Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Seeing the (Random) Forest Through the (Decision) Trees
The following was inspired by the Hacker Noon article How it Feels to Learn JavaScript in 2016 and was originally published on Towards Data Science. Do not take this article too seriously. This is satire so do not treat it as actual advice. Like all advice, some of it is good and some of it is terrible. This piece is just an opinion, much like people’s definition of data science.
I heard you are the one to go to. Thank you for meeting with me, and thanks for the coffee. You know data science, right?
Well, I know of it. I went to PyData and O’Reilly Strata last year and built a few models.
Yeah, I heard you gave a great presentation on machine learning to our company last week. My coworker said it was really useful.
Oh, the cat and dog photo classifier? Yeah, thanks.
Anyway, I have decided I can no longer ignore data science, artificial intelligence, and machine learning. I have worked as an analyst and consultant for years shuffling numbers around in Excel workbooks, doing pivot tables, and making charts. However I keep reading articles saying AI is going to take jobs away, even white collar ones like mine.
 This is all you need to become a confident data scientist (as of 2013). Totally achievable, right? (SOURCE: Swami Chandrasekaran)
This is all you need to become a confident data scientist (as of 2013). Totally achievable, right? (SOURCE: Swami Chandrasekaran)
I Googled how to become a data scientist, found this “roadmap”, and learned what an existential crisis is. Let me ask you this: do I really have to master everything in this chart to become a data scientist?
Short answer, no. Nobody is using this roadmap anymore. It is from 2013. It does not even have TensorFlow in it, and you can scratch some paths in this chart entirely. I think “data science” has become a bit more fragmented and specialized in that time as well. It might be better to take a different approach.
Okay, that makes me feel a little better. So should I go back to school? I read somewhere a lot of data scientists have at least a masters education. Should I get a Masters in Data Science?
Goodness, why would you do that? You have to be wary of “data science” programs that are largely a rebranded “business analytics” degree. Plus, everyday academia tends to lag behind industries and can teach dated technologies. To stay current, you might be better off self-teaching with Coursera or Khan Academy.
Oh.
If you do go to university though, maybe study physics or operations research? It’s hard to say. Anecdotally, many good data scientists I’ve encountered come from those fields. You might be able to find a good “data science” program. I don’t know, go talk to this PhD dropout on his perspectives.
So how do I start self-teaching? Some guy on LinkedIn said those interested in data science should start with learning Linux. Then I go to Twitter and some guy is insistent data scientists should be learning Scala, not Python or R.
That guy on LinkedIn is a few fries short of a Happy Meal. Regarding the Scala guy, please do not go down the Scala rabbit hole. Trust me. It’s 2019. Scala is not happening in the data science community. If it were, PySpark wouldn’t be a thing. And definitely do not listen to language hipsters, like that one guy who is always talking about Kotlin.
Alright? And what about R? People seem to like it.
R is good at mathematical modeling and that’s about it. With Python you get a lot more return on your learning investment, and can do a larger range of tasks like data wrangling and setting up web services.
But R still ranks pretty high on Tiobe, and it has a ton of community and resources. Can it hurt to use it?
Look, you can use R. It is arguably nicer if you are just interested in math, and it has gotten even better with Tidyverse. But data science continues to be about much, MUCH more than math and statistics. Trust me, Python is going to give you more mileage in 2019.
Okay, so… I guess I am learning Python.
You won’t regret it.
Is Python hard? Will it keep me marketable when the robots take over?
Well sure, Python is a pretty easy language. You can automate a lot of tasks and do some cool things with it. But you do not even need Python. Data science is about much more than scripting and machine learning.
What do you mean?
Well, these are all tools. You use Python to get insights from data. Sometimes that involves machine learning, but most of the time it does not. Data science can simply be creating charts. As a matter of fact, you do not even have to learn Python and can just use Tableau. They advertise they can “make everyone in your organization a data scientist” just by using their product.
 Tableau is confident they can solve your data scientist staffing problem
Tableau is confident they can solve your data scientist staffing problem
Wait, what? So I just have to buy a Tableau license and I’m now a data scientist? Okay, let’s just take that sales pitch with a grain of salt. I may be clueless, but I know there is more to data science than making pretty visualizations. I can do that in Excel.
