Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
“Data is the new oil. It’s valuable, but if unrefined it cannot really be used. It has to be changed into gas, plastic, chemicals, etc to create a valuable entity that drives profitable activity; so must data be broken down, analyzed for it to have value.”
— Clive Humby
Deep Learning is a revolutionary field, but for it to work as intended, it requires data. The area related to these big datasets is known as Big Data, which stands for the abundance of digital data. Data is as important for Deep Learning algorithms as the architecture of the network itself, i.e., the software. Acquiring and cleaning the data is one of the most valuable aspects of the work. Without data, the neural networks cannot learn.
Most of the time, researchers can use the data given to them directly, but there are many instances where the data is not clean. That means that it cannot be used directly to train the neural network because it contains data that is not representative of what the algorithm wants to classify. Perhaps, it contains bad data, like when you want to create a neural network to figure out cats among colored images, and the dataset contains black and white images. Another problem is when the data is not appropriate. For example, when you want to classify images of people as male or female. There might be pictures without the tag or pictures that have the information corrupted with misspelled words like ‘ale’ instead of ‘male.’ Even though these might seem like crazy scenarios, they happen all the time. Handling these problems and cleaning up the data is known as data wrangling.
Also, researchers sometimes have to fix problems of how data is represented. In some places, the data might be expressed in one way, and in other areas, the same data can be described in a completely different way. For example, you can classify a disease like diabetes with a certain number (3) in one database and (5) in another. This is one reason for the considerable effort in industries to create standards to share data more easily. For example, Fast Healthcare Interoperability Resources (FHIR) was created by the international health organization, Health Level Seven International, to create standards for exchanging electronic health records.
Standardizing data is essential, but selecting the correct input is also important because the algorithm is created based on the data. And, choosing that data is not easy. One of the problems that can occur when selecting data is that it can be biased in some way, creating a problem known as selection bias. That means that the data used to train the algorithm does not necessarily represent the entire space of possibilities. The saying in the industry is, “Garbage in, garbage out.” That means that if the data entered into the system is not correct, then the model will not be accurate. This is best illustrated by the parable in “Artificial Intelligence as a Negative and Positive Factor in Global Risk,” Eliezer Yudkowsky:
“Once upon a time, the US Army wanted to use neural networks to automatically detect camouflaged enemy tanks. The researchers trained a neural net on 50 photos of camouflaged tanks in trees and 50 photos of trees without tanks. Using standard techniques for supervised learning, the researchers trained the neural network to a weighting that correctly loaded the training set — output ‘yes’ for the 50 photos of camouflaged tanks, and output ‘no’ for the 50 photos of forest. This did not ensure, or even imply, that new examples would be classified correctly. The neural network might have ‘learned’ 100 special cases that would not generalize to any new problem. Wisely, the researchers had originally taken 200 photos, 100 photos of tanks and 100 photos of trees. They had used only 50 of each for the training set. The researchers ran the neural network on the remaining 100 photos, and without further training, the neural network classified all remaining photos correctly. Success confirmed! The researchers handed the finished work to the Pentagon, which soon handed it back, complaining that in their own tests the neural network did no better than chance at discriminating photos.
It turned out that in the researchers’ dataset, photos of camouflaged tanks had been taken on cloudy days, while photos of plain forest had been taken on sunny days. The neural network had learned to distinguish cloudy days from sunny days, instead of distinguishing camouflaged tanks from empty forest.”
ImageNet
Fei-Fei Li, who was the director of the Stanford Artificial Intelligence Laboratory and also the Chief Scientist of AI/ML at Google Cloud, realized that data was such an important piece of the development of Machine Learning algorithms early on, whereas most of her colleagues did not believe the same.

Li realized that to make better algorithms and more performant neural networks, more and better data was needed and that better algorithms would not come without that data. At the time, the best algorithms could perform well with the data that they were trained and tested with, which was very limited and did not represent the real world. She realized that for the algorithms to perform well, data needed to resemble actuality. “We decided we wanted to do something that was completely historically unprecedented,” Li said, referring to a small team who would initially work with her. “We’re going to map out the entire world of objects.”
