Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
To improve data sorting for push notifications, Alibaba’s Xianyu team reworked its approach to database structure, enabling its service to better target user populations.
As Alibaba’s second-hand trading platform Xianyu(闲鱼) has grown and developed, the amount of data it has to sort through has risen astronomically. With hundreds of millions of users, each with over one hundred dimensions for data indicators, user data presents a technological challenge for Alibaba: How can you quickly screen for a targeted population to carry out targeted customer operations using push notifications?
Pushing is the quickest way for Xianyu to get information to users. The most common pushing method for Xianyu is to first calculate the push population offline, prepare the corresponding push message, and then push messages at a specified time on the next day.
Generally, pushing is a periodic task. However, for pushing tasks that need to be sent immediately, BI personnel must manually intervene. Each push task occupies half of a day on average for BI personnel to develop, and the operation can be troublesome due to the difficulty of identifying user populations to push to from the user data.
Many existing solutions in the industry take minutes or even hours to generate query results when handling large amounts of data. This article explores Xianyu’s solution for high-efficiency data screening, statistics and analysis in big data scenarios, enabling its BI personnel to use any combination of query conditions to screen data that can be used to form pushing strategies within milliseconds.
Identifying the Solution
Looking at the challenges its platform faces, the Xianyu team realized that sorting data related to pushing is a typical OLAP scenario.
A simple comparison of OLTP and OLAP is as follows:
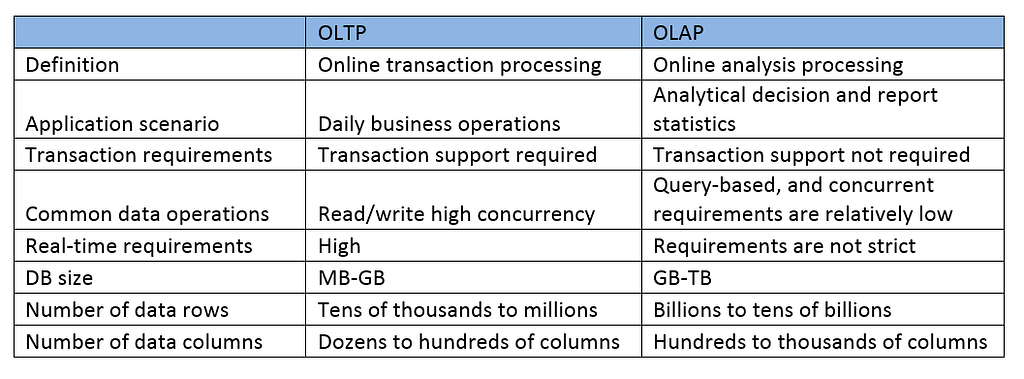
Specifically, it involves querying large databases with millions, or even billions, of rows of data, for which the high read/write concurrency or the transaction support of OLTP is unnecessary.
Based on this conclusion, the team further realized that a column storage database presented the best approach — specifically, Alibaba Cloud’s HybridDB for MySQL.
Columns beat rows
Row storage databases commonly used for OLTP such as MySQL and Oracle are poor solutions for Xianyu’s needs. Row storage is suitable for nearline data analysis, for example, in scenarios that require querying all the fields of a certain number of eligible records in the table. It does not scale well if you have a large number of rows and only need to query a small number of fields.
A simple comparison of the characteristics of row storage and columnar storage is as follows:
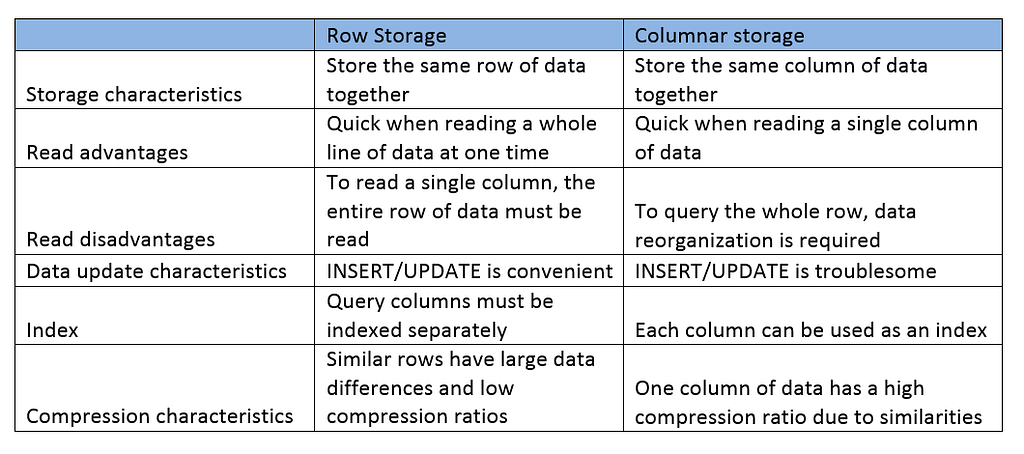
For example, consider a scenario where you have a table with 20 fields and you need to calculate the average user’s age. If the table uses row storage, the database needs to scan the whole table and traverse all the rows. A separate index or composite index can mitigate this, but only for commonly used conditional queries. As soon as you need to query a non-indexed field, the database needs to scan the entire table. When you have hundreds of millions of rows, scanning the whole table can take a significant amount of time.
