Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.

Failures are inevitable. Just as we need to test our application to find bugs in our business logic before they affect our users. We need to test our application against infrastructure failures. And we need to do it before they happen in production. and cause irreparable damages.
The discipline of Chaos Engineering shows us how to use controlled experiments to uncover these weaknesses.

In this post, we will see how we can leverage Thundra’s span listeners to inject failures into our serverless application. We will use these failures to expose weaknesses such as:
- Missing error handler for DynamoDB operations.
- Missing fallback when the primary data source is unavailable.
- Missing timeout on outbound HTTP requests.
But first, here’s a quick primer on Thundra.
Hello, Thundra!
Consider an API with two endpoints:
- POST /user/{userId}: create a new user and optionally records the user’s preference
- GET /user/{userId}/pref: fetches a user’s preference
Here is a simple handler module that implements both endpoints, and here is my serverless.yml. To learn more about the Serverless framework, go to here.
As soon as I log into Thundra, I can see a high level summaries of my functions:
- Region, language runtime, function name, when it was last invoked.
- Number of invocations, errors and cold starts.
- Estimated cost for the given period, as well as estimated monthly cost.
- Average, median and 99th percentile invocation time.
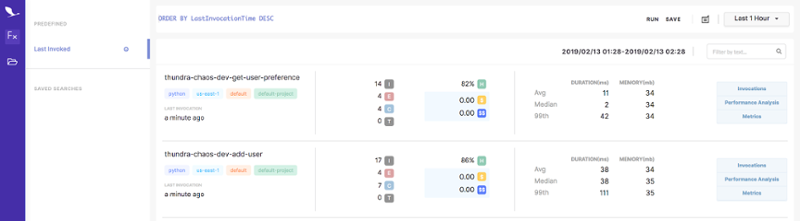
This gives me a useful overview of my functions. You might notice the query “ORDER BY LastInvocationTime DESC” at the top of the screenshot. This query does what it says on the tin, and you can edit it to find other functions. The query language is fairly simple but I still prefer to use the query editor.
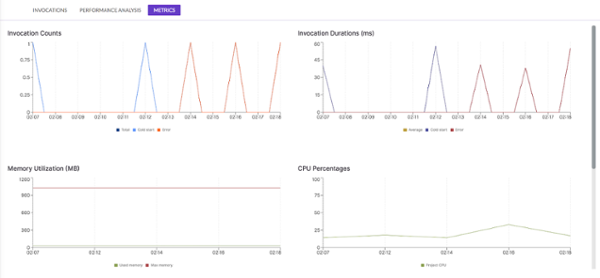
From here, I can navigate to a function and learn more about it. In the function view I can see recent invocations, performance summary and metrics. There are some handy things here:
- Breakdown of where time is spent in each invocation.
- Which invocations were cold starts.
- Which invocations failed or timed out.
- Basic memory and CPU utilization over time.
- A heat map that quickly highlights outliers.
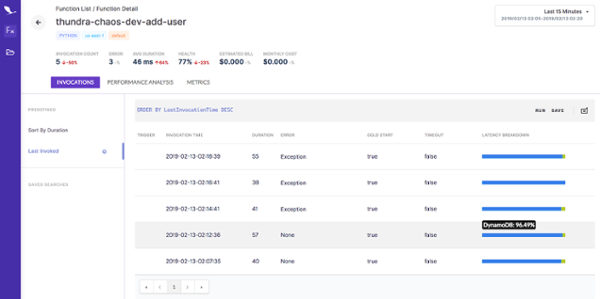
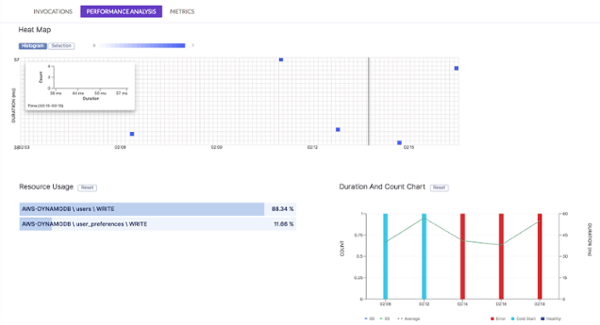
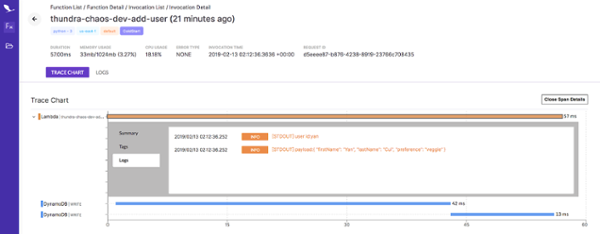
I can then drill into an invocation to see what happened and how much time it spent at each operation. For example, the following invocation made two DynamoDB PutItem operations. The invocation logs are quickly accessible from this screen too. This is nice, as I don’t have to go back-and-forth between different screens to piece together a story of what happened.
