Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
The obvious and the not-so-obvious
 Let’s take that pipeline from a Pendolino to a Japanese Bullet Train
Let’s take that pipeline from a Pendolino to a Japanese Bullet Train
Continuous Integration and Continuous Delivery (CI/CD) is a staple of any software house worth its salt. It is a practice that has become so foundational in the industry that many of us can no longer imagine working without it. It is as basic as tests and every bit as useful. Yet, there are such a great variation of pipelines out there, some bad, some good, some insane. I’ve seen many of them.
I’ve been working with CI/CD systems for several years now and in my time, I’ve amassed a plethora of my own failures. Failures that have resulted in a little wisdom and a lot of grey hairs.
To start, I’ll go over some basic capabilities that your pipeline should have. I’ll mark the essentials, the nice to haves and the downright futuristic. Then we’ll talk about your Non-functionals. Speed, logging, error handling.
Just what the hell is CI/CD?
Before we get into the meat of this article, a quick overview. Back in the glory days of 1997, when Oasis were going strong and dressing like an undertaker was cool, two men came out with Extreme Programming. Kent Beck and Ron Jeffries. XP listed out a set of practices, principles and values that they believed would usher in a better world of software engineering. It was a sensational change.
First, CI.
While Continuous Integration (CI) had been proposed by Grady Booch in 1991, it was Kent and Ron that pushed it forward. In short, CI is taking all of the code and testing it, all the time. Constantly. The aim? To prove that the team aren’t drifting away from one another. To nip integration issues in the bud.
And CD.
Continuous Delivery was popularised by Jez Humble and David Farley. This is a two pronged principle:
- The code in the trunk (the master branch or the SVN trunk) should be deployable.
- Those deployments should be completely automated and should not require any manual steps.
Together, they’re awesome.
That’s it, CI/CD is constantly packaging, testing and easily deploying code into a production environment. This has the advantage of eliminating integration issues and mitigating risk in deployments by making them more frequent.
So, what should a pipeline do?
I’m glad you asked. Each of the features I have included here are necessary to realise the benefits of a CI/CD pipeline. I have tried to be exhaustive, but expect some variation.
Tests
It should run some tests against your code. This one is obvious. Wanna know your code is working? Run some damn tests.
Packaging
It should be building some kind of deployable artifact. Again, obvious. You’re planning on deploying this, aren’t you? You need an artifact.
Security Scanning
This one raises a few eyebrows, but having implemented this, I have decided it is going on the “must have” list. Code and artifact scanning provide indispensable feedback. OWasp can scan your dependencies. Tenable can scan your containers. Checkmarx can take a look at your code. The specific tool isn’t what is important. What matters is the capability. You need to know when a SQL injection vulnerability pops up. Your tests might pass but your code isn’t production ready because it’s insecure.
 What’s this trojan.ru file in your /tmp directory?
What’s this trojan.ru file in your /tmp directory?
Don’t offload that responsibility onto an Ops department or your InfoSec team. Own the problem and visualise it using automation. By baking security scanning into your pipeline, you’re generating vast streams of data. Those streams can be used in a crisis or in day to day debugging.
Deployment of Applications to ALL ENVIRONMENTS
I was once told that all deployments except production were automated because we couldn’t risk it for our production environments. Their deployments were so convoluted that they didn’t want to “risk” automating it. Deciding instead to leave it to the ever reliable human mind.
Don’t shy away because you’re feeling nervous. If you’ve got a simple deployment process, automation is easy. If you’ve got a complex process, it’s an absolute necessity. There’s no way out. Automate, automate, automate.
Post deployment checks
Once you’ve got that deployment out, how do you know it’s working? One key ingredient to a robust pipeline is a sanity check. This can take the form of a smoke test, or something more rigorous. You might issue a HTTP call to your API and check it returns with a 2xx status code. Whatever — don’t just assume your deployment was peachy because your app has started up.
Notifications All together now - my deployment just failed!!
All together now - my deployment just failed!!
Whether your build has failed or succeeded, a notification should be issued by the pipeline. This should be sent to the medium that your engineers use most frequently. Don’t clog up people’s email inboxes — all they’ll do is make a rule and hide them away in a random folder. Push them into IM (and into any auditing solution). Slack, Microsoft Teams (sigh),
Good error messages
The best way to talk about good error messages is to start with an unclear error message.
Error: "nginx-ingress" has no deployed releases
This is really obvious if you know about helm — if you have already seen this issue before. Alas, our error messages shouldn’t be aimed at only the people who know. It should be easily understood by everyone. So on the face of it, this message isn’t all that clear is it? I deployed my last release. It is deployed… I think. If you were to run helm list you’d see something like:
NAME REVISION UPDATED STATUS
nginx-ingress 6 Fri May 3 11:19:45 2019 FAILED
The problem with the error message is that it offers no context or instruction. These are two completely essential ingredients. What does this mean, what is the impact? And what should you do? With these in mind, a more useful error message is something like this:
Your application can not be deployed because it is in a failed state. You can verify this using the helm list command. You should rollback to a previous working revision, using the helm rollback command.
The first sentence here provides the context — the application is in the wrong state. That’s the root cause. It also offers diagnostic assistance, should you want to verify this issue yourself. Context.
The second portion of this error message offers instruction for remediation. Instead of following some ancient confluence document, the instructions are right there in the code. A good error message can remove the need for extensive tutorials and how-to guides. It can eliminate costly googling and create living, responsive documentation in the code that won’t go stale. It’s worth spending the time getting those right.
Metrics
The last one is metrics. It is helpful to know how many deployments are failing, how many are succeeding, how long builds are taking, where the choke points are etc. There is a wealth of information for your team to dig into and understand.
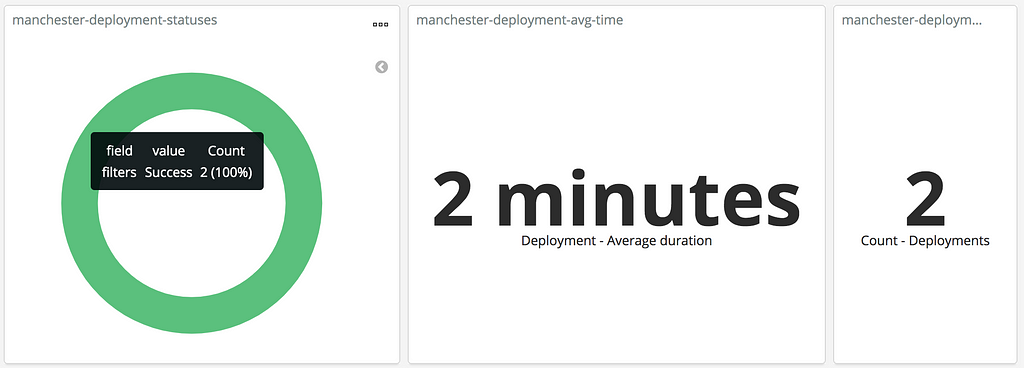 Understanding metrics like these unlock true team improvement.
Understanding metrics like these unlock true team improvement.
This data is the lifeblood of your team — the metrics represent your team’s ability to deliver software changes. If you can surface it, you’re sitting on a goldmine of information.
CI/CD is just one of my topics I ramble about on my twitter account.
CI/CD Ingredients for Success was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.