Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
From hybrid cloud flexibility to containerization, supporting the 11.11 Global Shopping Festival has taken relentless innovation from Alibaba’s database team.
For Alibaba Group, preparing to support peak data traffic during the annual 11.11 Global Shopping Festival is a yearlong challenge, at the center of which demand for database flexibility has been a perennial feature.
As a widely used data storage system, Alibaba’s database consumes IO and CPU resources to perform operations involved with its SQL requests, including physical read, logical read, and sorting and filtering. With different services’ SQL requests consuming different resources according to their execution plans, the demand for resource specification varies by service.
To improve overall utilization, Alibaba must abstract resource specifications to enable database instances of different resource demands to better mix and run together on physical machines. Drawing on insights from Alibaba Senior Staff Engineer Chen Changcheng(陈长城), this article explores how the Group has ventured to give its database this all-important flexibility through continuing innovation.
Approaches to Flexibility
For the Alibaba team, technical competitiveness depends on turning ideas about resource consumption into real practices. To this end, four key ideas have figured in its efforts to improve resource flexibility during the 11.11 Global Shopping Festival.
Flexibility of public cloud standard resources
One option for Alibaba is to directly employ standard resources from Alibaba Cloud to support the promotion and afterward return them. While this is the most straightforward approach, it presents a challenging gap in performance and cost between business needs and cloud resources. Because cloud computing is highly standardized, this approach prevents using customized machines.
Co-location capability
A second approach involves class-sharing co-location and time-sharing co-location of existing services. Offline resources are used to support the promotion, which describes class-sharing co-location; offline downgrading is done at the start of the promotion at midnight of 11.11, and afterward the peak resources are returned online, which describes time-sharing co-location.
Rapid upload and download
Rapid upload and download describes an approach that involves shortening the holding period for resources as much as possible when using cloud and offline resources.
Fragment resources
Whereas in traditional thinking databases are analogous to a single large block, a final approach considers that the database’s single large library can be converted into smaller libraries and then applied to use fragmented resources from other services, including resources on the public cloud.
Implications for Architecture
In general terms, the cost of Alibaba’s 11.11 sale is equal to the cost of holding resources multiplied by the time of the holding cycle. The key to shortening the holding period is using relatively versatile resources like the cloud and faster deployment by way of containerization; the key to reducing the use of resources like offline or expansion-only resources is to implement an architecture that separates storage and computing.
In pursuit of the goal of ultimate flexibility, Alibaba’s database has so far gone through three phases, moving first from hybrid cloud flexibility to containerized flexibility and then to storage- and computing-separated flexibility. Correspondingly, its underlying architecture has progressed through upgrades from a high-performance ECS hybrid cloud model to a containerized hybrid cloud model, and finally to a storage- and computing-separated public cloud and offline co-location model.
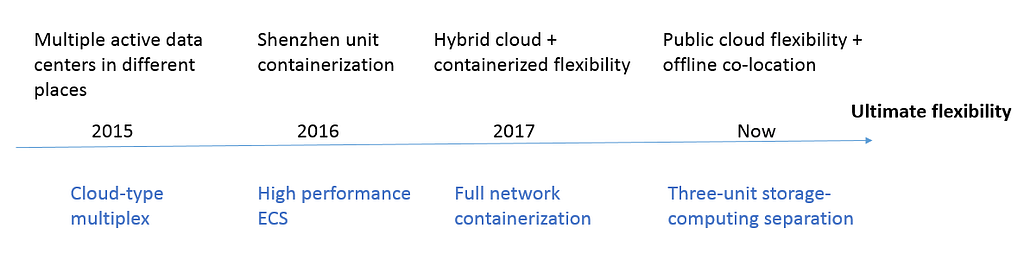 Evolution of the underlying database architecture
Evolution of the underlying database architecture
Alibaba’s tendency in enhancing the database’s underlying architecture has been to test a new architecture on one unit each year and then to implement it throughout the network the following year. One analogy for this would be digging a pit for the team to jump into before then working together to climb out and fill it back in. Despite the inherent pressure in this approach, each evolution of the architecture has successfully made co-location faster and more flexible.
