Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Evaluating Learning to Rank Algorithms to Improve Relevance in Job Search
What we learned from experimenting with “smart” relevance ranking.

Handshake’s mission is to democratize opportunity by making sure that every student, regardless of where they go to school or who they know, can find a meaningful career. At the core of Handshake’s student product is a job search engine, where our 14 million students and young alumni can discover jobs from more than 300,000 employers.
Towards the end of last year, our data and platform teams decided to experiment with fundamentally different ways to power job search. Here, we’ll discuss how we approached the problem, the service we built, and what we learned from the process.
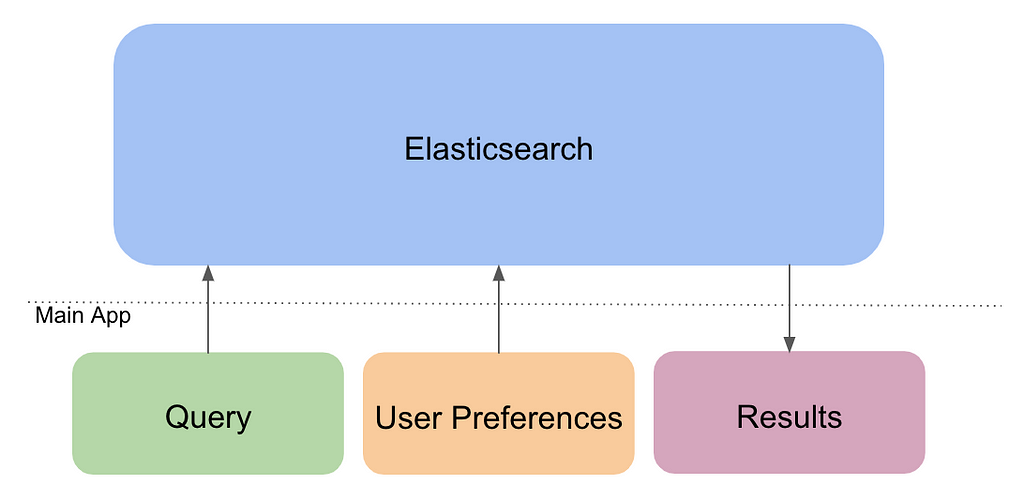
How We Currently Do Job Search
As with typical search engines, we index our documents, which are job postings in our case. The documents are stored in an inverted index, which allows for quick, full-text search. An inverted index maps all the unique tokens in a document to a list of the documents in which they each appear. We store our indexed documents in Elasticsearch.
When a user types in a query, we break down that query into tokens and look up the tokens in the inverted index. After stemming and removing stopwords, we use numerous strategies to look up the tokens in the inverted index, including partial-word and fuzzy word matching. Finally, the search engine ranks the job postings and returns the results.
To rank the postings, we use Elasticsearch’s tf-idf scores; however, we’ve also tried to improve this ranking using other things we know about students. For example, when a student creates an account on Handshake, we ask them to select their preferred industries, locations, and job roles or occupations,. We then boost the scores of the postings that match their preferences.
What is Learning to Rank?
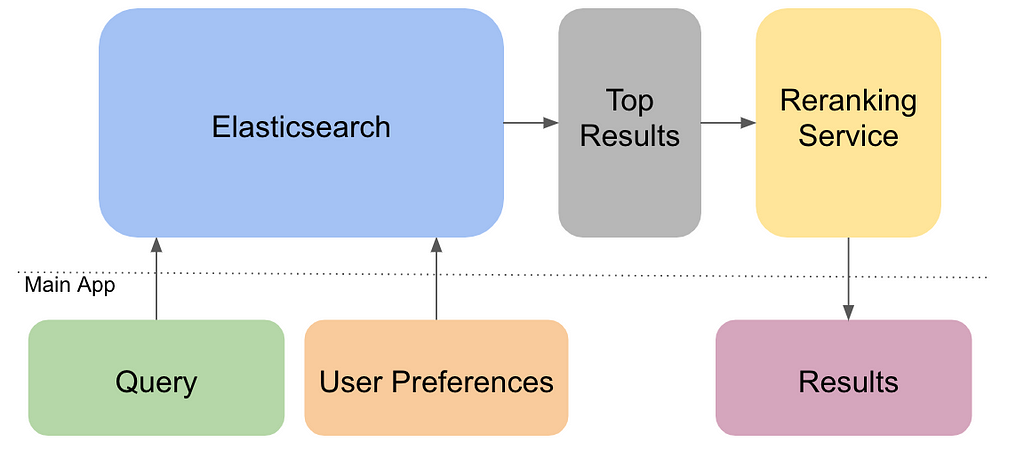
Learning to rank (LTR) is the application of machine learning to relevance ranking. LTR is typically used as a reranking layer on top of an existing search engine, which means that after the search engine returns the top x documents, the LTR service simply reranks those x documents before returning the results.