Sure. You got to admit it is slick marketing though. Charting data is the fun stage, and they leave out the painful and time-consuming parts of working with data: cleaning, wrangling, transforming, and loading it. God help you if you need your own custom domain logic when using closed tools.
Yes, and that is why I suspect there is value in learning to code. So let’s talk Python.
Actually, hold on. Maybe you can learn Alteryx.
What?
There’s another software called Alteryx that allows you to clean, wrangle, transform, and load data. It’s great because it uses a drag-and-drop interface to blend data and…
 Alteryx envisions a code-less “data science” experience with their product too
Alteryx envisions a code-less “data science” experience with their product too
Oh my God, please stop. No more drag-and-drop tools. I want to learn Python, not Alteryx or Tableau.
Okay, sorry. I was just trying to make your life easier by avoiding code. Maybe I did it too because our company bought licenses we should be using. But anyway, to learn Python you need to learn a few libraries, such as Pandas for manipulating data frames and matplotlib for making charts. Actually, scratch matplotlib. Use Plotly. It uses d3.js and is much nicer.
I know some of these words. But what’s a data frame?
Well, it’s a functionality to manipulate data in a tabular structure with rows and columns. You can do all these cool transformations, pivots, and aggregations with data frames all within a Python environment.
Wait, so how is any of this different from Excel? I’ve done these tasks since I graduated from college. Does this mean I am already a data scientist?
If you are comfortable branding yourself that way, sure. I would just footnote that self-proclaimed title when you go to parties and write your resumes.
So what makes Python different from Excel?
Python is different because you can do it all within a Jupyter notebook. You can step through each data analysis stage and have the notebook visualize every step. It’s almost like you are creating a story you can share with others. Communication and storytelling is a critical part of data science, after all.
That sounds like PowerPoint. I already do that too. I’m so confused.
Oh my God, no. Notebooks are much more automated and streamlined, and it makes it easy to trace back each step of your analysis. But come to think of it, I just remembered some people do not even like notebooks because the code is not very usable. It is easier to modularize code outside notebooks in case you need to turn it into a software product.
So now data science is software engineering too?
It can be, but let’s not get distracted by that. There are much more pressing things to learn first. To do data science, you obviously need data.
Of course.
And a great place to start is to scrape the web, like some Wikipedia pages, and dump them to our hard drive.
Wait, what are we trying to accomplish again?
Well we are getting some data to practice with. Scraping web pages and parsing it with Beautiful Soup can give us a lot of unstructured text data to work with.
I’m confused. I just finished a great 130-page book on SQL and I thought I’d be querying tables rather than scraping the web. Is not SQL the typical way to access data?
Well we can do a lot of cool things with unstructured text data. We can use it to categorize sentiments on social media posts or do natural language processing. NoSQL is great at storing this type of scraped data, because we can store massive amounts of it without concerning ourselves with making it usable for analytics.
I have heard the term NoSQL. So is that SQL? Anti-SQL? Wait, I think it has something to do with big data, right?
Well first, “big data” is so 2016. Most people are not really using that term anymore, so it is just not cool when you talk like that. Like a lot of exciting technologies, it has passed the peak of its Gartner Hype Cycle and only found its niche in a few places. But NoSQL is basically a product of the “big data” movement and grew platforms like MongoDB.
Okay, but why is it called “NoSQL”?
NoSQL stands for “not only SQL” and supports data structures beyond relational tables. However, NoSQL databases usually do not use SQL, but rather a proprietary query language. Here is how MongoDB’s language compares to SQL:

Oh my gosh, this is terrible. So you’re saying each NoSQL platform has their own querying language? What’s wrong with SQL?
I feel ya. Nothing is wrong with SQL other than its been around for decades. The unstructured data craze was an opportunity to do something different and scale wildly in ways not possible before. However, I guess more folks have concluded there is value in keeping SQL around. It makes analytics much easier. So much, in fact, that many NoSQL and “big data” technologies have scrambled to add a SQL layer in some shape or form. After all, SQL is a pretty universal language even if some people find it difficult to learn.
body[data-twttr-rendered="true"] {background-color: transparent;}.twitter-tweet {margin: auto !important;}
NoSQL is there because SQL is hard to learn. (early argument). Instead you must learn one query language for each tool you use. #losing
— @stahnma
Ugh, okay. So what I am gathering here is that NoSQL is not critical anymore to learn as a data scientist, unless somehow my job requires it. It sounds like I am safe just knowing SQL.