Establishing Hybrid Cloud Flexibility
Prior to 2015, Alibaba approached the 11.11 sale with a method called manual flexibility. This essentially involved borrowing machines temporarily for the promotion, as for example with cloud-type machines that would be used and later returned to the cloud. At the end of 2015, Alibaba’s Li Jin asked a gathering called “Challenge the Impossible” whether the database could be run on ECS (Elastic Compute Service). In the spirit of that theme, Tianyu and colleague Zhang Rui decided then and there to attempt the approach.
Believing that the maximum consumption when running the database on virtual machines would lie in the virtualization of the IO and network, Tianyu and Zhang needed a way to approximate the performance of the machine itself and to penetrate virtualization. By this time network user-mode technology DPDK was relatively mature, but the question of how it could be used to achieve high efficiency and whether it could be offloaded to the hardware to do computations presented another problem. The user-mode link of the file system IO featured an SPDK solution by Intel that was still being validated by major manufacturers and had not yet been put into scale application. Starting with these circumstances, the project was called high-performance ECS, and in collaboration with Alibaba’s ECS team Tianyu and Zhang were able to achieve a worst-case scenario of less than 10 percent performance loss compared with local disks.
In 2016, the high-performance ECS project passed daily validation in the Alibaba Group, and flexible cloud resources were deployed for the 11.11 sale from 2017 onward. As well as creating high-performance ECS products, the project more importantly built up the pure user-mode link technology of the network and file IO. This marked a technical turning point and laid a foundation for the high-performance breakthrough of Alibaba’s subsequent storage- and computing-separated products.
Improving Resource Efficiency: Containerization
With the improved capabilities of standalone servers, Alibaba’s database began using a single-machine multi-instance solution as early as 2011. This utilized standalone resources by supporting multiple instances on a single machine through deployment isolation between Cgroup and file system directories and ports. However, it also presented the problems of occasional OOM of memory, IO competition, multi-tenant co-location security issues, and consistency of master and backup machines in the database.
With the increasing density of standalone deployments, the Docker community had also begun to develop by this time. Despite its immaturity, Docker relied on Cgroups for resource isolation and hence could not solve Cgroup IO competition or OOM problems, but did try to make new definitions for resource specifications and deployments through the combination of resource isolation and namespace isolation.
In light of these developments, Alibaba recognized several advantages in containerization. First, containerization offered standardized specifications, database and machine model decoupling, and no requirement on symmetry of active and standby machines, which together brought greater efficiency to large-scale operation and maintenance. Second, containerization’s namespace isolation brought co-location capabilities, allowing for a unified resource pool. It further offered support for co-location of different database types and versions, and enabled DB to have the same co-location conditions as other types of applications.
In 2015 Alibaba’s database began to validate containerization technology, and by 2016 it was widely used in daily scenarios. The Group set a goal of fully containerizing a trading unit of its e-commerce provider to support the 2016 11.11 sale, for which it would carry about 30 percent of the total trading volume. After successfully achieving this, Alibaba turned its goal for the database in 2017 to containerizing the entire network. Presently, the containerization ratio of the entire network is nearly 100 percent.
More important than its improvement to the efficiency of deployment flexibility, containerization offered transparency on differences among underlying resources. Before the start of smart dispatch, which improved utilization through automatic migration, the machine multiplex and multi-version co-location that containerization introduced had improved utilization by 10 points, and the unification of resource pools and standard deployment templates had together increased the efficiency of resource delivery.
Containerization completes the abstraction of various underlying resources and standardizes specifications, while mirrored deployment brings convenience in deployment. Based on the cooperation of database PaaS and the unified dispatch layer, the database tends to become increasingly flexible; as long as a place has resources, it is suitable for running a database in.