Error Injection
The happy path appears to be working, great! Now let’s see if we can uncover some weaknesses by injecting failures into the functions.
Identify missing error handling
In the demo app, the user’s details and his preference are stored in two DynamoDB tables. When a user signs up, he or she can provide an optional preference field. When the it is omitted, we will skip the write operation to the user_preferences table.
Adding the user to the system is our main concern here. It should take precedence over recording the optional preference field. So what should happen if we fail to save the user’s preference? Should a failed write to the user_preferences table disrupt the user sign up flow (by returning a 500)?
So let’s see what actually happens!
To simulate a failure to write to the user_preferences table, we need a way to target the operation. We can use the FilteringSpanListener for that.
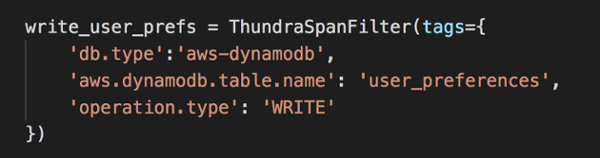
First, we need to create an instance of ThundraSpanFilter. In this case, we used the tags db.type, aws.dynamodb.table.name and operation.type to home in on the right span. You can find the available tags by clicking and expanding the corresponding span in the UI.

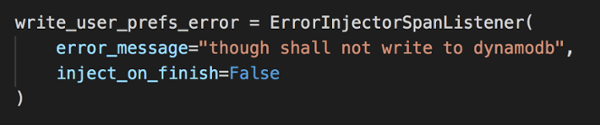
Next, we need to define the error to inject with ErrorInjectorSpanListener. Notice that we set inject_on_finish to False. This is so that error is injected before the DynamoDB operation is performed.
Finally, have to create and then register a FilteringSpanListener. It’s how we link the span filter (the “where”) to the error we want to inject (the “what”).
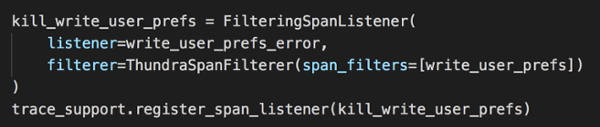
Redeploy the function and curl the add-user endpoint again. You will see the write operation against the user_preferences table is failing.
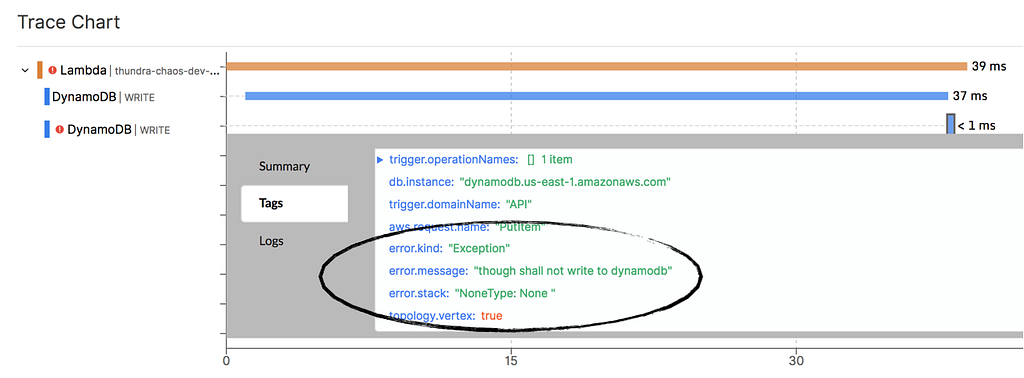
Great! We found a missing error handler, time to go back and fix the issue. We still want to save the user’s preference. We just don’t want the failure to stop the user from signing up, which is a business critical flow. Maybe we can queue up a task in SQS to retry the failed DynamoDB operation? The retry can then be done outside of the HTTP handler where we don’t have the urgency to respond to the caller quickly.
