Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
 State Library of Victoria
State Library of Victoria
In this post, we will be building a serverless data lake solution using AWS Glue, DynamoDB, S3 and Athena.
So combining everything, we do the following steps:
- Create Dynamo tables and Insert Data.
- Create a crawler that reads the Dynamo tables.
- Create Glue ETL jobs that reads the data and stores it in an S3 bucket.
- Create Data Catalog Tables that reads the S3 bucket.
- Use Athena to query information using the crawler created in the previous step.

Lets get started
First we need to create DynamoDB table and insert data. In our case we are going to use AWS CLI:
let’s create sample tables: Forum, Thread and Reply.
$aws dynamodb create-table --table-name Forum --attribute-definitions AttributeName=Name,AttributeType=S --key-schema AttributeName=Name,KeyType=HASH --provisioned-throughput ReadCapacityUnits=5,WriteCapacityUnits=1 --region ap-southeast-2
$aws dynamodb create-table --table-name Thread --attribute-definitions AttributeName=ForumName,AttributeType=S AttributeName=Subject,AttributeType=S --key-schema AttributeName=ForumName,KeyType=HASH AttributeName=Subject,KeyType=RANGE --provisioned-throughput ReadCapacityUnits=5,WriteCapacityUnits=1 --region ap-southeast-2
$aws dynamodb create-table --table-name Reply --attribute-definitions AttributeName=Id,AttributeType=S AttributeName=ReplyDateTime,AttributeType=S --key-schema AttributeName=Id,KeyType=HASH AttributeName=ReplyDateTime,KeyType=RANGE --provisioned-throughput ReadCapacityUnits=5,WriteCapacityUnits=1 --region ap-southeast-2
Now, Inserting sample data to created tables using BatchWriteItem
$aws dynamodb batch-write-item --request-items file://forum.json --region ap-southeast-2
$aws dynamodb batch-write-item --request-items file://thread.json --region ap-southeast-2
$aws dynamodb batch-write-item --request-items file://reply.json --region ap-southeast-2
AWS Glue Crawler
Now we have tables and data, let’s create a crawler that reads the Dynamo tables.
Open the AWS Glue console, create a new database demo.
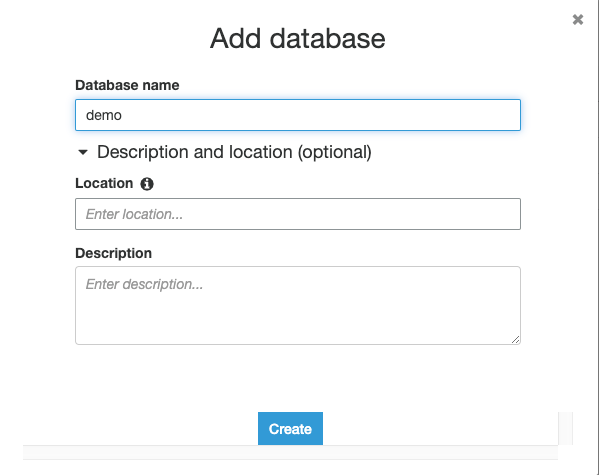
Then add a new Glue Crawler to add the Parquet and enriched data in S3 to the AWS Glue Data Catalog, making it available to Athena for queries.
