Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Implementing the Apache Kafka ecosystem for processing Ethereum blockchain data
In the decade since Bitcoin introduced the world to cryptocurrencies, the industry has evolved in ways that perhaps even Satoshi could not envision. The Ethereum blockchain, which emerged in July 2015, opened a new world of possibilities thanks to the Ethereum Virtual Machine (EVM) — an environment for developing and executing smart contracts.
The EVM enabled the Ethereum network to be something more than a repository for a history of monetary transactions — it was an ecosystem that invited exploration, interaction and collaborative innovation.
Continuing the MEW (MyEtherWallet) legacy of open-source products that empower both users and developers to explore the possibilities of blockchain, we introduce EthVM: the first open-source block explorer and data processing engine for Ethereum, based on Apache Kafka.
EthVM’s origins: a compass to navigate the EVM
A block explorer is an indispensable tool for blockchain auditing and decision making that uses a convenient browser format. Explorers help users verify the execution of transactions and smart contracts, check balances, and monitor gas prices.
For developers, block explorers reveal new possibilities of retrieving blockchain data for dapps and open-source wallets, inspiring innovation throughout the growing Ethereum ecosystem while providing the transparency that’s so essential in a decentralized network.
When our team first began to develop EthVM Alpha, the initial idea was to create a blockchain explorer that was easy to use, featuring a front end built with VueJS and real time updates powered by RethinkDB on the back end.
As a developer, you really just need three basic things to build an explorer, and that’s what we started with:
- An Ethereum node that is synced with the network
- A database to store the information
- A website to display that information
However, those are not the only considerations to take into account. Usually, when the blockchain grows to a certain size, the amount of information you have to process is enormous. Not only that — running a fully synchronized node can be a complex process. It can take a great deal of time and resources, as well as make considerable demands on the CPU and the disk.
Filling the need for an open-source Ethereum block explorer
As we worked to address these challenges, our team realized that not only were existing block explorer options limited — they were also mostly closed-source, meaning that only a small group of developers could contribute to the innovation of this important tool.
We discovered that others in the field were working on the issue through a wonderful initiative originated by Griff Green, the founder of Giveth.io. His April 2018 post on Ethresearch — a community that allows you to participate in Ethereum’s research efforts — stressed the importance of an open-source approach to block explorers. It resonated with our own vision and reinforced our conviction that the Ethereum ecosystem needed an intuitive open-source explorer that could evolve with the help of many people around the world.
Unexpected inspiration
In another testament to the collaborative nature of technological progress, the inspiration for the most important feature of EthVM came from an unexpected source. A post called “Publishing with Apache Kafka at The New York Times”, written by Boerge Svingen on the Confluent Blog, describes how the iconic New York Times transitioned from a jumble of APIs, services, producers and consumers to a log-based architecture powered by Apache Kafka.
To highlight a passage:
Traditionally, databases have been used as the source of truth for many systems. Despite having a lot of obvious benefits, databases can be difficult to manage in the long run.
…Log-based architectures solve this problem by making the log the source of truth. Whereas a database typically stores the result of some event, the log stores the event itself — the log therefore becomes an ordered representation of all events that happened in the system. Using this log, you can then create any number of custom data stores. These stores becomes materialized views of the log — they contain derived, not original, content. If you want to change the schema in such a data store, you can just create a new one, have it consume the log from the beginning until it catches up, and then just throw away the old one.
A blockchain is essentially a continually growing list of records, consolidated into blocks which are linked using cryptography — a Linked List, in programmer terms. In Kafka terminology, an Ethereum client would be our producer — the one in charge of creating new entries of our ‘log’.
The implications of what Boerge is explaining above are huge:
- If the architecture is log-based, you can consume and process the Kafka log, and output the information somewhere else — for instance, a database or a PDF report.
- Also, as a bonus and depending how the topics are modeled and configured, you can replay the log any number of times. This means that you can always ‘go back’ in time and reprocess data.
EthVM and the Kafka Ecosystem
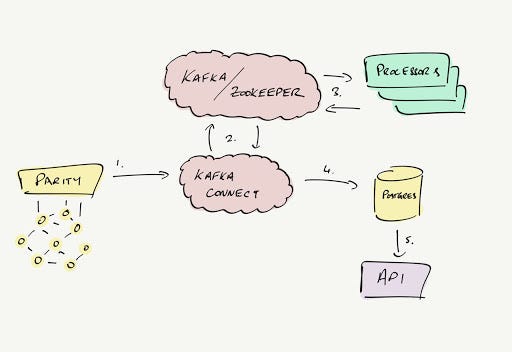
So, how is this applied in EthVM? By fully embracing the complete Apache Kafka ecosystem, comprising the following tools: Kafka Connect, Kafka Streams and Kafka Schema Registry.
