Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
How to choose optimal hardware for neural network inference. Study of AWS GPUs and Elastic Inference Accelerators.
I measured the performance of various AWS hardware options in 4 different neural architectures with a focus on inference. Here’s what I found.
What’s the rush?

AWS offers a wide range of GPU devices for neural network inference and training. Here is a well-known fact: 90% of neural network costs are for neural network inference (actually using them) and only 10% goes for training. So, optimizing inference has a bigger impact on the business unit economy. I run an AI department at Skylum Software and we do offer of neural network based image processing in our cloud solution for big B2B businesses. Naturally, the costs of inference are of importance for us.
Saving money on neural network inference consists of few stages.
First is, of course, optimizing neural networks themselves. There’s a variety of techniques — pruning and distilling, quantization is a few main ones. I am not going to cover that here. Another one is transferring calculations to float16 precision, which required specific software — there are few examples of that here. Another one is choosing optimal hardware for inference.
Why is this non-obvious?
The point here is simple. GPU’s and software that we use for training were optimized for training, not inference. GPU’s have a lot of memory, to store big batches of training samples as well as gradients for backpropagation. When we have a steady stream of data in batches we are able to make use of that fast and big memory and archive close to 100% GPU power utilization.Often during inference, we are not able to get enough data to pack them in a steady stream of batches. Waiting for enough data will lead to delays that are deadly for business. So, the real-world inference is likely to work with small batches of samples (1–4) and focus on latency. This under-utilizes the GPUs power and make them inefficient. Often, but not always.
Amazon’s AWS solution
Amazon came up with their solution to the aforementioned problem — Elastic Inference Accelerators. Those are devices of unknown (at least to me) architectures and are focused specifically on doing fast inference of small batches of data. They are equipped with much less memory (1Gb-4Gb) and less processing power than GPUs but are much cheaper.
Perfomance and cost-saving analysis.
Choice of hardware and models.
To make this study I’ve chosen 4 hardware setups:
- p2.xlarge. Oldest GPU offering.
- p3.4xlarge. Top-notch GPU cards with full float16 support.
- g3.4xlarge. GPU with limited memory (8Gb) and focused on 3D acceleration of software. Non-obvious, but very interesting device.
- eia.large. Biggest (4Gb) AWS offering of their Elastic Accelerators.
For neural networks architecture I’ve chosen 4 most typical solutions — 2 for image classification and 2 for pix2pix image transformations:
- VGG19. Oldest and very well studied archtecture, while slow and bulky.
- ResNet50. The basic structure for most modern applications in image classification.
- UNet. Slow, but efficient architecture for image segmentation.
- EDSR. The typical neural network used for tasks like image superresolution.
Elastic inference has a special set of requirements for the software. Currently, AWS supports two frameworks — Google’s TensorFlow and Amazon MXNet. As I have most of my codebase in MXNet I stuck to it.
Measurement results of classification networks.
Let’s first a look at how different hardware behaves with a scaling of batch size at two very different architectures — VGG19 and ResNet50.
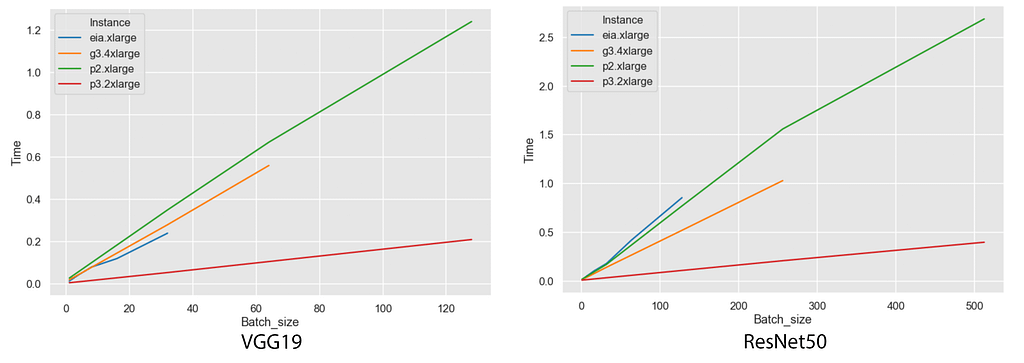 VGG19 and ResNet50 performance on different AWS hardware
VGG19 and ResNet50 performance on different AWS hardware
WOW! That’s interesting. They all scale almost linearly with batch size increase (until they run out of memory) and p3.2xlarge is a leader in performance. The comparison of GPU-based hardware is as expected according to NVIDIA specifications and AWS pricing.
