Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
 Space Invaders
Space Invaders
Everyone is talking about the race between Artificial Intelligence and Human Intelligence. When will AI fully surpass human ability and be in control of a majority of our daily lives? While humans spend their days going to school and educating themselves, what is AI doing to get an edge on the competition? AI needs to step up it’s game!
Jokes apart, there is a technique in Artificial Intelligence called Reinforcement Learning (RL) which allows an AI to train/teach itself how to perform a certain task. In my case, I used RL to train an AI to play the Atari version of Space Invaders!
In this article I will go through the concepts involved in creating an RL agent such as the one I made. I will also include my code if you want to see a Python implementation!
Before we get started…
I will use the following terms throughout the article. If you aren’t familiar with them already, well…here you go!
agent — The AI player. In this case it will be the shooter at the bottom attacking the aliens
environment — The complete surroundings of the agent (i.e. the barriers in front of it and the aliens above)
action — Something the agent has the option of doing (i.e. move left, move right, shoot, do nothing)
step — Choosing and performing 1 action
state — The current situation the AI is in
So how does Reinforcement Learning work?
I briefly mentioned that Reinforcement Learning can be used to help an AI train itself, but how does it actually work? In RL, the AI trains on a reward based system.
Think back to elementary school. Every time you did something right, your teacher might give you a cookie or a sticker. This would encourage you to do more similar actions because you want as many cookies and stickers as you can get. Every time you did something wrong you might get a timeout or lose recess, which would discourage you from doing that again. The agent learns in a very similar way. We set conditions that if the AI follows correctly, they will receive an imaginary reward. If they do the wrong things they lose these rewards.

When we apply this to Space Invaders, the agent extracts observations from the environment which will help it decide the right action to take. For example, if it sees a bullet coming towards it, it will move out of the way!
How can our AI understand the environment?
Taking a step back, how does our AI “observe” the environment in the first place? How is it able to recognize that a bullet is coming towards it or even what a bullet is? It is able to do all of these things with the use of a Convolution Neural Network (CNN).
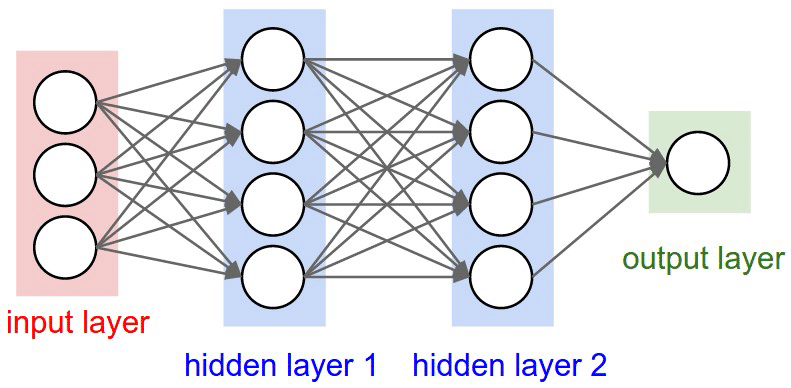 Neural Network Diagram
Neural Network Diagram
Neural Networks (NN) in general are modeled after the human brain. Like the brain has neurons which transmit information between themselves, a NN has “nodes” (the white circles) which process information and perform operations. In a standard NN, there are three basic types of layers: an input layer, hidden layers, and an output layer. The input layer takes the input, which is processed by the hidden layers, and finally spit out the output in the output layer.
A CNN is a special type of Neural Network designed to analyze visual imagery. It contains convolutional layers which take images as inputs and sweeps over them pixel by pixel. Each convolutional layer is designed like a filter, searching for something specific in the image. You can have layers searching for something as general as a square to something more complicated like a bird!
Okay, so our AI can tell what is what in our environment. AGENT LOOK OUT A BULLET!
 Static state
Static state
Which way is it going? How fast is it going? Will we be able to go across without getting hit?
