Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
TLDR;
- DynamoDB is great, but partitioning and searching are hard
- We built alternator and migration-service to make life easier
- We open sourced a sidecar to index DynamoDB tables in Elasticsearch that you should totes use. Here’s the code.
When we embarked on Bitbucket Pipelines more than three years ago we had little experience using NoSQL databases. But as a small team looking to produce quality at speed, we decided on DynamoDB as a managed service with great availability and scalability characteristics. Three years on, we’ve learnt a lot about how to use and how to not use DynamoDB, and we’ve built some things along the way that might be useful to other teams or that could be absorbed by the ever growing platform.
To NoSQL or not to NoSQL that is the question
First off the bat, relational databases aren’t werewolves and NoSQL isn’t a silver bullet. Relational databases have served large scale applications for years and they continue to scale well beyond many people’s expectations. Many teams in Atlassian continue to choose Postgres over DynamoDB for example and there are plenty of perfectly valid reasons to do so. Hopefully this blog will highlight some of the reasons to choose one technology over the other. At a high level they include considerations such as operational overhead, the expected size of your tables, data access patterns, data consistency and querying requirements.
Partitions, partitions, partitions
A good understanding of how partitioning works is probably the single most important thing in being successful with DynamoDB and is necessary to avoid the dreaded hot partition problem. Getting this wrong could mean restructuring data, redesigning APIs, full table migrations or worse at some time in the future when the system has hit a critical threshold. Of course there is zero visibility in to a table’s partitions — you can calculate them given a table’s throughput and size but it’s inaccurate, cumbersome and we’ve found, largely unnecessary if you’ve designed well distributed keys as the best practices developer guide suggests. Fortunately we took the time to understand partitioning from the get go and have managed to avoid any of these issues. As an added bonus, we’re now able to utilize autoscaling without concern for partition boundaries because requests remain evenly distributed even as partitions change and throughput is redistributed between them.
Throughput, bursting and throttling
Reads and writes on DynamoDB tables are limited by the amount of throughput capacity configured for the table. Throughput also determines how the table is partitioned and it affects costs so it’s worth ensuring you’re not over provisioning. DynamoDB allows bursting above the throughput limit for a short period of time before it starts throttling requests and while throttled requests can result in a failed operation in your application, we’ve found that it very rarely does so due to the default retry configuration in the AWS SDK for DynamoDB. This is particularly reassuring because autoscaling in DynamoDB is delayed by design and allows throughput to exceed capacity for long enough that throttling can occur.
DynamoDB auto scaling modifies provisioned throughput settings only when the actual workload stays elevated (or depressed) for a sustained period of several minutes. The Application Auto Scaling target tracking algorithm seeks to keep the target utilization at or near your chosen value over the long term.
Sudden, short-duration spikes of activity are accommodated by the table’s built-in burst capacity.
You’ll still want to set alerts for when throughput is exceeded so you can monitor and act accordingly when necessary (e.g. there’s an upper limit to autoscaling) but we’ve found that burst capacity, default SDK retries, autoscaling and adaptive throughput combine extremely effectively such that intervention is seldom required.

Alternator: an object-item mapping library for DynamoDB
After Pipelines got the green light and refactoring of the horrendous alpha code began, one of the first things we built was alternator: an internal object-item mapping library for DynamoDB (similar to an ORM). Alternator abstracts the AWS SDK from the application and provides annotation based, reactive (RxJava — although currently still using the blocking AWS API under the covers until v2 of the SDK becomes stable) interfaces for interacting with DynamoDB. It also adds circuit breaking via Hystrix removing much of the boilerplate code that was present in early versions of the system.
@Table( name = “pipeline”, primaryKey = @PrimaryKey(hash = @HashKey(name = “uuid”)))
@ItemConverter(PipelineItemConverter.class)public interface PipelineDao { @PutOperation(conditionExpression = “attribute_not_exists(#uuid)”) Single<Pipeline> create(@Item Pipeline pipeline);}The migration service
DynamoDB tables are of course schema-less, however that doesn’t mean that you won’t need to perform migrations. Aside from a typical data migration to add or change attributes in a table, there are a number of features that can only be configured when a table is first created such as local secondary indexes which are useful for querying and sorting on additional attributes other than the primary key.
The first few migrations in Pipelines involved writing bespoke code to move large quantities of data to new tables and synchronizing that with often complex changes in the application to support both old and new tables to avoid downtime. We learnt early on that having a migration strategy would remove a lot of that friction and so the migration service was born.
The migration service is an internal service we developed for migrating data in DynamoDB tables. It supports 2 types of migrations:
- Same table migrations for adding to or amending data in an existing table.
- Table to table migrations for moving data to a new table.
Migrations work by scanning all the data in the source table, passing it through a transformer (that is specific to the migration taking place) and writing it to the destination table. It does this using a parallel scan to distribute load evenly amongst a table’s partitions and maximize throughout to complete the migration in as short a time as possible.
