumps (which move the audio source to a random location around the listener), Flips (which move the audio source to the direct opposite side of the listener), Rotates (which slowly rotate the audio source around the listener), Delays (which hold the audio source in place), and Resets (which reset the audio source to the origin). Using the naive beat detection algorithm described before, we transitioned from one Transform to another on every beat.
To generate sequences of Transforms, we used a Markov chain, initially seeding every transition with equal probability. Here’s where we actually utilized the server as a relay point between the connected clients. We attempted to make the sequence generation somewhat intelligent by adding a button to the interface allowing the user to vote up or vote down the current audio spatialization pattern. The server would then take this into account by increasing or decreasing the probability of the sequences used in the song the user was listening to.
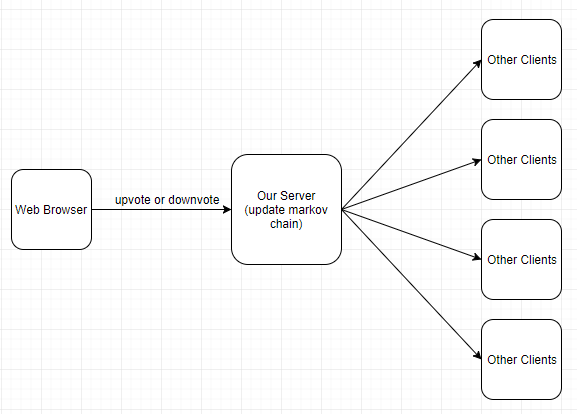 Diagram made with draw.io
Diagram made with draw.io
The new Markov chain would be propagated to all clients, and any new clients that visited the site would use the new probabilities to generate their spatialization. Even though we fully hashed out this idea, miscellaneous bugs and issues with JavaScript objects prevented us from fully implementing it in time for the hackathon submission.
Afterthoughts
This was a fantastic project to design and play with. There are lot of interesting things to explore in the Web Audio API. I don’t know much about audio encoding but I imagine the resources there would be a lot more useful if I had a little more background knowledge about audio codecs and PCM data.
If you’d like to check out our project in its entirety, here is a link to the git repository. There are three notable branches. The master branch contains our implementation of the audio spatialization project. The blog-min-example branch contains the client side processing example described in the first section, and the blog-min-example-2 branch contains the server side processing example described in the second section.
If you’d enjoyed this techsploration, consider hitting the clap icon or following me on Twitter for more content like this. Thanks very much for reading!

How To Build An Audio Processor In Your Browser was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.