Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Recently, I was working on multiple crawlers for a few freelancing projects. These few projects data ranging from few thousand to a few millions of data. Therefore, it is important to create a web crawler which not only scale well but also not being block by the website.
Today I am going to share few tips on how to write an efficient web crawlers using Python.
Tip #1 Decrease the number of times you need to request a web page.
Using web scraping framework: Selenium as an example. If we want to scrape this website: https://www.yellowpages.com.sg/category/cleaning-services
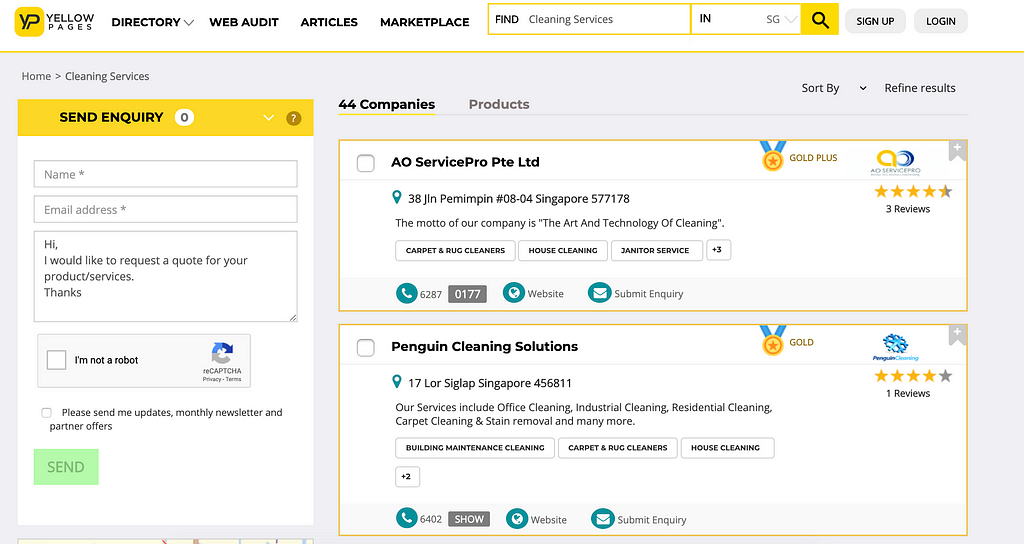
Let’s say, we want to get the data for address and description of the company. So, for Selenium, we might use driver.findElement twice to retrieve the address and description separately. A better way would be using driver to download the page source, and use BeautifulSoup to extract the data you need. In conclusion, hit the website once instead of twice to be less detectable!
Another situation is, when we are using WebDriverWait(driver, timeout, poll_frequency=0.5, ignored_exceptions=None) for waiting a page to load, remember to set poll_frequency(sleep interval between calls) to be higher to minimize the call to the webpage. More details you can read through this official doc!
Tip #2 Write the data to csv once one record is scraped
Previously when I was doing scraping, I will write the records once all records are being scraped, but this might not be the smartest way to complete the task.
A way instead is that after you scrape a record, you will need to write into the file, so that when problems occur ( for example your computer stop running, or maybe your program stop because of an error occurred), you can start from the website where the problem occur, to start your crawler/scraper again:)

For me I normally use python writerow function to write records to the output file, so that I am able to start from the website where I do not need to re-scrape all previous scrapped data if my scraper is stopped.
Tip #3 Reduce times of being blocked by the website
There are quite a lot of ways to implement stuff so that crawlers or scrapers won’t get blocked, but a good crawling framework will reduce your effort of implement them.
Main library I am using are Scrapy or Selenium. You can refer to this link for comparison between these two framework. I prefer Scrapy as it already implemented some of the ways to decrease times of being blocked by the website.
- Obey robots.txt, always check the file before scraping the website.
- Use download delay or auto throttling mechanism which already exist in Scrapy framework, to make your scraper/crawler slower.
- Best way is to rotate few IPs and also user agents to disguise your requests.
- If you are using scrapy-splash or selenium, random clicking and scrolling do help to mimic human behavior.
Refer to the below links for more information
Tip #4 Use api if the website provide

{kind=link}
For example, when you are trying to retrieve data from twitter, use twitter’s api instead of crawling or scraping twitter’s website, it will make your life more easier! But if you want the data which you can’t retrieve from the api given, then maybe you will still need to crawl the data.
Tip #5 Crawl google cache’s website instead of the original website
Given https://www.investing.com/ as an example:
You can access the cache version as shown below:
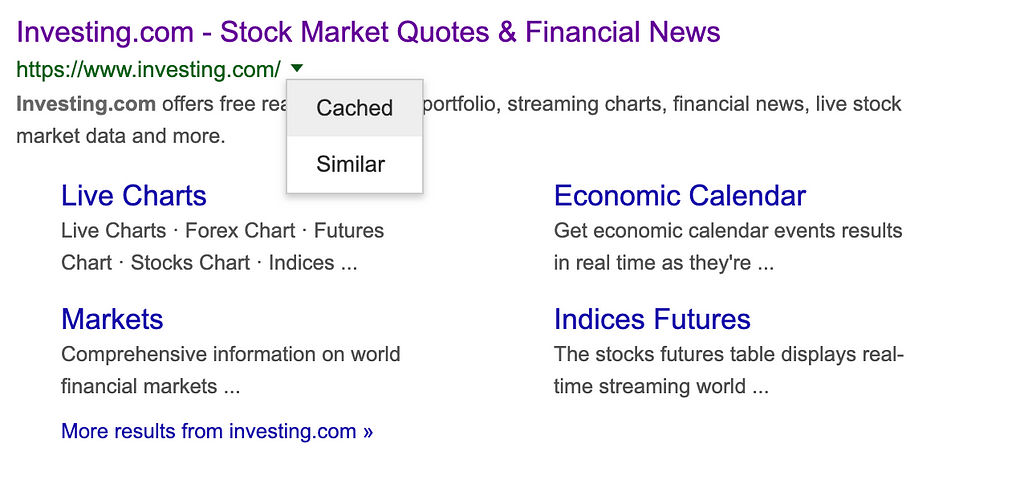
More information about google cache you can check on these websites:
If you are finding someone to help to scrape any website, please feel free to drop me a message:) Happy scraping!
5 Tips on creating an effective web crawler was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.