Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.

I used to work with several projects leveraging idea of microservices. What always was a problem (besides deployment, but having enough DevOps resources it is pretty much solvable) is separation of concerns.
If you look at books, blog posts and tweets about microservices architecture (there are already millions of them), you’ll see that everyone declares nearly the same idea — microservices must be independent. That completely makes sense. But in words.
In reality if you want to build exactlty microservices but not just monolith with couple of side services, you’ll have to think about splitting your business domain. And here you unlikely find any good advices. First of all, in many cases it’s just not completely solvable, second, after a meeting with the project manager your business domain will change, breaking all the existing architecture. And you probably know managers attitude to refactoring.
So what people usually do, they end up with compromise. Ok, our services are going to be a bit coupled, but we have our cross services API, why just not to utilize it.
API
So let’s consider the classical example, we have 2 services: users and orders. We decided to follow information hiding pattern, where each of the services incapsulates its own database (or its part of one database).
Apparently our orders service needs some information from users one. For example we have API endpoint report, which gives extended info about all orders by users for some certain day. In the report we need user first name, last name and contacts. Such endpoint is a good example of broken separation of concerns. We need data from both microservices. But there is no way back, services are divided, there is a task, which needs to be done. Which options do we have?
Synchronous API
It’s usually HTTP. REST in most of the cases, but can be any API framework based on HTTP, like GraphQL, OData or even gRPC. So the flow is pretty straightforward, the order service gets its data from database, where it has access to. Then it sends request to users service to get missing information about users.
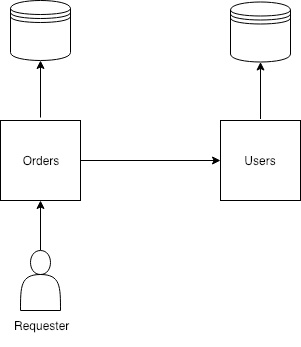
So our requester is not going to get response back until Orders services gets data back from Users service. If Users fails, Orders fails as well.
That’s the problem of synchronous API, it’s a direct dependency.
Asynchronous API
So we could change our API to asynchronous transport, for example streams.
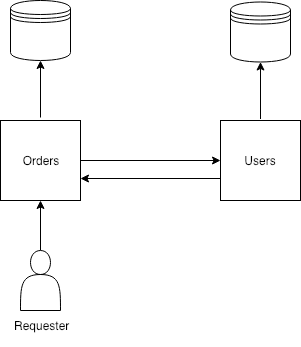
But the only difference now is that instead of immediate fail, we’re not going to receive any response from Users service in case its failure. So likely Requester will end up with timeout.
Why do we split databases
The reason why we separate access to data is old good encapsulation. We decrease risk of unexpected modification of data by some strange service. That’s why make class variables private in OOP and use containers to run our services. The problem is that data doesn’t belong to our microservice. It belongs to the database, which is completely different service. Encapsulating DB data with Users microservice we make it basically as proxy for the database. Of course, there can be cases, where a service applies sufficient transformation to the data, but it that case it’s new data already and it belongs to that microservice. Such data definitely can be requested via service API.
But when our service is just a CRUD interface for a database, we make huge amount of extra work, complexity and network load (therefore we see attempts to solve it using technics like service mesh for example) just because we want to follow rules.
What’s the solution?
So let’s for a moment get rid of prejudices and make a shared database.
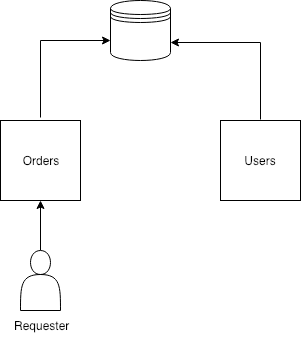
Together with prejudices we got rid of extra API, network load (data can be joined and retrieved from DB by one query) and sufficiently improved performance of the application.
But there are of course new problems:
- Orders service has to be aware of Users service tables
- Users can change the schema of it’s tables
- Orders service can write to Users and modifiy it’s data
- We have to use one database for both microservices
It looks we again have the broken separation of concerns. But let’s consider all the points.
- Yes, Orders must be aware of all the tables basically and DB schema in general. But in case of information hiding design, the service instead must be aware of API methods, which is still the same kind of extra knowledge.
- Changing a schema is a real problem. But basically there is not many differences between changing DB schema and service API. In both cases you can make it backward compatible and in both cases you can break everything. So it’s a pure matter of discipline. Of course more your services teams separated, then you probably should move more to the direction of API.
- Yes, by default our Orders service could modify all the tables in the DB. But you can leverage DB ACL for that, if your database allows you to do it. Most of the mainstream databases support ACL on the table level. So you can avoid risk of unexpected modification as you would do it with private variables and methods.
- Yes, you have to use one database. But we consider only the case of splitting business domain. If your service needs a special type of DB, it’s definitely a case of using API communicating with it.
Furthermore, there formed a consensus among developers (if consensus even possible there) that in the very beginning you probably don’t need microservices. Start with monolith and see, if you really need them in future.
So when you do, it’s much easier to stay with shared database, just create separated users per microservice to restrict data access.
I hope, that was useful and I really appreciate any feedback regarding your experience.
Is Shared Database in Microservices actually anti-pattern? was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.