Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.

AWS Lambda plus Layers is one of the best solutions for managing a data pipeline and for implementing a serverless architecture. This post shows how to build a simple data pipeline using AWS Lambda Functions, S3 and DynamoDB.
What this pipeline accomplishes?
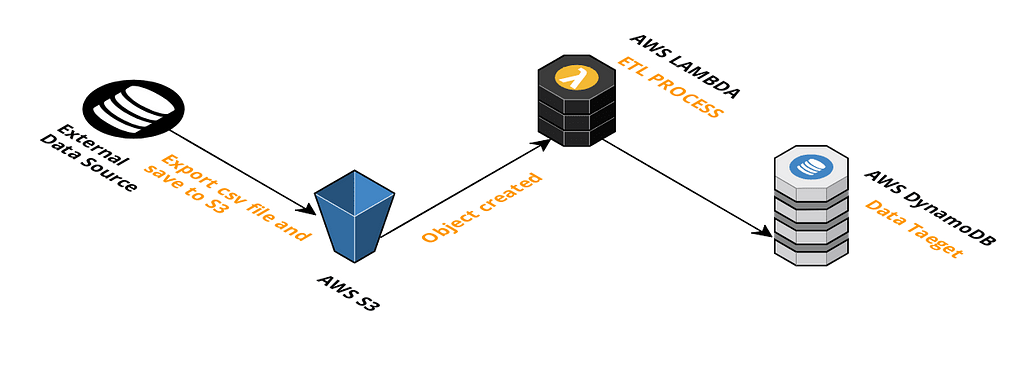
Every day an external datasource exports data to S3 and imports to AWS DynamoDB table.
Prerequisites
- Serverless framework
- Python3.6
- Pandas
- docker
How this pipeline works
On a daily basis, an external data source exports data of the pervious day in csv format to an S3 bucket. S3 event triggers an AWS Lambda Functions that do ETL process and save the data to DynamoDB.
 Install Serverless Framework
Install Serverless Framework
Before getting started, Install the Serverless Framework. Open up a terminal and type npm install -g serverless to install Serverless framework.
Create a new service
Create a new service using the AWS Python template, specifying a unique name and an optional path.
$ serverless create --template aws-python --path data-pipline
Install Serverless Plugin
Then can run the following command project root directory to install serverless-python-requirements Plugin,
$ serverless plugin install -n serverless-python-requirements
Edit the serverless.yml file to look like the following:
plugins: - serverless-python-requirementscustom:pythonRequirements:dockerizePip: non-linuxlayer: true #Put dependencies into a Lambda Layer.
You need to have Docker installed to be able to set dockerizePip: true or dockerizePip: non-linux.
Add S3 event definition
This will create a dev.document.files bucket which fires the importCSVToDB function when an csv file is added inside the bucket.
functions:importCSVToDB:handler: handler.importCSVToDBlayers: - {Ref: PythonRequirementsLambdaLayer}environment:documentsTable: ${self:custom.documentsTableName}bucketName: ${self:custom.s3bucketName}events: - s3:bucket: ${self:custom.s3bucketName}event: s3:ObjectCreated:Putrules: - suffix: .csvFull sample serverless.yml as below:
Add Lambda function
Now, let’s update our handler.py to create the pandas dataframe from the source csv in S3 bucket, convert dataframe to list of dictionaries and load the dict object to DynamoDB table using update_item method:
As you can see from above lambda function, We use Pandas to read csv file, Pandas is the most popular data manipulation package in Python, and DataFrames are the Pandas data type for storing tabular 2D data.
Let’s deploy the service and test it out!
$ sls deploy --stage dev
To test the data import, We can manually upload an csv file to s3 bucket or using AWS cli to copy a local file to s3 bucket:
$ aws s3 cp sample.csv s3://dev.document.files
And there it is. You will get data imported into the DynamoDB DocumentsTable table.
You can find complete project in my GitHub repo:
AWS Data Pipeline
Alternatively, You can use AWS Data Pipeline to import csv file into dynamoDB table
AWS Data Pipeline is a web service that you can use to automate the movement and transformation of data. With AWS Data Pipeline, you can define data-driven workflows, so that tasks can be dependent on the successful completion of previous tasks. You define the parameters of your data transformations and AWS Data Pipeline enforces the logic that you’ve set up.
What is AWS Data Pipeline? - AWS Data Pipeline
Learn more
- Building a Fully Serverless Realtime CMS using AWS Appsync and Aurora Serverless
- How To Add NodeJs Library Dependencies in a AWS Lambda Layer With Serverless Framework
- End to End Testing React apps with Selenium Python WebDriver Chrome PyTest and CircleCI
- Running Selenium and Headless Chrome on AWS Lambda Layers
Building a Serverless Data Pipeline with AWS S3 Lamba and DynamoDB was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.