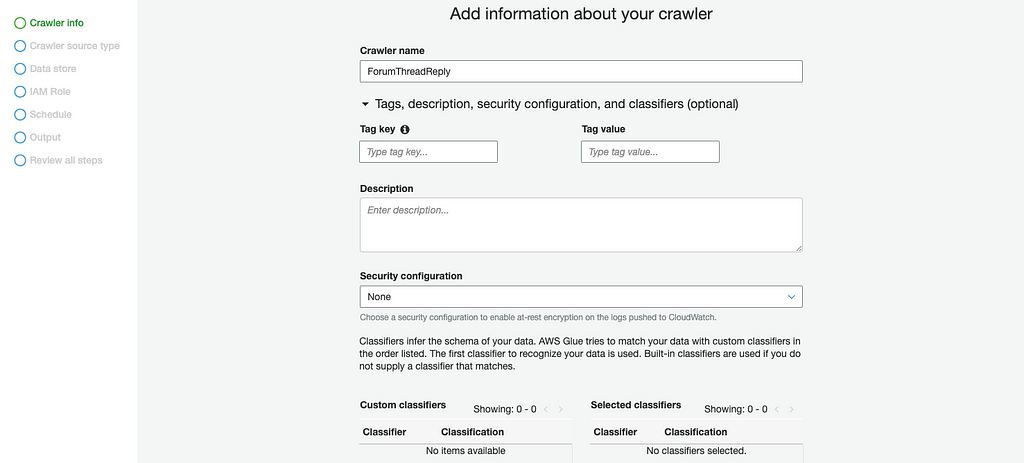

In Data stores step, select DynamoDB as data source and select Forum table:

A crawler can crawl multiple data stores in a single run, in our case we will need to add three tables as data store:

Next, select Create an IAM role and name the IAM role in IAM Role step:
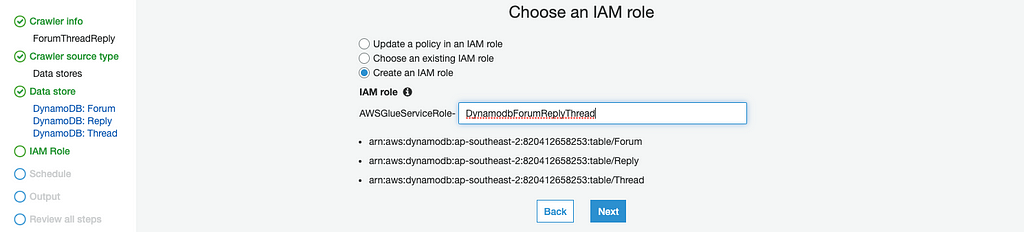
Then set schedule for the crawler, in our case i set to Run on demand :
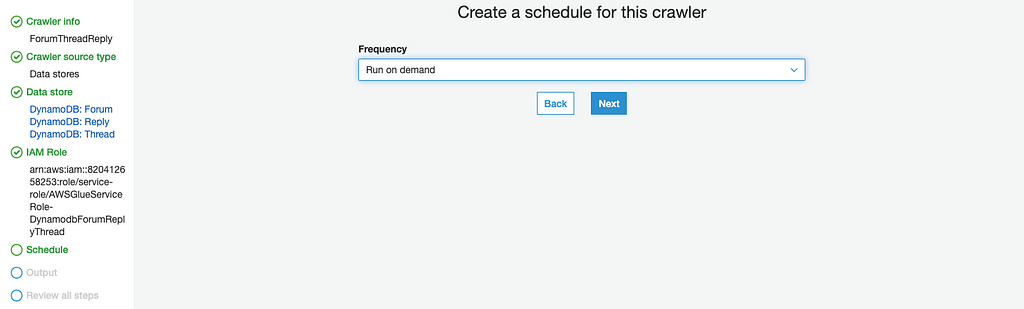
Select demo as Database and dynamodb as prefix tables on next step:
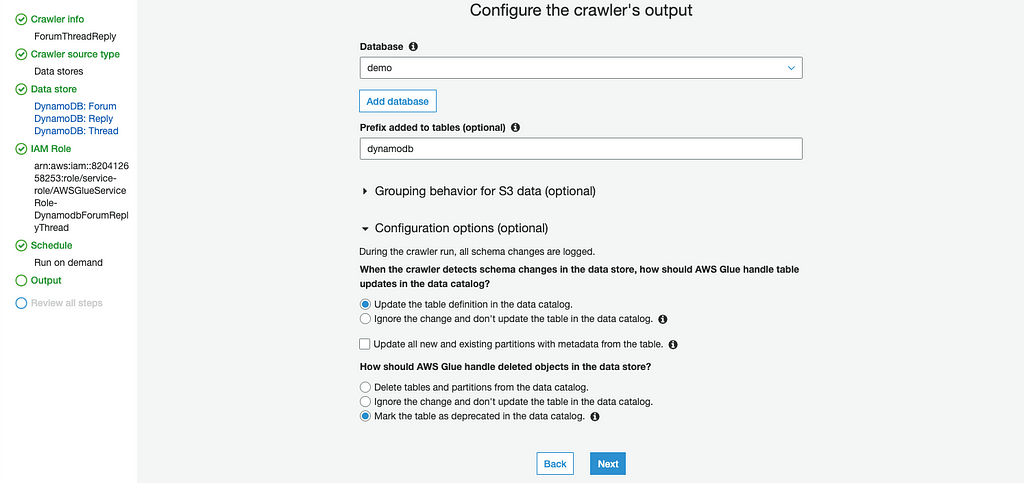
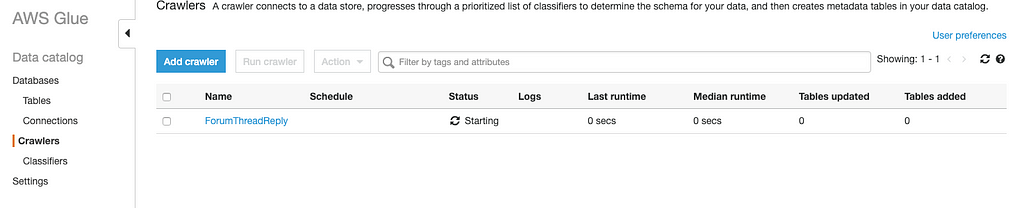
After Crawler added, we should see the crawler that were created in AWS Glue console, let’s run the Crawler:
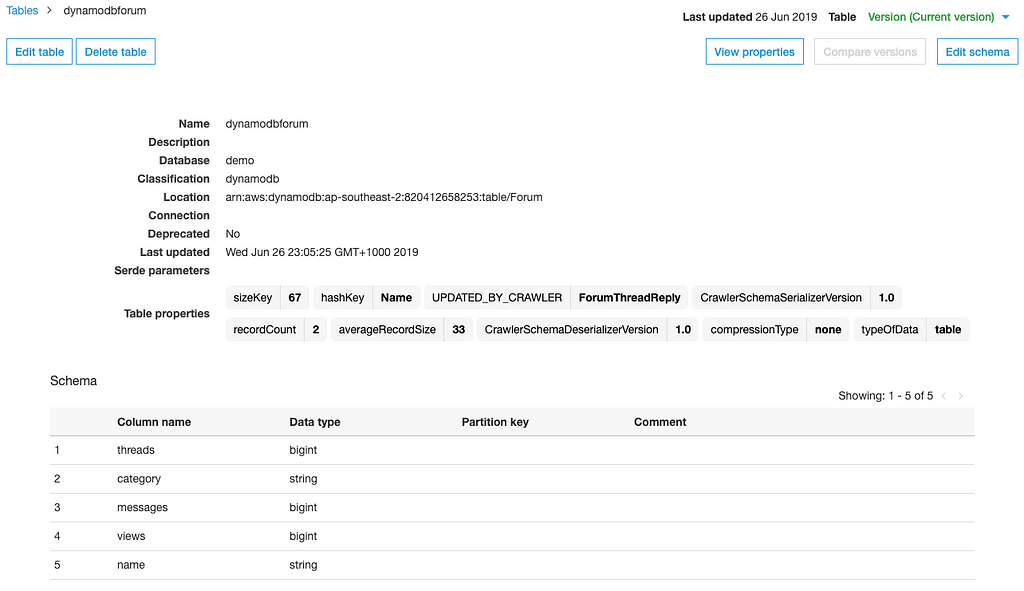
Upon completion, the crawler creates or updates one or more tables in our Data Catalog, we should see the tables created as below:

AWS Glue ETL Job
