Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Unsupervised Learning Photo by Jan Střecha on Unsplash
Photo by Jan Střecha on Unsplash
Photo by Jan Střecha on Unsplash
Unsupervised learning approach is demonstrated by state-of-the-art NLP model (e.g. BERT, GPT-2) to be a good way to learn feature for downstream task. Researchers demonstrated data-driven learned features provide a better audio feature than traditional acoustic feature such as Mel-frequency cepstrum (MFCC).
This story will discuss about how can you use unsupervised learning to learn audio feature and applying it to downstream tasks.
Unsupervised feature learning for audio classification
Lee et al. propose to use convolutional deep belief network (CDBN, aksdeep learning representation nowadays) to replace traditional audio features (e.g. spectrogram and Mel-frequency cepstrum (MFCC)). The original input is spectrogram from each utterance and window size is 20ms with 10ms overlaps. Small window and overlapping setting is common when handling audio input. Believe that computer resource is limited in that time (it was 2009), they leverage principal component analysis (PCA) to reduce dimension before feeding into neural network.
The setting for the neural network includes 2 convolutional neural network (CNN) layer with 300 dimensions, filter length of 6 and max-pooling ratio of 3.
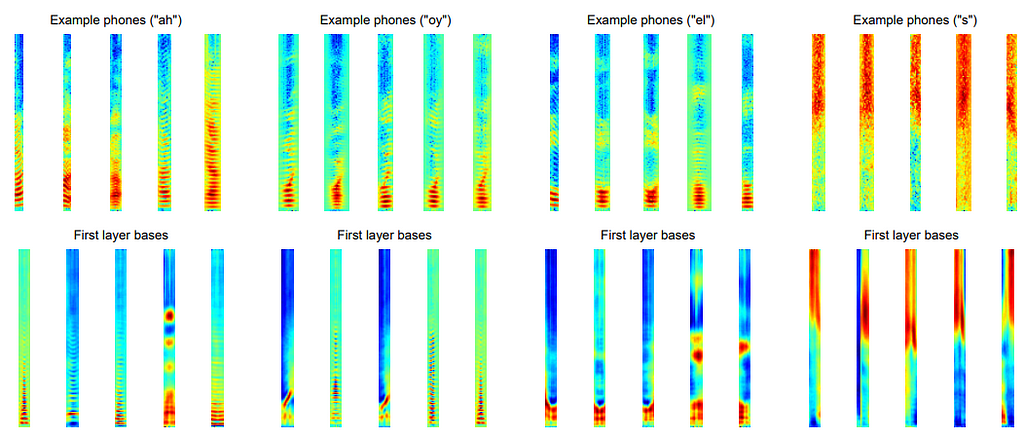 Visualization of pre-trained layer (Lee et al., 2009)
Visualization of pre-trained layer (Lee et al., 2009)
Lee et al. evaluated data-driven feature (CDBN) with traditional features which are spectrogram (i.e. RAW in the following figure) and MFCC for speaker identification, speaker gender classification, phone classification, music genre classification and music artist classification.
 Test classification accuracy for speak identification by using summary statistics (Lee et al., 2009)
Test classification accuracy for speak identification by using summary statistics (Lee et al., 2009) Test classification accuracy for speak identification by using all frame (Lee et al., 2009)
Test classification accuracy for speak identification by using all frame (Lee et al., 2009)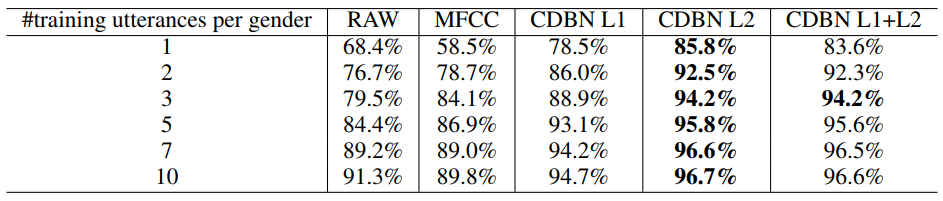 Test classification accuracy for gender classification (Lee et al., 2009)
Test classification accuracy for gender classification (Lee et al., 2009)
Unsupervised Feature Learning Based on Deep Models for Environmental Audio Tagging
Xu et al. use spectrogram as raw input to learn vector representation. Asymmetric de-noising auto-encoder (aDAE) is presented in the research paper. The network architecture include encoder (first three layers) and decoder (last three layers) parts. Spectrogram is extracted and feeding into the encoder while the training objective is predicting the middle of frame by using previous and next frames.