Identify missing fallback
In the get-user-preference endpoint, we need to fetch a user’s preference by his/her user ID. What should happen if the DynamoDB GetItem operation fails? Suppose 95% of our users don’t specify a preference, then maybe we could return a fallback instead.
To see what actually happens, let’s create and register another FilteringSpanListener. This time, we’ll target the READ operation against the user_preferences table instead.
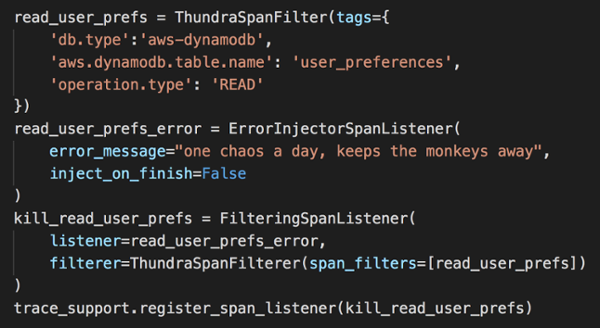
Redeploy and curl the get-user-preference endpoint. Now you should see the operation has failed.
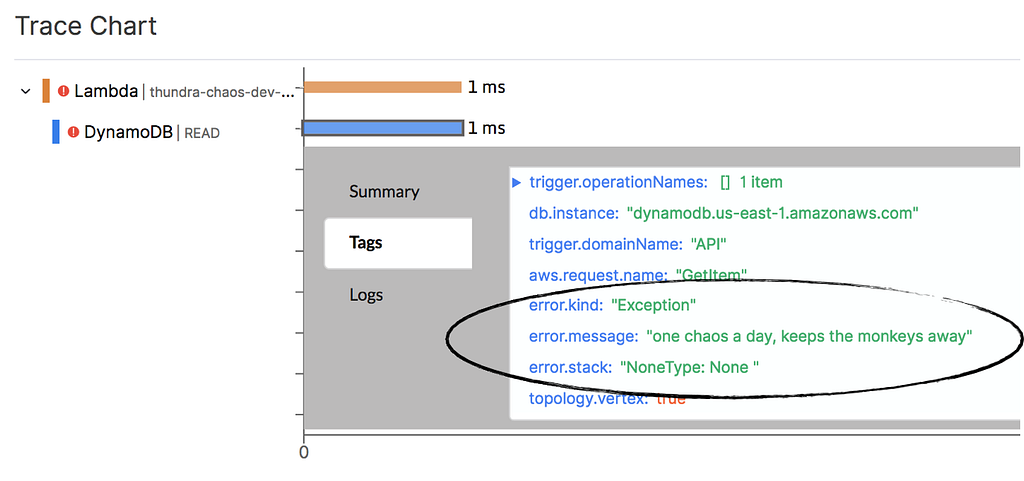
Alright, we have identified another weakness in our code. We should be using fallbacks when the primary data source (DynamoDB) is unavailable.
Missing timeout on outbound HTTP requests
The external services we depend on can often experience performance problems. These might be load related, or sometimes caused by networking issues in AWS. Since our API functions depends on them to function, we need to anticipate and deal with these issues. Also, bear in mind that most API functions have a short timeout, typically between 3 to 6s. We wouldn’t want our functions to timeout because a downstream system is slow to respond. That would create a chain of errors that goes all the way back to the user, commonly known as “cascade failures”. Instead, we should timeout outbound HTTP requests before they timeout our invocations.
Let’s simulate what happens when the write to the user_preferences table is slow. We can do this with the LatencyInjectorSpanListener. We can reuse the filter we set up earlier, but we need another FilteringSpanListener.