Let’s see how these tools are used in the context of EthVM:
Kafka Connect
The official project describes Kafka Connect as:
… a tool for scalably and reliably streaming data between Apache Kafka and other systems. It makes it simple to quickly define connectors that move large collections of data into and out of Kafka. Kafka Connect can ingest entire databases or collect metrics from all your application servers into Kafka topics, making the data available for stream processing with low latency. An export job can deliver data from Kafka topics into secondary storage and query systems or into batch systems for offline analysis.
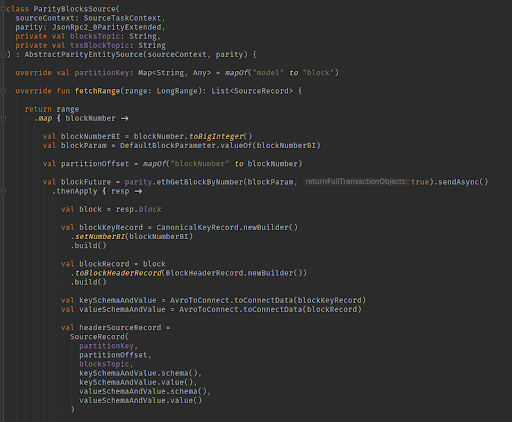 This is how we capture a block (simplified for the purposes of this article)
This is how we capture a block (simplified for the purposes of this article)
In the case of EthVM, we created a ParitySource connector that allows us to read all required information from a RPC / Websocket endpoint and dumps the data to specific topics.
With Kafka Connect, we have a standardized set of APIs to ingest data to Kafka. The beauty of this approach is that in the future we will be able to create more connectors that are based on the same principle (to support Geth and other clients).
Kafka Streams
Once the important data is inside Kafka topics, the second step is to interpret the data to obtain meaningful information. This is where Kafka Streams comes in:
Kafka Streams is a client library for building applications and microservices, where the input and output data are stored in Kafka clusters. It combines the simplicity of writing and deploying standard Java and Scala applications on the client side with the benefits of Kafka’s server-side cluster technology.
On EthVM we have created specialized ‘processors’ that take advantage of Kafka Streams utilities to perform aggregations, reductions, filtering and other useful operations.
For example, one dedicated processor analyzes and extracts fungible token transfers like ETH or ERC20. Another specializes in non-fungible ones, like those found on ERC721. Other processors focus on useful block metrics — with information related to average gas price, number of successful or failed transactions — and transaction fees. In fact, we can create as many processors as we need to ‘hook’ to concrete topics for receiving data that is most relevant.
We are using Kafka Connect to create a sink where we store the data output from our processors. Currently, we are moving to Postgres / Timescale, but we initially started with MongoDB.
Kafka Schema Registry
What about the Schema Registry?
Schema Registry provides a serving layer for your metadata. It provides a RESTful interface for storing and retrieving Avro schemas. It stores a versioned history of all schemas, provides multiple compatibility settings and allows evolution of schemas according to the configured compatibility settings and expanded Avro support.
Basically, it’s a place to store Avro schemas. But what’s Avro?
Avro is a remote procedure call and data serialization framework developed within Apache’s Hadoop project. It uses JSON for defining data types and protocols, and serializes data in a compact binary format.
Avro is a first-class citizen in the Apache Kafka ecosystem. We have used it in EthVM to create custom entities that are agnostic of any concrete implementation of Ethereum. As an additional benefit, its format is very compact, allowing us to save disk space.
Help us shape the future of EthVM
We are excited to share that the Alpha version of the ecosystem is currently live — with the initial processor setup, using Mongo as main storage database. Moving forward to the Beta release, we are looking to make EthVM more stable and implement a number of features, including the following:
- Migration to NestJS API
- Migration from MongoDB to Postgres / Timescale
- Improvements to processing on Kafka (squash bugs and improve speed)
- Bring a Terraform provider to properly deploy the code on AWS
Our number one goal is to process the Ethereum chain as quickly and concurrently as we can, eventually adding more chains to the mix. With a good Kafka cluster we’ll be able to process multiple chains at the same time. Besides, the block explorer is just one of many ways to view blockchain data!
EthVM is powered by MyEtherWallet — a company committed to producing open-source projects that will benefit the Ethereum ecosystem as a whole. Together, we envision a global financial future where crypto will play a big role in bringing new opportunities to already established markets.
If you like to crunch data and share our passion for Ethereum, we would love to have you onboard. Our code repository is on Github. Also, we have a public Ethvm — Devs Slack channel where you can hang out with the core developers (invitation link).
Because we really enjoy getting into the details with the community and hearing all kinds of feedback, we are looking forward to releasing more articles with deep dives into some cool technical aspects of this project. Stay tuned and get in touch!
Written by Aldo Borrero, EthVM Tech Lead.
For more content from MEW and EthVM, see MEW Publications. For more details and to contribute, go to Github.
EthVM: First Open-Source Block Explorer Powered by Kafka was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.