AWS Glue provides a managed Apache Spark environment to run your ETL job without maintaining any infrastructure with a pay as you go model.
AWS Glue ETL job extracts data from our source data and write the results into S3 bucket, let’s create a S3 bucket using CLI:
$aws s3api create-bucket --bucket aws-glue-forum.reply.thread.demos --create-bucket-configuration LocationConstraint=ap-southeast-2 --region ap-southeast-2
Open the AWS Glue console and choose Jobs under the ETL section to start creating an AWS Glue ETL job:
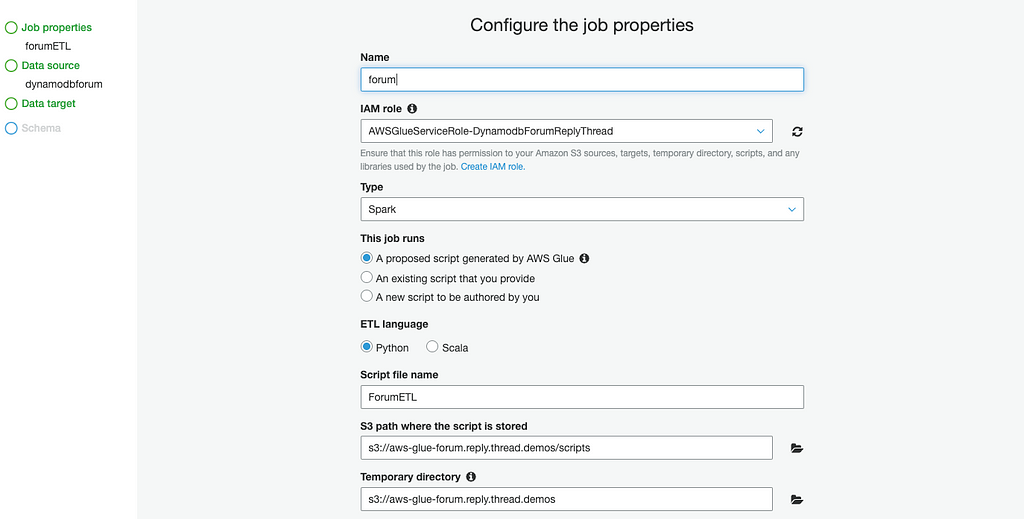
Select dynamodbforum data source in Data source step:
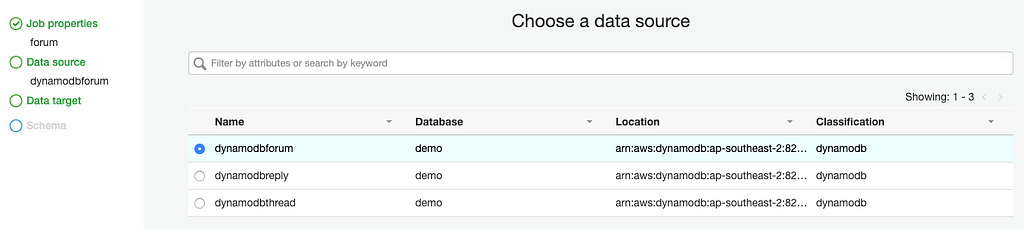
On the next step, choose your raw Amazon S3 bucket as the data source, and choose Next. On the Data target page, choose the processed Amazon S3 bucket as the data target path, and choose Parquet as the Format.
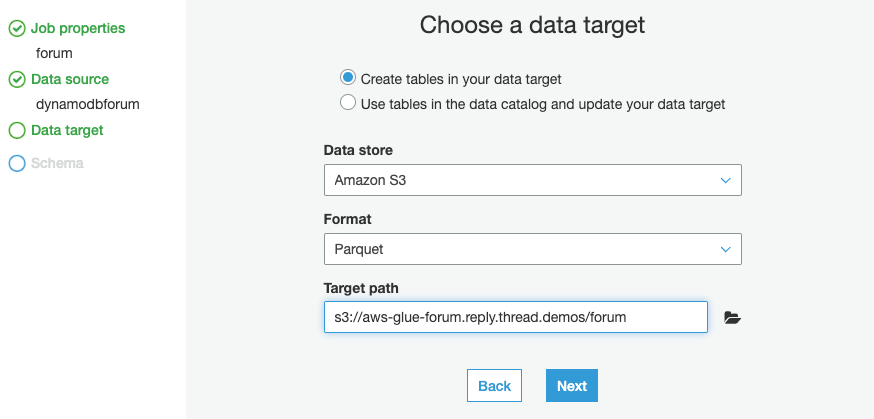
