Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Sharing my playbook for graph database projects. Will be happy to answer any questions or offer advice.
Ask Siri who is the quarterback of the New York Jets and you get a list of the current quarterbacks right away. Ask Siri who is Taylor Swift’s boyfriend, and it will know.
Ask who are the members of the Irish band, The Chieftains, and Siri doesn’t know. Even if you ask about who are the members of the Irish Band U2, it doesn’t know. It can provide you information about Bono, but doesn’t have an idea of the members of U2.
However, Google Assistant know to answer the questions above. Can you guess what happened?

Despite an almost 50% growth YoY of graphs, the tech sees a small fraction of the database market share. Yet it’s power, flexibility and speed of development reamins amongst one of the best. Better yet, it leads the way to use cases that are beyond the grip of any other system i have worked with.
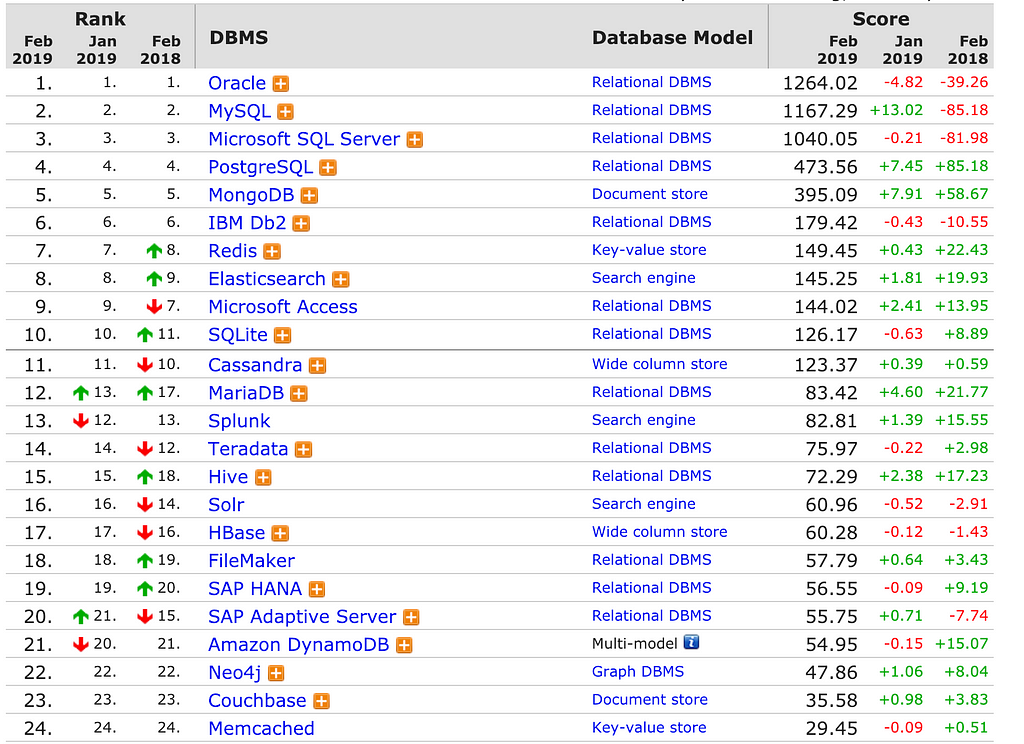 Source: https://db-engines.com/en/ranking
Source: https://db-engines.com/en/ranking
As an independent consultant for the past 7 years, i have produced a playbook that can help you levrage the power of graphs in 5 days. Think of it as a high-performance factory. Below, you’ll find the needed steps and how to go about them.
Let’s have a look at how your company or product can levrage this tech. What are the steps you can go through, and what results can be expected at the very end of this process?
Overview
- Import your current data
- Basic queries
- Handle data duplication
- Network Analytics/Advanced graph algos
- Deployment
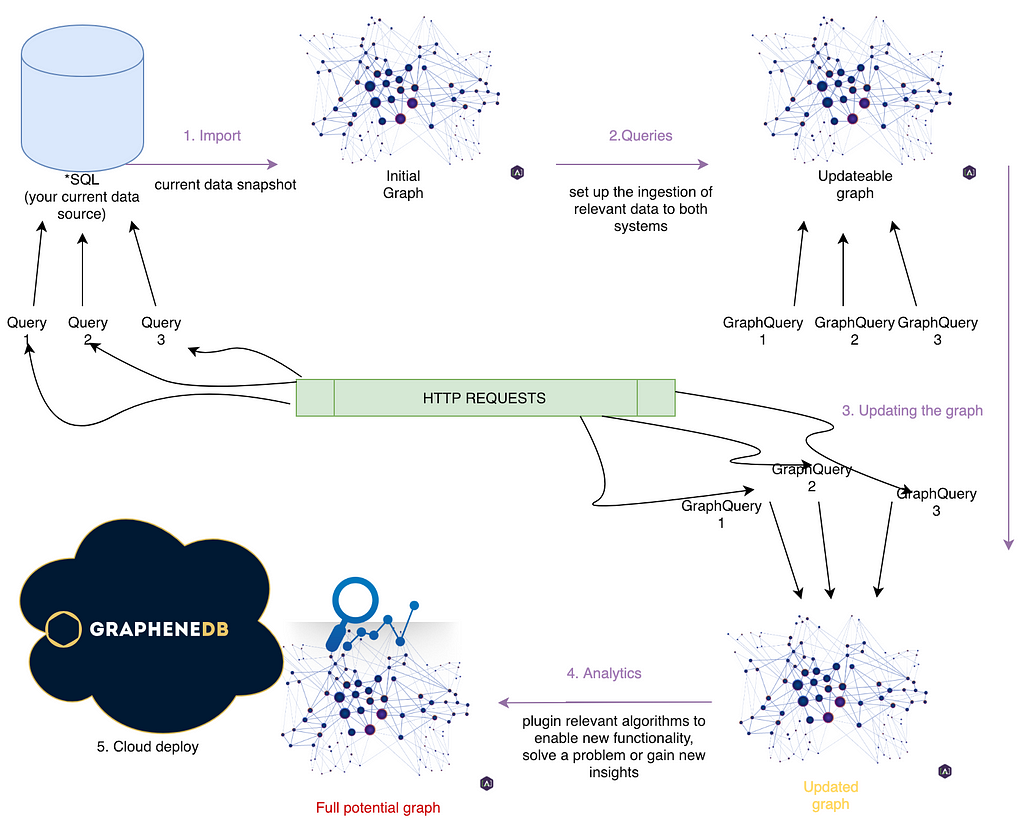 1. Import
1. Import
You already have one or several databases(mysql/postgresql, mongodb, Cassandra, etc.). The goal of this stage is to explore the current structure of your data and translate it into a graph. Part of this stage is also known as ETL(Extract-Transform-Load).