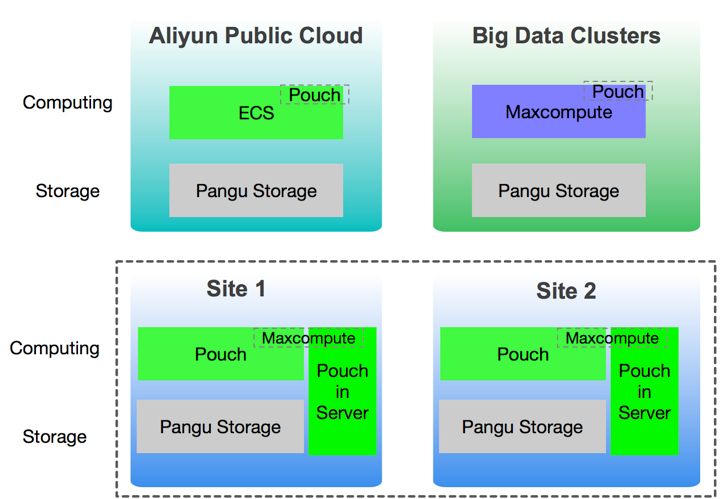
Toward Storage- and Computation-Separated Architecture
Despite its advantages, high-performance ECS and containerized deployment still presented certain shortcomings that limited their reliability in the 11.11 sale. First, database flexibility requires data migration, and moving data to ECS is a time-consuming task; second, the scale of flexibility was exceedingly large, and when it outpaced the public cloud sales cycle would lead to increased holding costs.
Faced with a need for faster, more versatile flexibility, Alibaba needed to consider potential adaptations for the model it had established. With the development of dispatch in 2016, many considered making machines diskless and separating storage and computation so as to increase dispatch efficiency. However, separation of storage and computation in the database generated considerable controversy.
For many on Tianyu’s team, the Share Nothing distributed extension of the database was a crucial issue. Many wondered if storage-computing separation would bring the database back into the IOE era, or whether it would make sense that the DB itself would have this storage-computing separation, given that if the IDC is a data center then the application is a computation and the DB is storage. Whereas data comes in dual primary and backup copies, the separation of storage and computing would raise the number of copies to three. This raised the question of whether pooling storage cluster capacity would balance the cost of the extra copy.
Facing these dilemmas, Tianyu turned to measuring the input and output of the storage- and computing-separated architecture in 11.11 scenarios. In such conditions, business requirements raise the demand for computing capacity by as much as 10 times to support peak pressure. However, since the disk stores long-term data, the peak data volume does not greatly exceed the total. There is thus no need to extend the disk’s capacity.
In the past, active and backup architecture were run on the local disk where computing was not possible, while storage was extended separately. The higher the 11.11 sale’s indicators, the more machines were added, which raised costs due to the disk generating the main cost of standard database machines. In separating computing and storage, measurements show that the cost is higher than the cost of a local disk under daily pressure circumstances, but when pressure increases, the storage- and computing-separated mode increases computation but not cost. The reason for this is that when the storage cluster is pooled both the capacity and the performance are pooled, in which case any high-load instance of the IO is dispersed for the entire cluster to share. Furthermore, disk throughput IOPS are reused, meaning there is no need to extend performance. In light of the above, there is a significant cost advantage in this approach.
Traditional thinking tends to focus on the advantages of pooling storage cluster capacity, but for the 11.11 sale Alibaba uses more performance pooling to break standalone bottlenecks. Thus, the Group has pursued multiple active data centers in different locations for the sake of separating e-commerce and storage-computing for all units, while the rest of all services continue to use the local disk for the target architecture of disaster recovery within specific cities.
In advancing this concept, Tianyu’s team needed a way to judge the feasibility of the proposed architecture. Numbers indicated that the read and write response time of SSD disks is around 100–200 milliseconds, while 16k network transmission occurs within 10 microseconds. Thus, although storage-computing separation increases network interaction by two to three times, coupled with the consumption of storage software itself there is an opportunity to achieve read and write latency within 500 microseconds. In a database instance pressure test, the team found that the storage cluster has a larger QPS water level online with the increase of concurrency, which proved that the performance pooling breaks the standalone bottleneck and leads to improved throughput.