To solve the problem, Li constructed one of the most extensive datasets for Deep Learning to date, ImageNet. The dataset was created, and the paper describing the work was published in 2009 at one of the most important Computer Vision conferences, Computer Vision and Pattern Recognition (CVPR), in Miami, Florida. The dataset was very useful for researchers and because of that, it became more and more famous, providing the benchmark for one of the most important annual competitions for Deep Learning, which tested and trained algorithms to identify objects with the lowest error rate. ImageNet became the most significant dataset in the field of Computer Vision in A.I. for a decade and also helped boost the accuracy of algorithms that classified objects in the real world. In only seven years, the winning accuracy in classifying objects in images increased from 72% to nearly 98%, overcoming the average human’s ability.
But ImageNet was not the overnight success many imagine. It required a lot of sweat from Li, which started when she taught at the University of Illinois Urbana-Champaign. She was dealing with a lot of problems that many other researchers shared. Most of the algorithms were overtraining to the data given to them, making them unable to generalize beyond it. The problem was that most of the data presented to these algorithms did not contain many examples, and therefore, the models created based on them could not generalize well. The available datasets did not have enough information about all the use cases for them to work in the real world. She, however, figured out that if she generated a dataset that was as complex as reality, then the models should perform better.
It is easier to identify a dog if you see a thousand pictures of different dogs, at different camera angles, and lighting conditions than if you only see five dog pictures. In fact, it is a well-known rule of thumb that algorithms can extract the right features from images if there are around 1,000 images for a certain type of object.
Li started looking for other attempts to create a representation of the real world, and she came across a project, WordNet, created by Professor George Miller. WordNet was a dataset that had a hierarchical structure of the English language. It resembled a dictionary, but instead of having an explanation for each word, it had a relation to other words. For example, the word ‘monkey’ is underneath the word ‘primate,’ that is underneath the word ‘mammal.’ In that way, the dataset contained the relation of all the words among others.
After studying and learning about WordNet, Li met with Professor Christiane Fellbaum, who worked with Miller on WordNet. She gave Li the idea to add an image and associate it to each word, creating a new hierarchical dataset based on images instead of words. Li expanded on the idea — instead of adding one image per word, she added many images per word.
As an Assistant Professor at Princeton, she built a team to tackle the ImageNet project. Li’s first idea was to hire students to find images and add them to ImageNet manually. But she quickly realized that it would become too expensive and take too much time for them to finish the project. From her estimates, it would take a century to complete the work, and so, she changed strategies. Instead, she decided to get the images from the internet. She could write algorithms to find the pictures, and humans would choose the correct ones. After months working on this idea, she found that the problem with this strategy was that the images chosen were constrained to the algorithms that picked the images. Unexpectedly, the solution came when Li was talking to one of her graduate students, who mentioned a service that humans anywhere in the world completed small online tasks very cheaply. With Amazon Mechanical Turk, she found a way to scale and have thousands of people find the right images for not too much money.
Amazon Mechanical Turk was the solution, but a problem still existed. Not all the workers spoke English as their first language, so there were issues with specific images and the words associated with them. Some words were harder for these remote workers to identify. Not only that, but there were words like ‘babuin’ that workers did not exactly know which images represented the type of image. So, her team created a simple algorithm to figure out how many people had to look at each image for a given word. Words that were more complex like ‘babuin’ required more people to check, and simpler words like ‘cat’ needed only a few people to check these images.
With Mechanical Turk, creating ImageNet took less than three years, much less than the initial estimate with only undergraduates. The resulting dataset had around 3 million images separated into about 5,000 “words.” People were not impressed with her paper or dataset, however, because they did not believe that more and more refined data led to better algorithms. But most of these researchers’ opinions were about to change.