Columnar storage is much better in this scenario. The database only needs to locate the age column, scan the data from this column to get all the ages, and then calculate the average value. Theoretically, the performance is 20 times faster than row storage since you only need to read one column of data.
Which columnar storage is best?
Xianyu comprehensively reviewed Alibaba Group’s various columnar storage DB products (ADS/PostgreSQL/HBase/HybridDB), and evaluated their respective read/write performance, stability, syntax comprehensiveness, and development and deployment costs.
The most commonly used columnar storage database is HBase. However, its design makes it unsuitable for Xianyu’s requirements. It uses a rowkey as the core part of its design. Common filtering conditions are combined and integrated into the rowkey, and queries are done through the Rowkey’s get (single record) or scan (range) functions. It is designed for unstructured data that has a limited number of filtering conditions.
For Xianyu, since all fields need to be used as filtering conditions, structured storage is still needed, and low latency is required for queries. Of the remaining solutions offered by the Alibaba Group, HybridDB for MySQL made the best choice.
For Xianyu, HybridDB for MySQL provides the following features that allow to it provide millisecond response times to multi-dimensional queries in big data scenarios:
· A high-performance columnar storage engine and its predicate computing capabilities with built-in storage, which can use a variety of statistical information to quickly skip data blocks for fast screening.
· Smart indexing technology, which automatically creates indexes for a table and can combine multiple predicate conditions based on the indexes for screening. (Xianyu does not need to build its own indexes.)
· A high-performance MPP+DAG fused computing engine that combines high-concurrency and high-throughput modes to achieve high-performance vector computing, this allows the computational engine and storage to work closely together to speed up computation.
· Support for a variety of data modeling techniques such as star modeling, snowflake modeling, and aggregation sorting. Business moderate data modeling enables better performance indicators.
In addition to performance, Hybrid DB for MySQL was also ideal for Xianyu because MySQL and BI are compatible with each other with complete SQL support. Further, it included support for spatial search, full-text search, and complex data types (multi-value columns and JSON).
Pushing on HybridDB
Xianyu implemented HybridDB for MySQL for its population selection system, and integrated the population selection system with its original Push system. This greatly improved the preparation data and transmission efficiency of pushing and freed up development resources.
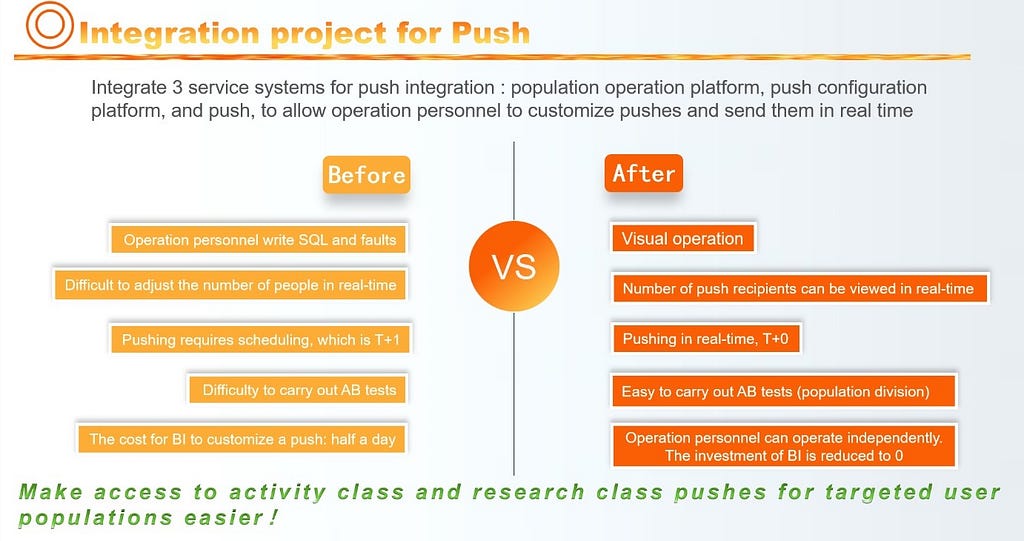
HybridDB for MySQL not only provides strong underlying support for Xianyu’s targeted user operations, but can also be applied to other business scenarios, such as targeted pushing of home page pictures and other scenarios that require hierarchical user operations, thus increasing the optimization space for the Xianyu service.
System architecture
In the following image you can see the three-layer system architecture used by Xianyu for its population selection system used with Push, consisting of an offline data layer, a real-time computing layer (HybridDB), and an application system.