In 2017, the database team started verification of the separation of storage and computing. The 25G-based TCP network realized the storage- and computing-separated deployment, and carried 10 percent of the traffic for that year. Despite achieving a response time of 700 microseconds based on distribution storage, the team encountered high consumption rates from the kernel state and software stack. For this reason, their efforts targeted slow IO optimization on X-DB, with particular focus on the optimization of the log writing to the disk, and enabling atomic write operations to write off the double write buffer and improve throughput.
In this process, the team built up the storage dispatch system that has since been used as a component subject to unified dispatch to serve Alibaba Group businesses. Not satisfied with the existing architecture’s performance, they then built up technologies like slow IO optimization on X-DB, cross-network IO paths that are storage- and computing-separated, and storage resource dispatch. With these technologies and coupled with the development of Alibaba RDMA network architecture, the database team joined forces with Alibaba’s Pangu team to work on the end-to-end full-user storage-computing separation solution in the second half of 2017.
Implementing the Full User-mode IO Link Storage- and Computing-separated Architecture
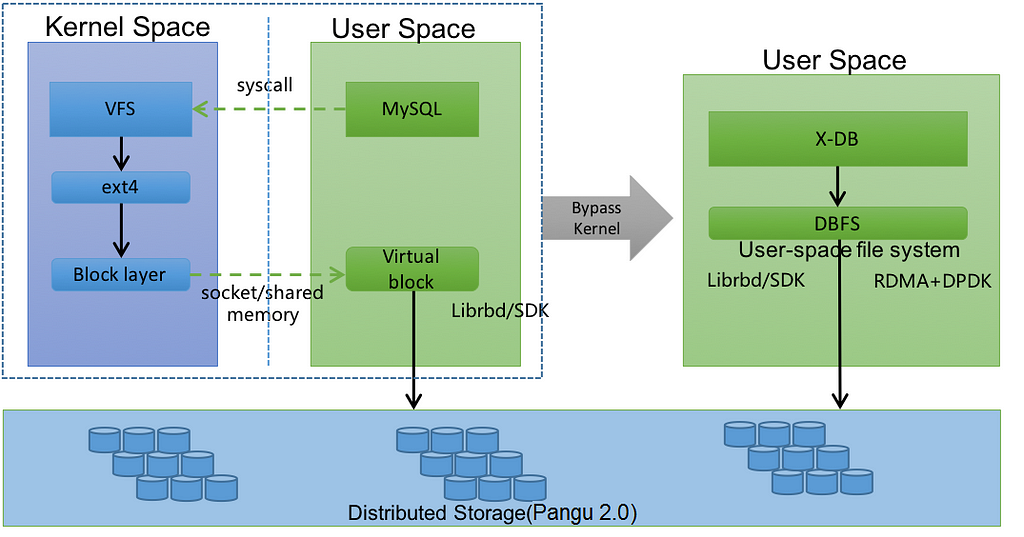
Starting from the database software X-DB’s IO call, the database team made use of the self-developed user-mode file system DBFS to implement the new architecture. Pangu is a high-reliability, high-availability, and high-performance distributed file system developed by Alibaba Cloud; DBFS uses Pangu’s user-mode clients to access the back-end Pangu distributed file system directly through the RDMA network. The entire IO link completely bypasses the kernel stack, and since DBFS bypasses the kernel file system it naturally bypasses the page cache. For this reason, DBFS implements a more concise and efficient BufferIO mechanism for database scenarios.
Because IO is remotely accessed across the network, RDMA plays an important role. In the charts below, the latency comparison between RDMA and TCP networks is shown for different packet sizes.
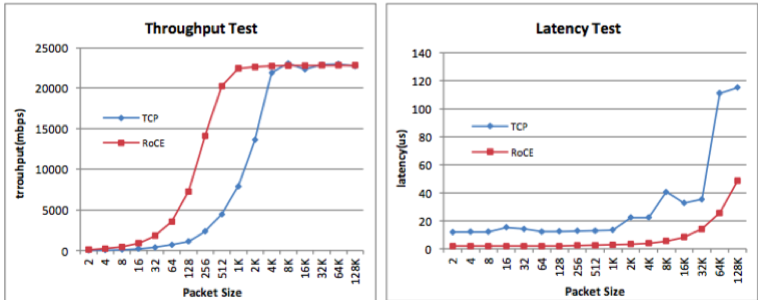
In addition to the advantage in latency, RDMA can effectively control the tail latency of the long tail IO, which can provide a more efficient guarantee of response time to user requests for a database request involving multiple IOs. Application of RDMA technology is a prerequisite for large-scale DB storage-computing separation. Data measurements indicate that the latency of the DBFS+RDMA link has reached the same level as the Ext4+ local disk.
