Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Although AWS Lambda is a blessing from the infrastructure perspective, while using it, we still have to face perhaps the least-wanted part of software development: debugging. In order to fix issues, we need to know what is causing them. In AWS Lambda that can be a curse. But we have a solution that could save you dozens of hours of time.
 Photo by Aron Visuals on Unsplash
Photo by Aron Visuals on Unsplash
Lambda & CloudWarch Logs Anatomy
AWS Lambda is essentially a managed container service. All works in the background — we don’t need to configure or manage containers themselves, or even the infrastructure behind them. But in reality, there are countless micro-containers running on top of traditional servers.
Whenever someone requests a Lambda function, AWS will use a micro-container to run our code, get the response and send back to the requester. During this process, our application — or any third-party libraries we’re using — can log anything from informational messages to deprecation warnings to error and exception stack traces. Where do all these logs go?
By the time they launched Lambda, AWS already had a logging service, which we know as CloudWatch. So, what they did is pipe all this text data (logs) from our applications running in Lambda into CloudWatch. Each Lambda function will have its dedicated “log group”. Think of it as a “repository” for that Lambda’s logs.
Inside a “log group” (or a single Lambda’s log repo), CloudWatch creates multiple “log streams”. Think of it as a text file where logs are actually written to. Every time a new micro-container is created by Lambda, a new log stream is also created in CloudWatch. It doesn’t matter if that container serves 1 or 100 requests, there will be only one log stream for it, which means: a single stream may contain logs from multiple invocations.
If multiple requests come in at the same time (a.k.a. concurrently), AWS will spin up multiple containers, creating also multiple log streams for the same Lambda. On top of that, each container might be around for several minutes, up to a few hours, and it can potentially serve thousands of requests, depending on how frequently your Lambda function is used.
The problem
Now imagine you noticed your application failed and you need to know what caused the issue in order to plan for a fix. Logs are the first thing to look, of course. But now you go to AWS CloudWatch and you know the error occurred today, sometime between 8:00 AM and 8:05 AM. Easy, right? It’s just a 5-minute period of time to look for. Well, here are the problems that might make you waste a lot of unproductive time.
First, there could be multiple log streams for that same period of time, so you need to browse them all to find a particular failed request. As if it wasn’t cumbersome enough, already, inside each log stream, you will need to browse maybe dozens, hundreds or even thousands of logs in order to find the one you’re looking for.
Remember the log stream isn’t necessarily created at the time a request comes in. The stream containing the failed request logs might have been created hours before, and it will contain a log of logs from prior to 8:00 AM.
It can take you a lot of time just to find the logs in CloudWatch. And you haven’t even started addressing the issue itself! Imagine someone from your team asking you how is it going with the bug fixing, you spent 30 minutes, maybe an hour, and still has no clue of what even caused the problem? One might argue that it’s unacceptable for a professional developer.
Solution
As I told you in the introduction, there’s a way to solve all this and get your logs much quicker.
 Photo by Mohamed Nohassi on Unsplash
Photo by Mohamed Nohassi on Unsplash
Every new invocation of a Lambda function will produce an initial logline. That’s logged by default, you can’t control it. And the log looks the same no matter what is your runtime (Python, Node, Java, etc). What’s handy is that this initial logline always looks like this:

The “START RequestId” is always the same, followed by a different hash on each invocation. Then there’s another default logline generated when an invocation is terminated, no matter whether it was successful or resulted in an error, and it looks like this:

So, now, we have a way to scan through any number of CloudWatch logs and identify where an invocation starts and ends. Cool.
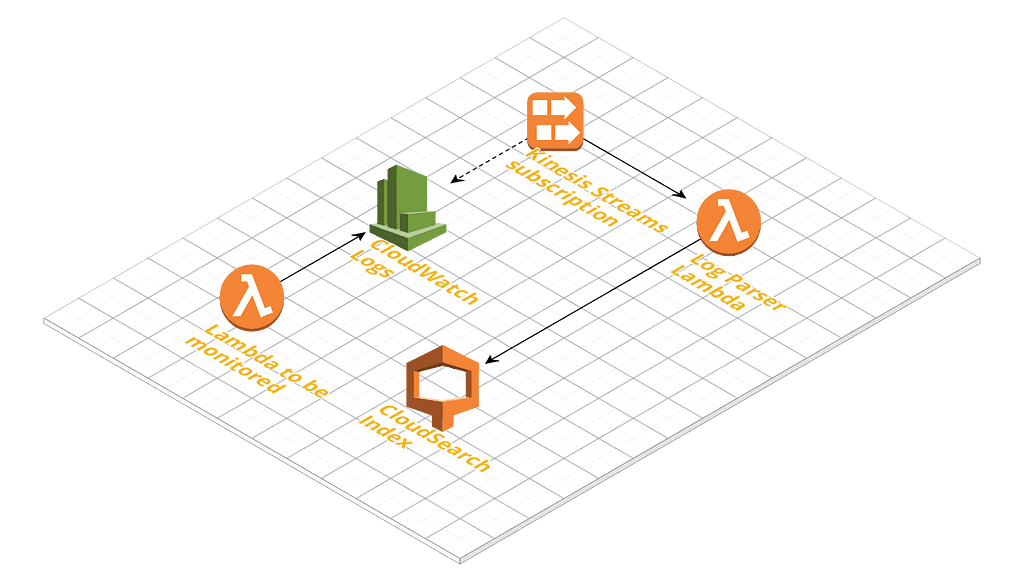
Now, another piece of knowledge that will be handy: CloudWatch Logs support subscriptions. It means you can subscribe AWS Kinesis to your logs so that it will listen to everything your Lambdas are outputting all the time. Then you can configure a special Lambda (call it “Log Parser”) to get automatically invoked when Kinesis receive new log data. Log Parser will get the logs and break them into invocations (use the START/END notation above to identify breaking points). Finally, each piece of log related to one, and only one invocation, can be saved individually in a database (such as CloudSearch) for later search and debugging.
Bam! You now have your logs individualized by invocation. No more unproductive sifting through thousands of logs to get just one invocation data. Here’s an illustrative diagram of this outlined implementation:
Implementing this solution in one minute
I know, it can take several hours (maybe a few days) to set this solution up and running, and it will require some effort over time to maintain and make sure it’s running smoothly.
Since we know you have plenty of other — more important — things to do, we have implemented this solution as a managed service, plus a bunch more features from anomaly detection to incident management and alerting. We called it Dashbird and thousands of developers already use and love it: we’re monitoring +200,000 Lambda functions and counting. You’re welcome to use it for free, for as long as you want.
How to Save Dozens of Hours on Lambda Debugging was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.