Lastly, review your job parameters, and choose Save Job and Edit Script, as shown following.
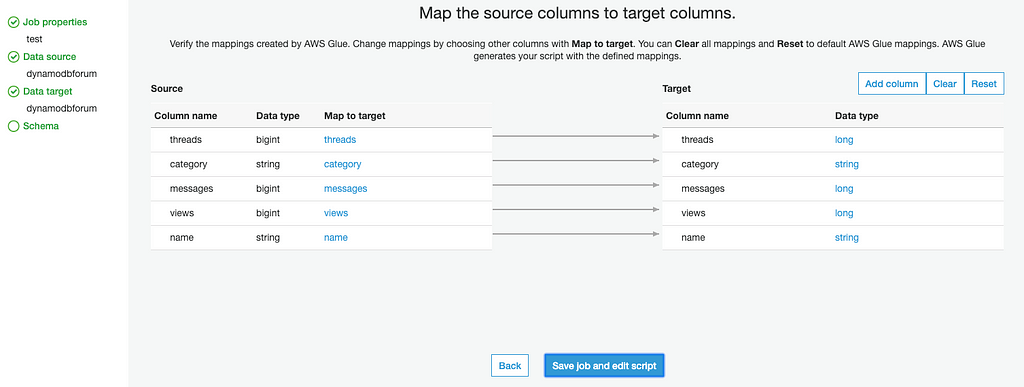
On the next page, we will need to modify the script to prevent duplicates data generated from each JOB execution, add following code to job script:
import boto3
s3 = boto3.resource('s3')bucket = s3.Bucket('aws-glue-forum.reply.thread.demos')bucket.objects.filter(Prefix="forum/").delete()Full script should look like:
Now, we have our forum ETL job created, repeat above steps to create other 2 jobs. Once three job created, we can automate the execution of this ETL jobs from Job trigger, in our case we will run all of the jobs manually:
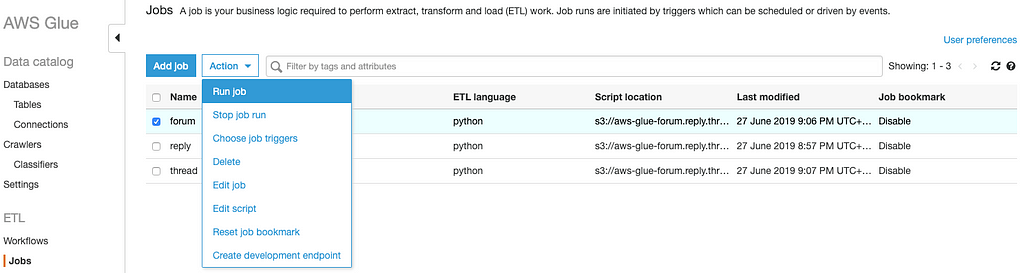
Okay all done! This is where the fun begins! Let’s create tables entry in AWS Glue for the resulting table data in Amazon S3, so you can analyze that data with Athena using standard SQL.