It is similar to Continuous Bag-of-Words (CBOW) in NLP. CBOW use surroundings to predict the target words.
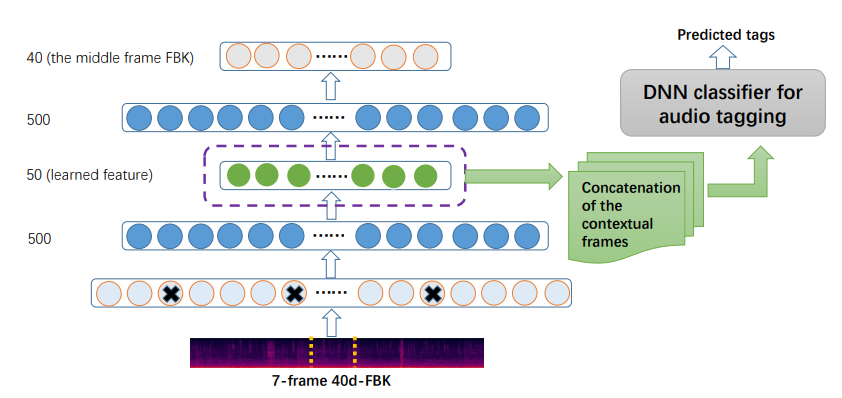 Network architecture of aDAE (Xu et al., 2016)
Network architecture of aDAE (Xu et al., 2016)
The following model comparisons demonstrate aDAE achieve a better result in general.
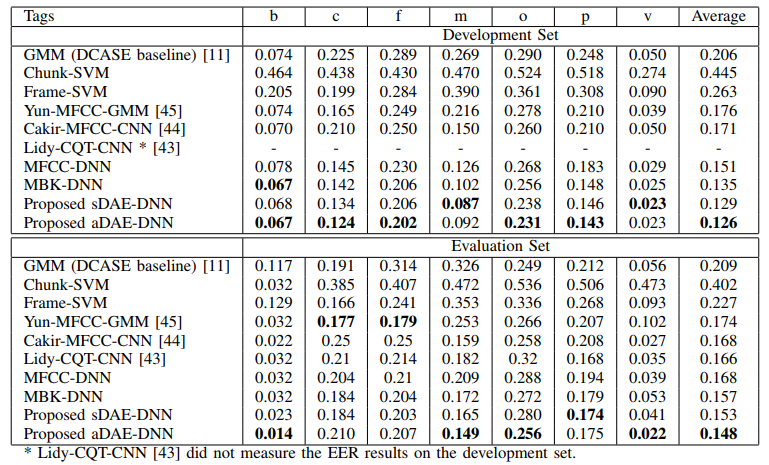 Model comparison results among labels (Xu et al., 2016)
Model comparison results among labels (Xu et al., 2016)
Unsupervised feature learning for audio analysis
Meyer et al. also use spectrogram as raw input to learn vector representation. The training object is using previous frame to predict next frame which is similar to language model in NLP. Audio frame predictor (AFP) is presented in this paper.
The network architecture include encoder and decoder parts. Spectrogram is extracted with 2.56s sliding window size and 0.64s overlaps and feeding into encoder which includes multiple ConvLSTM layer. ConvLSTM setting use 3x3 filter kernal with ReLu activation and batch normalization function.