But, Elastic Inference Accelerator behaves differently. It is slower than everything in ResNet50, but performs better with VGG19. This gives us a clue — it has some kind of hardware optimizations for certain types of architectures and operations.
But, these graphs don’t give us an answer for inference performance for lowest batch possible — 1. This is of interest for actual production performance. Let’s take a look at that.
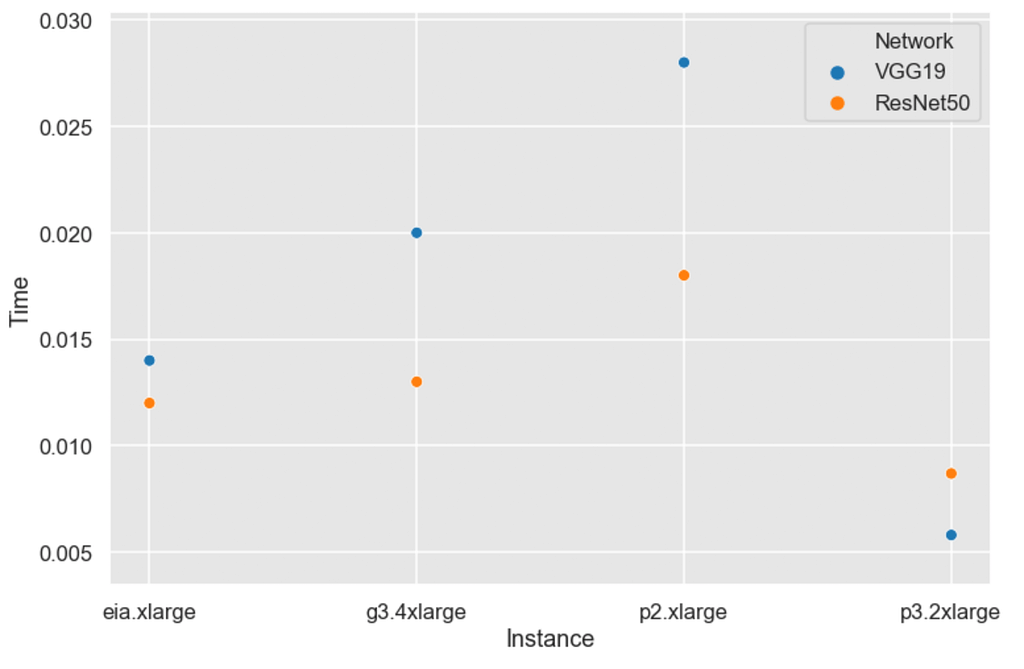 Batch=1 performance
Batch=1 performance
Another WOW! This is what Elastic Inference is made for! Here, EIA clearly gets second place. p3.2xlarge is about 2 times faster while being 6 times for expensive. No brainer here — stick to EIA if a 10ms performance gain is negligible for you. But still, keep in mind that throughput will be 2x less (month-wise) while being 6x cheaper.
For this type of task (classification) you should also try lower memory EIA instance — I suppose even more money is saved there and 10–15ms inference speed is a great number.
I’ve also tested inference on float16, but performance gains were negligible in this case.
Image segmentation and superresolution.
Those are different beasts. UNet is usually used on a higher resolution image, 224 pixels are not enough for high-quality segmentation. So, I tried a range of resolutions. To make data representative, I took the square of resolution — number of follows ^2 rule.