This architecture is preferred over replacing the whole search engine with the machine learning model for two reasons. First, traditional search engines are typically good enough at returning a set of relevant documents (measured by recall and precision). Our goal is to improve how the documents are ranked. We do not need to train a machine learning model to do both tasks, so we use LTR to specifically improve relevancy ranking. The second reason for using LTR as an additional layer is for performance; reranking 500 or 1000 postings is much quicker than reranking tens of thousands of postings.
Implementing LTR for Job Search
We considered two different implementations of LTR: using the Elasticsearch LTR plugin and creating our own service using Ranklib (the library of reranking algorithms that the Elasticsearch LTR plugin is built on). We decided to go with the latter option, as it would not make us dependent on a specific version of Elasticsearch and allows for more configurability.
The Data and Model
Independent of the overall architecture, LTR relies on a supervised machine learning model, which must be trained. We used Ranklib to train the model, requiring that we use QID (query-ID) file format for both the training set and the data to rerank. In QID files, we assign an ID to each query and indices to each (one-hot encoded) feature. In our case, the queries are not driven by keywords that a user might type in, but rather by the user’s personal, pre-selected job preferences. To build a training set, we assigned a relevance score to each job based on the behavior of the student upon seeing it:
- 0 — no action,
- 2 — clicked on the job,
- 3 — favorited the job,
- 4 — applied to the job.
Using the users’ behavior theoretically allows the model to find latent patterns that we would not be able to detect. The features are characteristics of the jobs or employers and the user — like whether or not the employer belongs to the user’s preferred industry, or whether or not the employer is hiring students from the user’s school year. We used this training set to train models using each of Ranklib’s eight reranking algorithm implementations, settling on LambdaMART for the MVP reranking service as it had the best NDCG@10 score.
The Reranking Service
With our trained model, we set out to make a service we could use as the reranking layer of our search architecture. The original idea was to write a Go service that would execute the Ranklib bash command for every search. However, we realized how inefficient this would be as every request would require a jvm be spun up to execute the Ranklib jar.
To solve this problem, we decided to write a Java service. Not only did this help with efficiency, but it also allowed us to make some customizations allowing for easier integration with our main app. For example, writing our own API instead of using Ranklib’s rerank method allowed us to pass a JSON object of jobs to rerank, instead of a file in QID format.
Takeaways
The best way to know if our reranking service performed better than only using Elasticsearch would be to deploy it to production and see if more students were clicking on and applying to jobs. We are currently evaluating productionizing this service and comparing it against newer options that we believe could perform better (more to come on that later!).
It’s important to note that machine learning does not solve everything. And while using machine learning to solve relevance ranking sounds great, there are many other low-investment ways to improve how we show jobs to students. For example, we can make sure that we are collecting more accurate and up-to-date preferences from students so we can use our current framework to show them the best jobs possible. Or we could empower users to make better searches, and therefore find better results, by providing more helpful search keyword recommendations.
One of the biggest takeaways from this project, which will help inform the future of search at Handshake, is that many students are still in an exploratory mode. They are unsure of what they are looking for, or, at the very least, are unsure of how to translate their goals into search keywords. In fact, 59% of searches use no keywords, relying on filters and our job ranking. Handshake is uniquely positioned to help these users as we focus exclusively on early talent. In the coming months, we will be rethinking how we approach job search to determine the best way to help all of our users find and build meaningful careers.
Further Reading
https://medium.com/@purbon/learning-to-rank-101-5755f2797a3a
http://times.cs.uiuc.edu/course/598f14/l2r.pdf
https://www.ebayinc.com/stories/blogs/tech/measuring-search-relevance/
https://opensourceconnections.com/blog/2017/02/14/elasticsearch-learning-to-rank/
https://arxiv.org/pdf/1810.09591.pdf
If you have thoughts on any of the topics discussed here, feel free to reach out (@samhitakarnati on Twitter)!
Learning to Rank for Job Search was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.