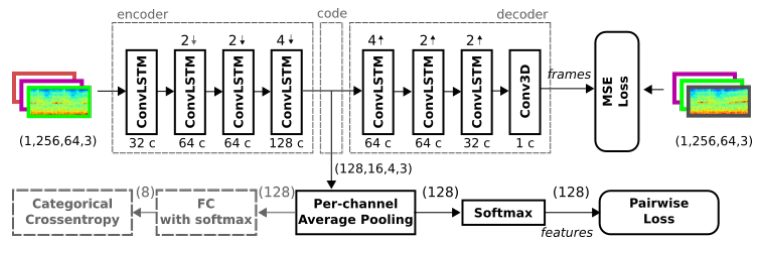 Model of the audio frame predictor (Meyer et al., 2017)
Model of the audio frame predictor (Meyer et al., 2017)
Meyer et al. use two steps procedure to train the data-driven representation. The network is trained by minimizing the mean squared error (MSE) (i.e. encoder to decoder) in the first 6 epochs. In the sixth to ninth epochs, pairwise loss training objected is added to adjust the representation simultaneously.
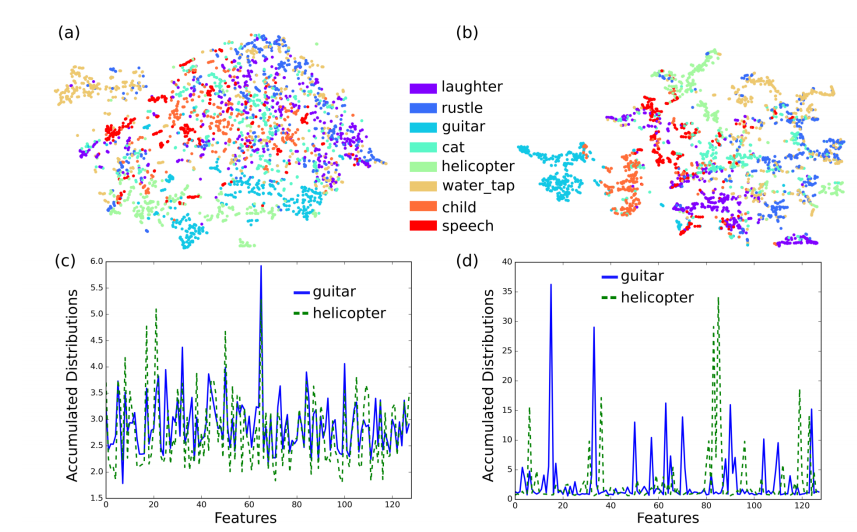 Vector distribution from pre-trained feature (Meyer et al., 2017)
Vector distribution from pre-trained feature (Meyer et al., 2017)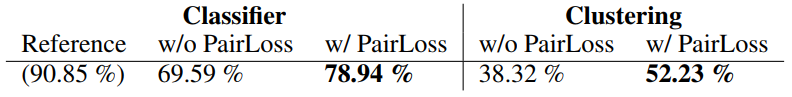 Tess accuracy for classification and clustering tasks (Meyer et al., 2017)
Tess accuracy for classification and clustering tasks (Meyer et al., 2017)
Like to learn?
I am Data Scientist in Bay Area. Focusing on state-of-the-art in Data Science, Artificial Intelligence , especially in NLP and platform related. Feel free to connect with me on LinkedIn or following me on Medium or Github.
Reference
- H. Lee, Y. Largman, P. Pham and Andrew Y. Ng. Unsupervised feature learning for audio classification using convolutional deep belief networks. 2009
- Y. Xu, Q.Huang, W. Wang, P.Foster, S. Sigtia, P. J. B. Jackson, and M. D. Plumbley. Unsupervised Feature Learning Based on Deep Models for Environmental Audio Tagging. 2016
- M. Meyer, J. Beutel and L. Thiele. Unsupervised Feature Learning for Audio Analysis. 2017
How can you apply unsupervised learning on audio data? was originally published in HackerNoon.com on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.