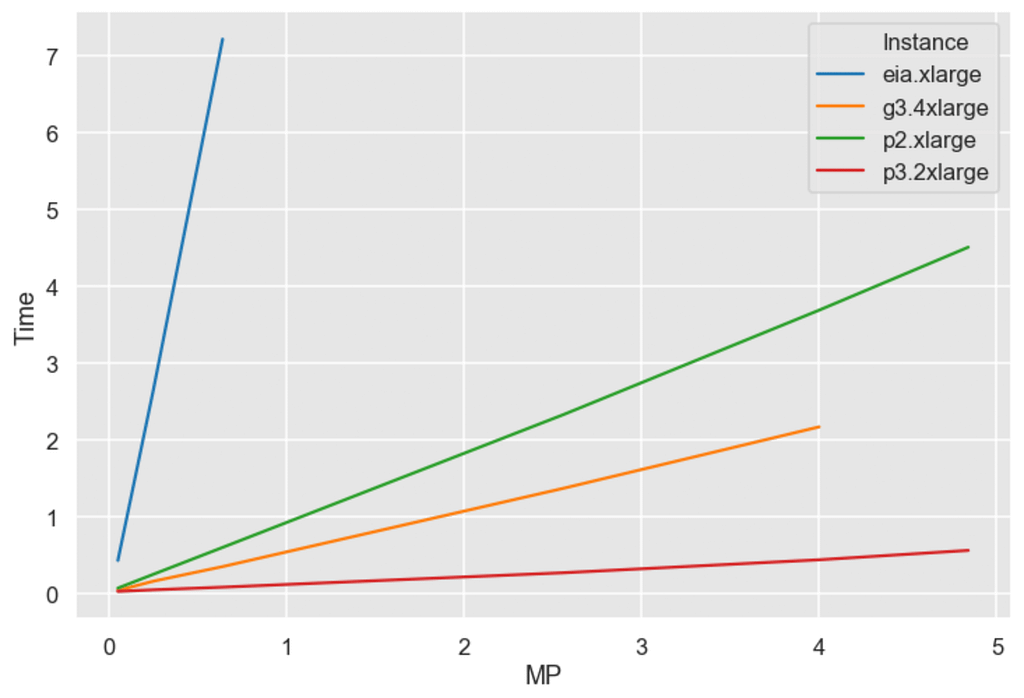 Image megapixels to inference time
Image megapixels to inference time
All hardware follows a linear trend of the time to megapixels and Elastic Inference start to lose more notably. Let’s take a closer look at a realistic scenario of making image segmentation with 500x500 pixels image.
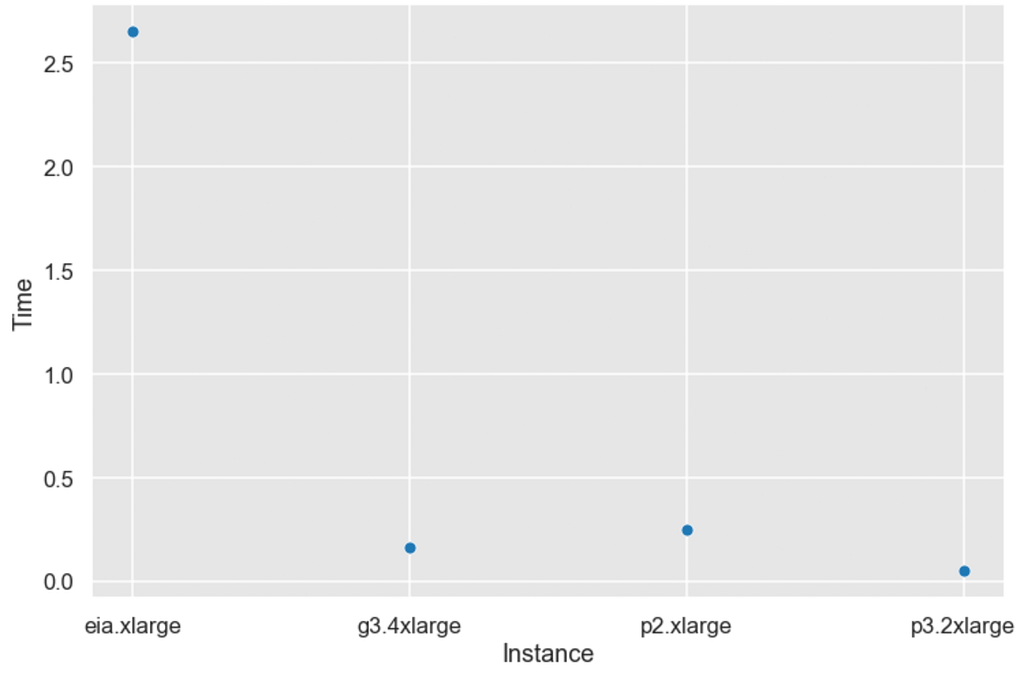
Oh, wow! UNet isn’t created for Elastic Inference at all. Money-wise single inference price is following:
- EIA.xlarge = 0.001531 USD
- g3.4xlarge = 0.000203 USD
- p2.xlarge = 0.000250 USD
- p3.2xlarge = 0.000163 USD
Here, P3.2xlarge comest cheapest if your business provides a steady load of jobs and 3k/month doesn’t scare you off.