This year, Alibaba deployed RDMA on a large scale for the first time, which Tianyu describes as bringing a feeling of treading on eggshells. Following many tests and drills, the RDMA’s supporting monitoring and operation and maintenance system was approved for construction, enabling Tianyu’s team to identify network port failures of server network cards or switches in less than a minute and trigger the alarm to quickly isolate the fault, support the rapid cutting of server traffic, and support the downgrade switching from RDMA to TCP for clusters or standalone networks. In cut-through drills, DBFS indicated that the write latency of the RDMA link fell by a factor of two compared with TCP. In a full-link pressure test, the RDMA-based technology guaranteed that the disk response time would be stable at about 500 microseconds in single-database instances with throughput of approximately 2 GB, without glitches.
To simultaneously support RDMA, EC compression, snapshot, and other functions, Pangu has undergone extensive optimization for distributed storage, particularly regarding optimization for write IO, as well as the RDMA/TCP cut, fault isolation, and other stability-related work. As the chassis of Alibaba’s storage system, its online services occur at a very large scale.
Challenges in Scale Applications
Alongside the above developments, Alibaba has encountered a number of problems in scale applications.
First, Bridge and RDMA are naturally incompatible for network virtualization of containers. This is because the container uses the Bridge network mode to allocate IP, and the RDMA application uses kernel mode. Thus, to apply RDMA, the Host network mode must be used for containerization, and the full user-mode link such as Host + X-DB + DBFS + RDMA + Pangu storage must be taken.
Second, for the public cloud environment, Alibaba forms a hybrid cloud environment using VPC, such that the application accesses the database through VPC and the database uses physical IPs for RDMA to access Pangu and X-DB’s internal X-Paxos. This is a complex and effective solution thanks to the rapid iteration of DBPaaS management and the flexibility of containerized resource dispatch, as well as their rapid implementation and steady advancement in the face of changes.
Present Outlook
At the start of 2018, Tianyu’s team set a support pattern for the year’s 11.11 Global Shopping Festival, such that for active data centers in different locations computation is extended to big data offline resources. For unit data centers, computation is extended to public cloud resources, while elastic extension is carried out without moving data and upload and download are managed quickly. This year the DB has been committed for the sole purposes of completing resource adjustment, realizing storage- and computing-separated upgrades to the architecture for e-commerce sites, and achieving flexibility for the sale event through flexible deployment of the X-DB remote multi-copy architecture.
Based on its underlying Pangu distributed storage, this approach to flexibility does not require data migration, and only the disk needs to be mounted. The database can be as fast and flexible as applications, such that a cluster can complete elastic extension in 10 minutes. Meanwhile, in full-link pressure tests, flexibility could be carried out to a larger specification while quickly giving pressure for services with performance bottlenecks. With the availability of rapid flexibility, capacity extension for all DB sites planned for the 2018 11.11 sale was completed within three days, a previously impossible feat enabled by the storage- and computing-separated architecture.
Currently, Tianyu’s team and Alibaba are working to routinize the flexibility already achieved. Through data prediction, elastic extensions can be triggered automatically, moving the Group a step closer to make failures caused by standalone machine capacity problems a thing of the past. Looking forward, Alibaba will develop its platform in the direction of intelligence, having established a strong, fast, and flexible underlying architecture with which to engage these possibilities for its database.
(Original article by Chen Changcheng陈长城)
Alibaba Tech
First hand and in-depth information about Alibaba’s latest technology → Facebook: “Alibaba Tech”. Twitter: “AlibabaTech”.
Stretching the Mold: How Alibaba Enhances Database Flexibility was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.