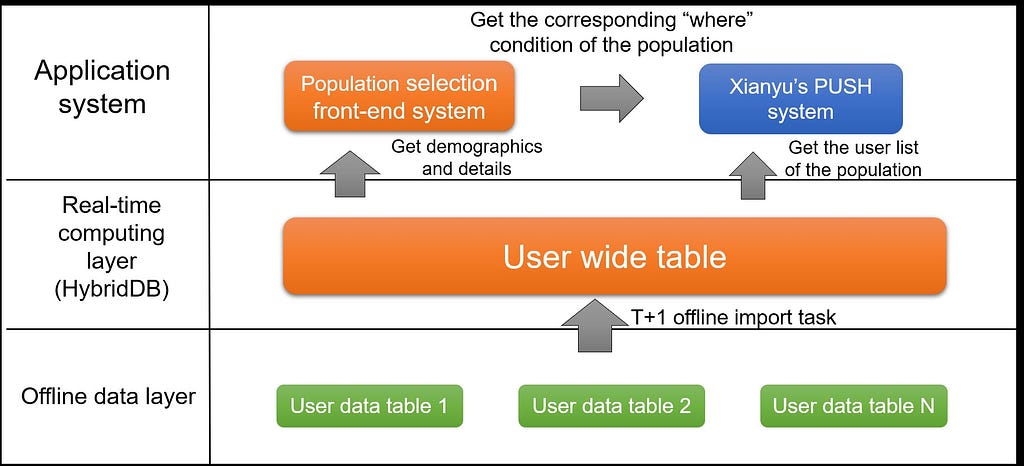
In the offline data layer, user dimension data is distributed in the offline tables for each business system. The offline T+1 timing task is used to aggregate and import the data into the user wide table at the real-time computing layer.
The real-time computing layer, according to the screening conditions of the population, will query the eligible number of users and list of user IDs from the user wide table to provide services to the application system.
The population selection front-end system forms the first part of the application system layer, and provides a visual interface for operational personnel to select and save screening conditions as a population for analysis or pushing. Each population corresponds to a SQL store, which resembles:
select count(*) from user_big_table where column1> 1 and column2 in (‘a’,’b’) and (column31=1 or column32=2)
SQL supports multiple layers and/or nested combinations of any fields for querying. With SQL saving a population, when the data in the user table changes, running SQL can retrieve the latest users in the population and update it accordingly.
Xianyu’s PUSH system forms the second part of the application system layer. It obtains the corresponding “where” condition of the population from the population selection front-end system, obtains the user list in a paging manner from the real-time computing layer, and pushes messages to the user. During its implementation process, the performance of paging queries was a key focus.
Optimizing paging performance
When paging, if the size of the population is large (> 10 million), the query performance significantly reduces as the number of queried pages increases. To improve performance, row numbers were added to the population data and they were exported to MySQL. The following table shows that structure.
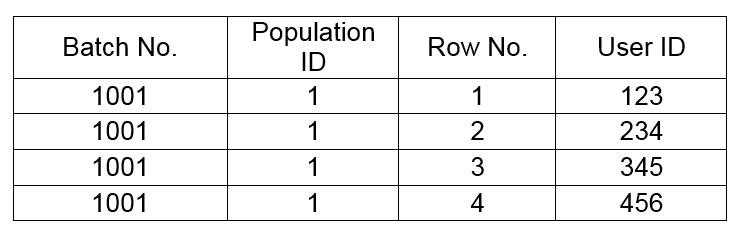
Each time the population is exported, a new batch number is added, and is time stamped and incremented.
The row number automatically increments from 1 for each batch number.
The structure uses a composite index made up of “Population ID” + “Batch No.” + “Row No.”. This allows the PUSH system to use an index query to replace paging and improve the efficiency and performance of querying large-number pages. HybridDB’s powerful data export capability more than compensates for the extra cost of exporting data, with millions of data points taking only seconds to export.
Looking to The Future
Xianyu’s model ensures that the results of combined queries are returned within seconds from massive multi-dimensional data stores. As a generic technology implementation solution in OLAP scenarios, this technique can be used to transform other original service systems to improve service results and as a reference for similar scenarios.
User data in the population selection engine is currently imported at T+1. The reason is that population-related indicators do not change frequently, and many indicators (such as user tags) are computed offline at T+1, such that the data update frequency of T+1 is acceptable. Later on, a more powerful commodity selection engine based on HybridDB was built.
Xianyu commodity data changes faster than user data. On the one hand, users update their own merchandise at any time they wish. On the other hand, due to Xianyu’s single-stock feature (such that goods are removed from their shelves as soon as they are sold) and various other reasons, the statuses of goods can change at any time. Therefore, our selection engine should be able to recognize these changes in data as soon as possible and make real-time adjustments at the delivery layer.
Based on HybridDB (storage) and real-time computing engines, the Xianyu team has recently built a more powerful real-time selection system called Mach, which readers can look forward to exploring in future articles covering developments at Xianyu.
Alibaba Tech
First hand and in-depth information about Alibaba’s latest technology → Facebook: “Alibaba Tech”. Twitter: “AlibabaTech”.
A Push in the Right Direction: Improving Notification Targeting was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.