If working with an external consultant, make sure to encrypt/obfuscate sensitive data and get an NDA in place, before handing it over.
Using the right tools, this can happen in under one day. Naturally, actually loading the data in the graph may vary, timewise. Expect to let the system run for about 30 minutes for each 10GB. It’s quite rare that all the data needs to be imported, so good communication before starting the work goes a long way.
 From 2 tables in a relational database, to nodes and relationships in a graph database.
From 2 tables in a relational database, to nodes and relationships in a graph database.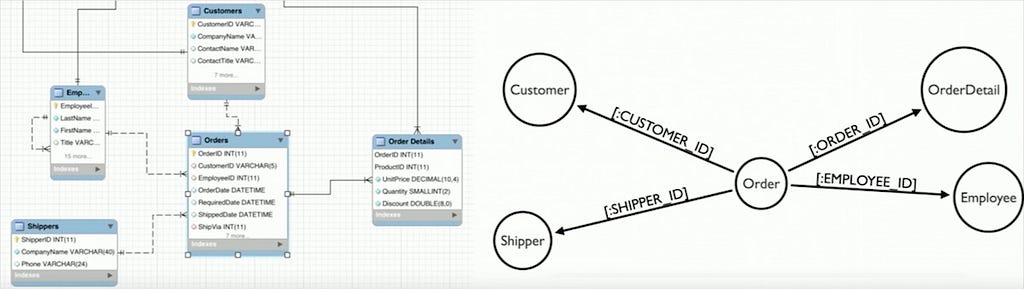
Side-effect bonus: Non-technical people can understand the structure of the data, as graph databases are very whiteboard friendly.
2. Basic queries
We need to keep our new data in sync, so we need to connect existing actions that create, update or delete items in your tabular db system to the new graph database.
In this step, we simply evaluate your current SQL queries, and translate them to Cypher.
This step usually spurs some very nice Aha moments. What was impossible in the tabular view(doing 5 joins in a row, in real-time) is now highly achievable.
If we’re talking about 10 queries and 4 pipelines that need to also direct the data to the graph, this can happen in one day. Otherwise, it might vary.
Testing can be done by running two systems in parallel. Let’s name the two databases SQL1 and Neo2. Here is how you would test you got this step right:
- Do an import from SQL1 to Neo2.
- Apply a sequence of queries to both systems. Example: Query1, Query2, Query1 to SQL1 and GraphQuery1, GraphQuery2, GraphQuery1 to Neo2.
- Do an import of SQL1 to Neo2. Assert that the 2 databases contain the same data.
Benchmarking the two systems will prove which one handles certain queries better. Some functionality previously unattainable with SQL will become possible with Cypher.
Side-effect bonus: An understanding of how graphs work. The first new possibilities start to unravel.
3. Data duplication
Take the queries in step 2, and connect them to your current systems. These could be methods that handle http calls in your microservices, database triggers, etc.
Be sure to use threads, or some async mechanism, so submission of the data to the databases happens in parallel.
Hint: if updating Neo4j in real-time is not a priority(using it for analytical capabilities, to present aggregates of the info, recommender system that does not need fresh data, etc) you can use a smaller database instance and use a queue(Kafka, RabbitMQ) to throttle the update/usage.
4. Network analytics and advanced graph algorithms
I have applied over 200 algorithms on top of graphs. It’s science, yes, but it’s also about having the intuition of what is possible and knowing how to ask the right question(just like in real life).
In my consulting projects, only once have i had to write a complex algorithm from scratch. Usually, you will find everything you need, under a permissive Open Source license.
If your engineers know what they’re doing, this can take less than 2 days.
For an in-depth dive and some intuition on what can be achieved, have a look at the top 5 interesting applications of graph databases.
5. Deployment
Deploying to the cloud is a hot topic nowadays, and LinkedIn predicts that the hottest skill for techies this year will be cloud knowledge. While building the Chinese version, LinkedIn used Neo4j, the leading graph database. Their conclusion was that they were able to move very fast, and didn’t have the need for a database administrator.
Deployment to a managed cloud service can happen in a couple of hours. Deploying your own pipe can take a couple of days.
Last tip: while you won’t be needing an administrator, you will be needing a cloud deployment, and i use GrapheneDB for most of my projects.
Good luck, i wish the new functionality you build returns an astronomical ROI. If you want to make sure, hire me now!
From zero to graph hero, in 5 days and 5 steps was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.