The more I think about it, yes, I suppose you are right, unless you gravitate towards being a data engineer.
Data engineer?
Yeah, data scientists kind of broke up into two professions. Data engineers work with production systems and help make data and models usable, but do less machine learning and mathematical modeling work which is left to the data scientists. This was probably necessary since most HR and recruiters cannot see past the “data scientist” title. Come to think of it, if you want to be a data engineer I would prioritize learning Apache Kafka more than NoSQL. Apache Kafka is pretty hot right now.
Here, this Venn diagram may help you. To get a “data scientist” title, you should be somewhere in the Math/Statistics circle ideally on an overlap with another discipline.
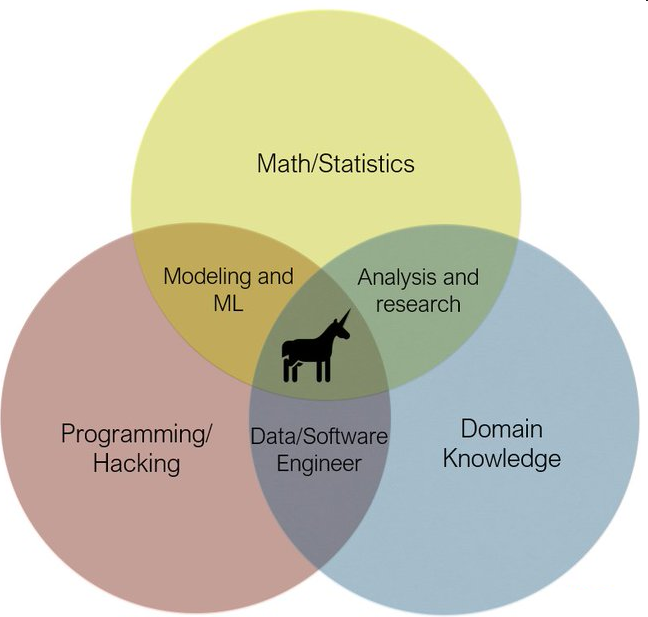 Data Science Venn Diagram
Data Science Venn Diagram
Alright, I have no idea whether I want to be a data scientist or data engineer at this point. Let’s just move on. So going back, why are we scraping Wikipedia pages?
Well to serve as data inputs for natural language processing, and do things like create chatbots.
Like Microsoft’s Tay? Is this bot going to be smart enough to forecast sales and help me launch new products with the right amount of inventory? Is there an inherent risk it becomes racist?
Theoretically, it might. If you ingest news articles maybe you can create some models that identify trends that results in business decision recommendations. But this is really REALLY hard to do. Come to think of it, this may not be a good place to start.
Okay, so… natural language processing, chatbots, and unstructured text data is probably not going to be my thing?
Probably not, but note that’s a lot of data science nowadays. Silicon Valley companies like Google and Facebook deal with a lot of unstructured data (like social media posts and news articles), and obviously they have a lot of influence in defining what “data science” is. Then there are the rest of us using business operational data in the form of relational databases, and using less exciting technologies like SQL.
Yeah, that sounds about right. I guess they also devote their unstructured data talents largely to mining user posts, emails, and stories for advertising and other nefarious purposes.
It is what it is. But you might find Naive Bayes interesting and somewhat useful. You can take bodies of text and predict a category for it. It is pretty easy to implement from scratch too:
You are right, Naive Bayes is kind of cool. But I don’t see any value in unstructured data beyond this.
We will move on then. So you are working with a lot of tabular data: spreadsheets, tables, and lots of recorded numbers. It almost sounds like you want to do some forecasting or statistical analysis.
Yes, finally we are getting somewhere! Solving real problems. Is this where neural networks and deep learning comes in?
Whoa, hold your horses. I was going to suggest starting with some normal distributions with means and standard deviations. Maybe calculate some probabilities with z-scores, and a linear regression or two.
But again, I can do all that in Excel! What am I missing here?
Well… um… yes that’s correct, you can do a lot of this in Excel. But you get a lot more flexibility when you write scripts.
Like VBA? Visual Basic?