EDSR and super-resolution
This is another interesting edge case.
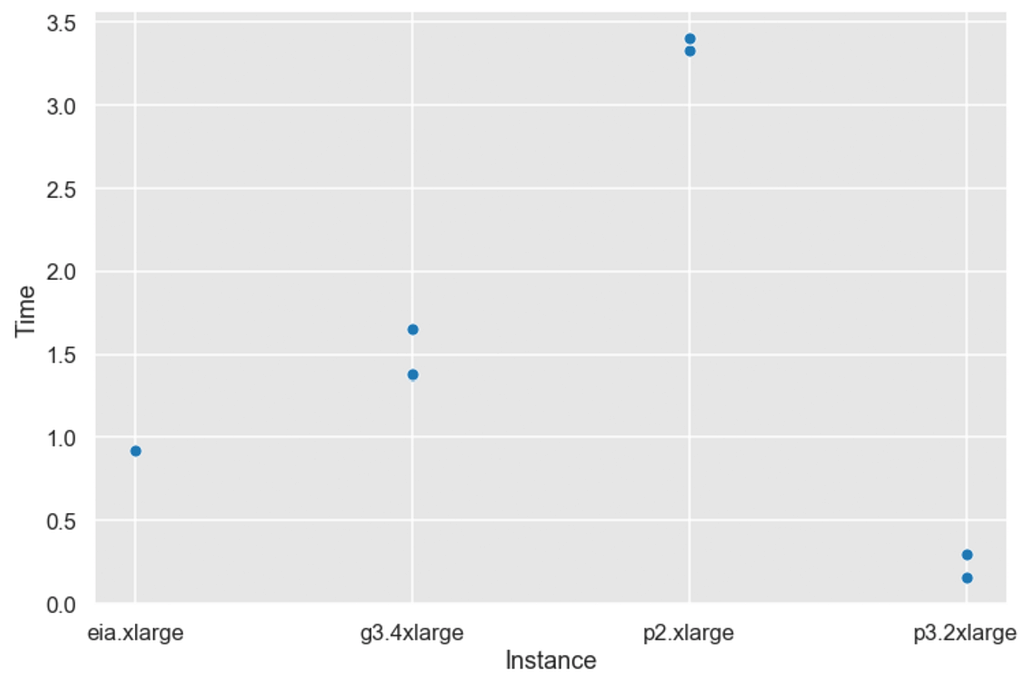
EIA performance is much better with EDSR architecture (that is actually ResNet based). EIA is a clear winner here. But wait, you remember about float16 capabilities of p3.2xlarge? This is a case, where this can be helpful. Here’s a cost of single 500px x 500px inference.
- EIA.xlarge = 0.000133 USD
- g3.4xlarge = 0.000522 USD
- p2.xlarge = 0.000833 USD
- p3.2xlarge (float32)= 0.000252 USD
- p3.2xlarge (float16)= 0.000130 USD
EIA in full precision is on par with p3.2xlarge running in half-precision mode. Again, if you can use fp16 and your business has a steady stream of data — stick to p3. Otherwise, EIA will give you significant costs benefits.
Nota Bene
- During measurement, I did 11 inference cycles and took the mean time of the last 10 measurements. The first run of inference is always much (10x) slower due to mechanics.
- I was able to run EIA in float16 mode to the best of my knowledge but never obtained any speed gains.
I am sharing all raw data for 200 measurement and data points for the better good.
Don’t forget to clap, share and contact me if any questions arise.
How to choose optimal hardware for neural network inference. was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.