AWS Athena
Open AWS Athena console, choose demo database, we should be on a page similar to the one shown in the following screenshot:
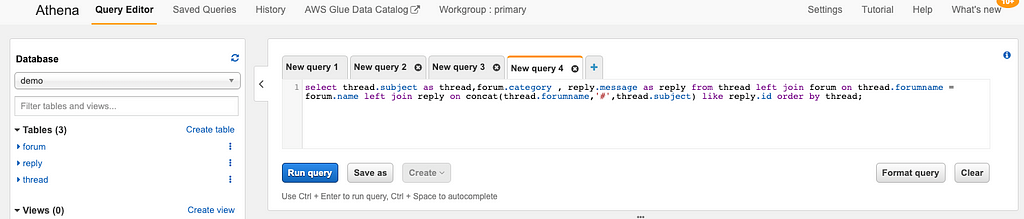
Paste following query to create three tables in query editor:
CREATE EXTERNAL TABLE IF NOT EXISTS demo.forum (`threads` bigint,`category` string,`messages` bigint,`views` bigint,`name` string)ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'WITH SERDEPROPERTIES ('serialization.format' = '1') LOCATION 's3://aws-glue-forum.reply.thread.demos/forum/'TBLPROPERTIES ('has_encrypted_data'='false');CREATE EXTERNAL TABLE IF NOT EXISTS demo.reply (`replydatetime` string,`message` string,`postedby` string,`id` string)ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'WITH SERDEPROPERTIES ('serialization.format' = '1') LOCATION 's3://aws-glue-forum.reply.thread.demos/reply/'TBLPROPERTIES ('has_encrypted_data'='false');CREATE EXTERNAL TABLE IF NOT EXISTS demo.thread (`views` bigint,`message` string,`lastposteddatetime` bigint,`forumname` string,`lastpostedby` string,`replies` bigint,`answered` bigint,`tags` array<string>,`subject` string)ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'WITH SERDEPROPERTIES ('serialization.format' = '1') LOCATION 's3://aws-glue-forum.reply.thread.demos/thread/'TBLPROPERTIES ('has_encrypted_data'='false');Now, try the following analytical queries against this data. Choose Run query to run each query, and view the output under Results.
Example query:
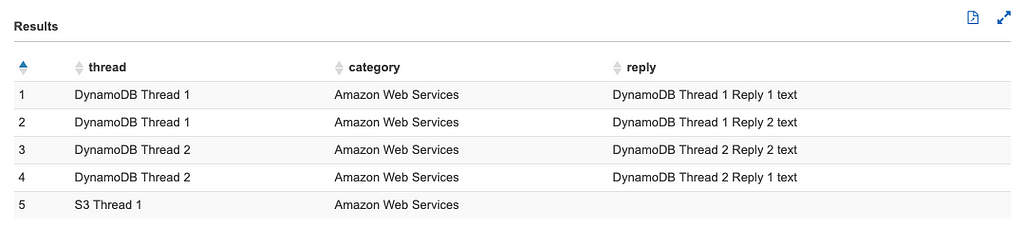
select thread.subject as thread,forum.category , reply.message as reply from thread left join forum on thread.forumname = forum.name left join reply on concat(thread.forumname,'#',thread.subject) like reply.id order by thread;
Example results:
Amazon Athena query engine is based on Presto. For more information about these functions, see Presto 0.172 Functions and Operators.
That’s about it! Thanks for reading! I hope you have found this article useful, You can find the complete project in my GitHub repo.
Building Serverless Data Lake with AWS Glue DynamoDB and Athena was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.