The ImageNet Challenge
Li had to show that her dataset led to better algorithms to prove her point. To achieve that, she had the idea of creating a challenge based on the dataset to show that the algorithms using it would perform better overall. That is, she had to make others train their algorithms with her dataset to show that they could indeed perform better than models that did not use her dataset.
The same year she published the paper in CVPR, she reached out to a researcher named Alex Berg. She suggested that they work together to publish papers to show that algorithms using the dataset could figure out if images contained particular objects or animals and where they were located. In 2010 and 2011, they worked together and published five papers using ImageNet. The first paper became the benchmark of how algorithms would perform on these images. To make it the benchmark for other algorithms, Li reached out to one of the most well-known image recognition dataset and benchmark standards, PASCAL VOC. They agreed to work together and added ImageNet as a benchmark for their competition. The competition used a dataset called PASCAL that only had 20 classes of images. ImageNet in comparison had around 5,000 classes.
As Li predicted, the algorithms were performing better and better as the competition continued, like when they trained using the ImageNet dataset. Researchers learned that algorithms started performing better for other datasets when the models were first trained using ImageNet and then fine-tuned for another task. A detailed discussion on how this worked for skin cancer is in Chapter 25.
In 2012, a major breakthrough occurred. The father of Deep Learning, Geoffrey Hinton, together with Ilya Sutskever and Alex Krizhevsky submitted a deep Convolutional Neural Network architecture called AlexNet — still used in research to this day — “which beat the field by a whopping 10.8% point margin.” That marked the beginning of the boom of Deep Learning, which would not have happened without ImageNet.
ImageNet became the go-to dataset for the revolution of Deep Learning, more specifically of Convolution Neural Networks (CNNs) led by Hinton. ImageNet not only led the revolution of Deep Learning but also set a precedent for other datasets. Since its creation, tens of new datasets were introduced with more abundant data and more precise classification. Now, they allow researchers to create a better model. Not only that, but research labs have focused on releasing and maintaining new datasets for other fields like the translation of texts and medical data.
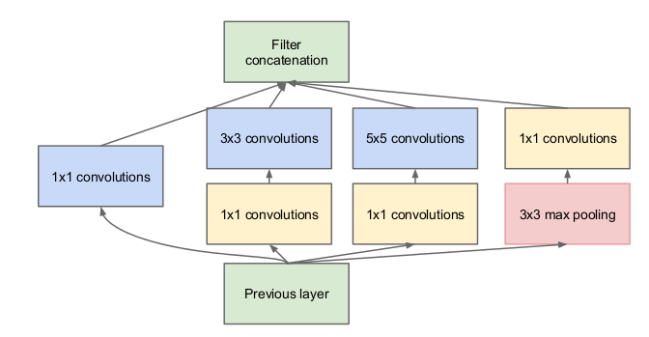
In 2015, Google released a new Convolutional Neural Network called Inception or GoogleNet. It contained fewer layers than the top performing neural networks, but it performed better. Instead of adding one filter per layer, Google added an Inception Module, which includes a few filters that run in parallel. It showed once again that the architecture of neural networks is important.