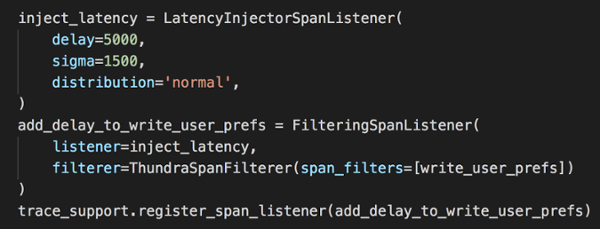
Redeploy the function and curl the add-user endpoint. Now you’ll see that the endpoint is performing sluggishly.
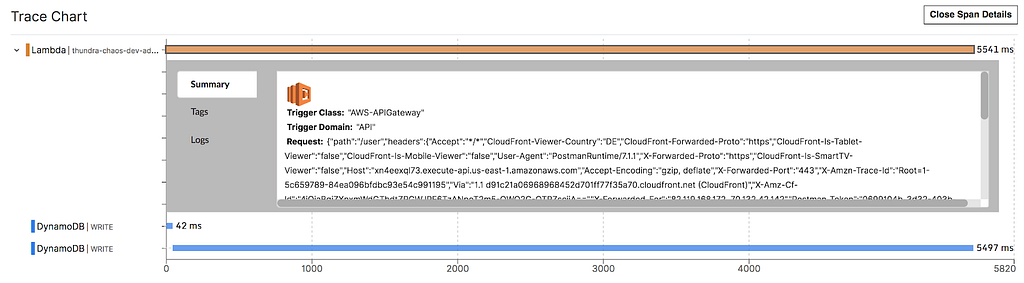
To see how much latency was injected, click on the slow DynamoDB WRITE operation. Look for the thundra.span_listener.info tag, and you’ll see that 5478ms was injected in this case.

You might also experience the occasional 500 response when the invocation times out. This is not great, but what should happen instead?
We can add a timeout to the request, and queue up a task to retry the operation as before. When we retry the operation, we can have a more generous timeout because the latency is not user facing. We do, however, need to make sure the operation is idempotent. This is because the original PutItem operation might have succeeded. We just didn’t have the time to wait for the response to confirm whether it did or not.
Configuring span listeners via env vars
So far we have seen how you can configure and register span listeners to inject different forms of failures by code. However, this approach makes it hard to turn failure injection on and off quickly. You have to make code changes and then redeploy your function each time.
Fortunately, Thundra also lets you do the same with environment variables. You can configure and register a FilteringSpanListener by setting the thundra_agent_lambda_trace_span_listener environment variable. The basic structure of this environment looks like this:

For more detail on how this works, please refer to the Thundra documentation here.
Conclusions
So that’s how you can do error and latency injection using the Thundra SDK. It’s useful for simulating a whole host of possible failures and see how they affect your system.
The demo app in this post is basic and doesn’t really illustrate the power of chaos engineering, but Thundra’s SDK is capable of injecting the complex chaos when needed. As I have spoken about this topic before, the need for chaos engineering really comes into the fore as your system grows. You will end up with many services, with interdependencies between them.
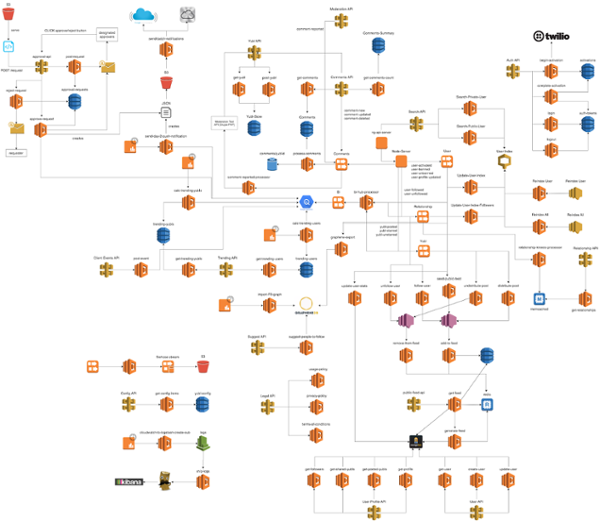
It becomes exponentially more difficult to predict failure behaviours. Failure to a single system can have knock-on effects to many other systems. The symptoms might be hard to detect, but nonetheless still impactful to your users.
Chaos test your Lambda functions with Thundra was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.