All of these things can’t be determined with a static image, so just like we don’t have answers to these questions, neither does the AI.
The last thing we need to do so that our AI can properly understand the environment is stack images to add directional sense. If we take 1 image, wait a couple frames, take another image, and so on, we are able to create something similar to a GIF for our AI to perceive.
 4 states stacked on top of each other
4 states stacked on top of each other
It’s a lot easier to see that the bullets are coming towards us and at what speed!
Learning to play the game with Q-Learning
At this point we are giving the AI a reward for shooting the Aliens, the AI knows how to understand the environment, but there is still one fundamental component we are missing. How does the AI know what to do in what situation?
If you or I were to play the game, we would have a general idea of what to do. Shoot the aliens and dodge the bullets, simple! But how did we know to do this? From past experiences, we know that getting shot isn’t good and to win a game you probably have to kill all the enemies. The problem is, the AI has no past experience. Think of it like an infant who has the ability to play video games.
So what better way to learn how to play a game then by playing the game!
But before we do that, it would be a good idea to have a way of remembering what worked well and what didn’t. So the AI will first create something called a Q-Table.
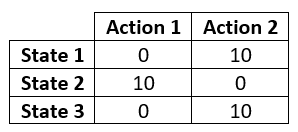 Example Q-Table
Example Q-Table
A Q-Table contains a column for every possible action in your game, and a row for every possible state in your game. In the cell where they meet, we put the Maximum Future Expected Reward we expect by doing that action in the given state. Intuitively, the AI will always perform the action which will render the highest reward.
Obviously, we can’t expect to know all of the future rewards right away because then we wouldn’t need an AI to play the game in the first place. We predict these numbers through the Bellman Equation
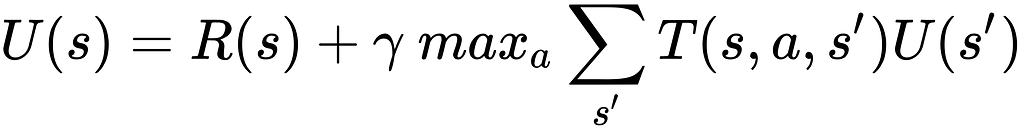 The Bellman Equation
The Bellman Equation
If you are like me, you probably got a headache just by looking at it. The main thing to note is the Greek letter Epsilon. As we pass the controller to the infant AI to start learning the game, the value of Epsilon is very high. While Epsilon is high, the AI will choose its actions randomly, since there is no knowledge to base its actions upon. As the AI unintentionally stumbles upon rewards or penalties, it starts to associate performing certain actions in certain states as either good or bad. Thus it fills in the Q-Table accordingly. As training goes on, the value of Epsilon slowly decays. With a lower value for Epsilon, there is a higher likelihood that the AI will make decisions based on its Q-Table instead of randomly generating it (called Epsilon-Greedy method).
By the time Epsilon becomes practically 0, the AI should have a well filled out Q-Table to help it make decisions.
Let’s look at my AI play Space Invaders
With these concepts in mind, I developed my own AI to play Space Invaders. A link to my code is right here.
Overall the AI plays pretty well considering the amount of training it did. It takes an EXTREMELY long time to train an AI and a lot of computational power. When you think your AI has learned it all, it stumbles across a new problem! It recently discovered that it can lose if the Aliens reach the bottom. As seen in the video, it completely ignored the Aliens which were getting closer and closer. With some more training, it should realize that it can increase its total rewards by shooting the Aliens before they reach the bottom.
Key Takeaways
Reinforcement Learning is a system where the AI is rewarded for doing the right thing thus it learns what to do and what not to do
Convolutional Neural Networks are a special type of Neural Network which can recognize images using Convolutional Layers
Q-Learning is when the AI plays the game and records what actions in what states give what rewards in a Q-Table. After a lot of training, they used the develop Q-Table to play to the best of their abilities
How I Trained an AI to Play Atari Space Invaders was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.