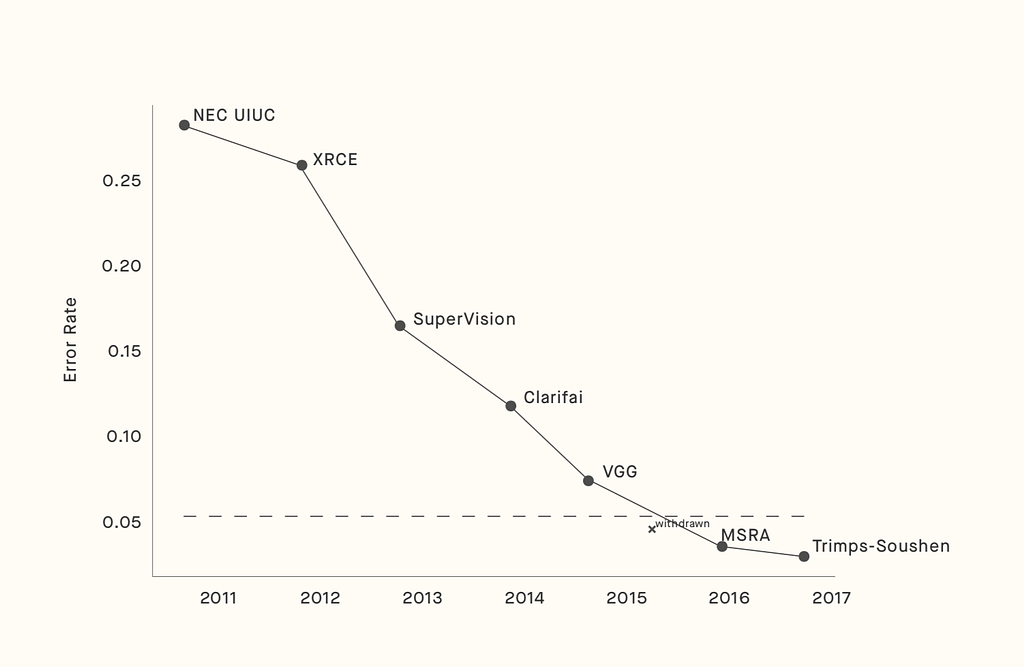
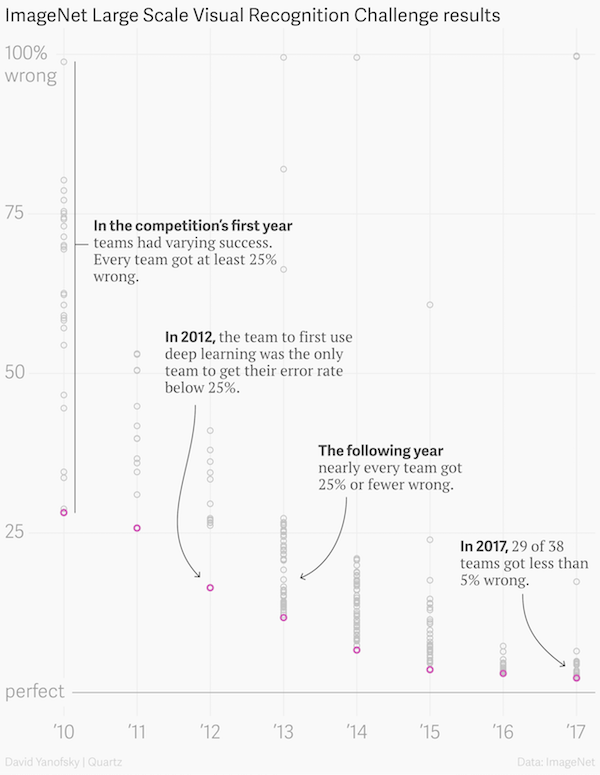 Image error rate over time
Image error rate over time
ImageNet is considered solved, reaching the error rate lower than the average human, achieving superhuman performance for figuring out if an image contains an object and what kind of object it is. After nearly a decade, the competition with ImageNet ended with models being trained and tested on it. Li tried to remove the dataset from the internet, but big companies like Facebook pushed back since they used it as their benchmark.
But since the ending of the ImageNet competition, many other datasets were created based on millions of images, voice clips, and text snippets entered and shared on their platforms every day. People sometimes take for granted that these datasets, which are intensive to collect, assemble, and vet, are free. Being open and free-to-use was an original tenet of ImageNet that will outlive the challenge and likely even the dataset. “One thing ImageNet changed in the field of AI is suddenly people realized the thankless work of making a dataset was at the core of AI research,” Li said. “People really recognize the importance the dataset is front and center in the research as much as algorithms.”
Data is the New Oil was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.