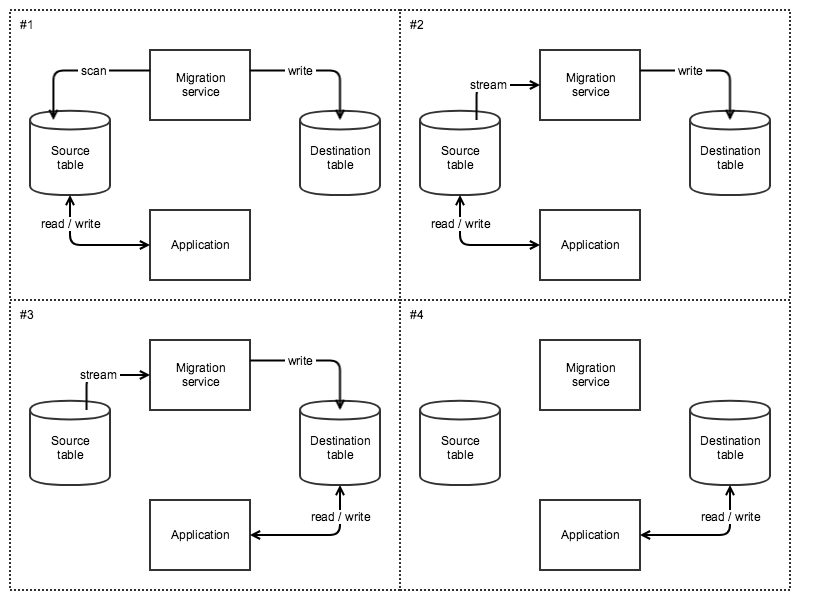
Table to table migrations then attach to the source table’s stream to keep the destination table in sync until you decide to switch over to using it. This allows the application to switch directly to using the new table without having to support both old and new tables during the migration.
Querying in DynamoDB: a tale of heartache and misery
DynamoDB provides limited querying and sorting capability via local and global secondary indexes. Tables are restricted to five local secondary indexes, with each index sharing the same partition key as the table’s primary key, and a query operation can only be performed against one index at a time. This means that on a “user” table partitioned by email address, a query operation can only be performed in the context of the email address and one other value.
Global secondary indexes remove the partition key requirement at the cost of paying for a second lot of throughput, and only support eventually consistent reads. Both types of indexes are useful and sufficient for many use cases and Pipelines continues to use them extensively but they do not satisfy the more complex querying requirements of some applications. In Pipelines this need predominantly came from our REST API which rather typically allows clients to filter and sort on multiple properties at the same time.

Our solution
Our first attempt at solving this problem, MultiQuery, was built in to an alternator. With this approach we queried multiple local secondary indexes (LSI) and aggregated the results in memory allowing us to perform filtering and sorting on up to five values (the maximum number of LSI) in a single API request. While this worked at the time, it started to suffer from pretty terrible performance degradation as our tables grew in size and exponentially so the more values you were filtering on. Before multi query was replaced, the pipelines list page on our end-to-end test repository (one with a large number of pipelines) took up to tens of seconds to respond and consistently timed out when filtering on branches.
A common pattern for searching DynamoDB content is to index it in a search engine. Conveniently AWS provides a logstash plugin for indexing Dynamo tables in Elasticsearch so we set about creating an indexing service using this plugin and the results were encouraging. Query performance vastly improved as expected but the logstash plugin left a lot to be desired taking almost 11 hours to index 700,000 documents.
Some analysis of the logstash plugin and the realization that we had already built what was essentially a high performance indexer in the migration service led us to replace the logstash plugin with a custom indexer implementation. Our indexer, largely based on the same scan/stream semantics of the migration service and utilizing Elasticsearch’s bulk indexing API, managed to blow through almost 7 million documents in 27 minutes.
The indexer sidecar
The custom indexer has since been repackaged as a sidecar, allowing any service application to seamlessly index a DynamoDB table in Elasticsearch. Both the initial scan and ongoing streaming phases are made highly available and resumable by a lease / checkpointing mechanism (custom built for the scan, standard kinesis client for the stream).
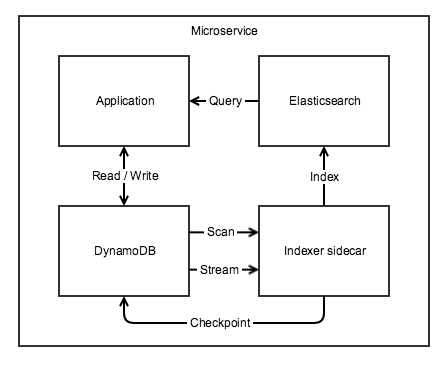
We currently utilize the excellent elasticsearch client built by the Bitbucket code search team to query the index and have started work on an internal library which adds RxJava and Hystrix in the same vein as alternator.
Here is the repo with the code and a readme.
Final thoughts
If you haven’t used NoSQL before, it certainly requires a mind shift but overall our experience with DynamoDB has been a positive one. The platform has proven to be extremely reliable over the past three years (I can’t remember a single major incident caused by it) with our biggest challenge coming from our querying requirements. Some might say that’s reason enough to have chosen a relational database in the first place and I wouldn’t strongly disagree with them. But we’ve managed to overcome that issue with a solution that is for the most part abstracted away from day to day operations. On the plus side, we haven’t had to run an explain query in all that time or deal with poorly formed SQL, complex table joins or missing indexes and we’re not in a hurry to go back.
This post was written by Sam Tannous. Sam is a senior software engineer at Atlassian and is part of the team that brought CI/CD Pipelines to Bitbucket cloud. With over 15 years industry experience he has co-authored 3 patents, maintains 1 open source project and has a track record of successfully delivering large scale cloud based applications to end users. Connect with him on linkedin.
Originally published at bitbucket.org on March 28, 2019.
Searching DynamoDB: An indexer sidecar for Elasticsearch was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.