Okay, I’m going to start over and pretend you didn’t say that. Excel does have great statistical operators and decent linear regressions models. But if you need to do a separate normal distribution or regression for each category of items, it is much easier to script in Python rather than creating hellish formulas whose length can become a distance-to-the-moon metric.
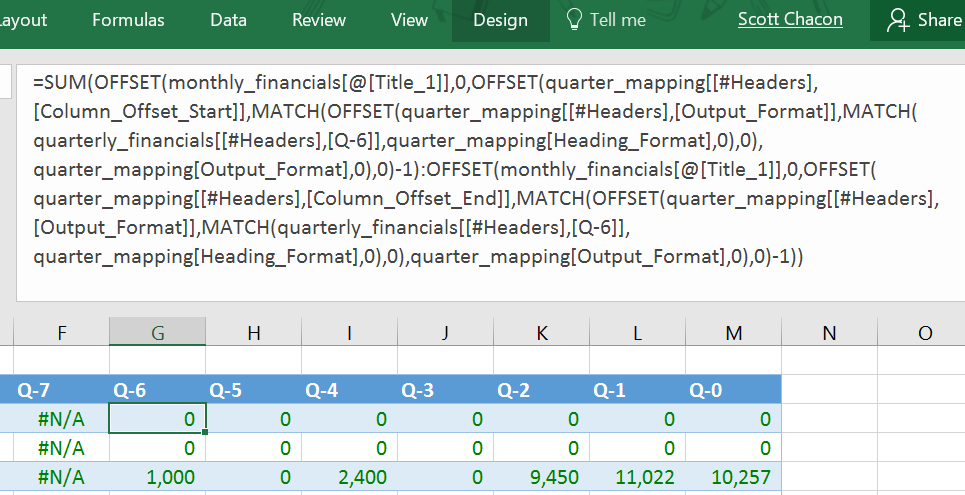 When you become advanced at Excel, you inflict pain on everyone who works with you.
When you become advanced at Excel, you inflict pain on everyone who works with you.
You can also use the amazing library scikit-learn. You get a lot more powerful options for different regression and machine learning models.
Okay, fair enough. So I guess this segues into mathematical modeling territory. When it comes to the math stuff, where do I start?
Well conventional wisdom says linear algebra is the building block for a lot of data science, and this is where you should start. Multiplying and adding matrices together (called a dot product) is something you will do all the time, and there are other important concepts like determinants and eigenvectors. 3Blue1Brown is pretty much the only place you will find an intuitive explanation of linear algebra.
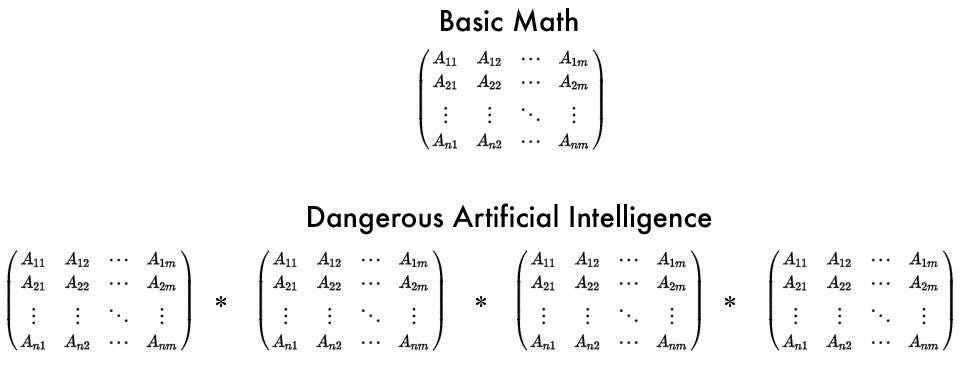
So… taking a grid of numbers and multiplying/adding it against another grid of numbers is something I will be doing a lot? This sounds really meaningless and boring. Can you give me a use case?
Well… machine learning! When you do a linear regression or build your own neural network, you will be doing a lot of matrix multiplication and scaling with randomized weight values.
Okay, so do matrices have anything to do with data frames? They sound similar.
Actually, hold on… I’m rethinking this. Let me walk that statement back. In practicality, you will not need to do linear algebra.

Oh come on! Seriously? Do I learn linear algebra or not?
In practicality, no you probably do not need to learn linear algebra. Libraries like TensorFlow and scikit-learn do it all for you. It’s tedious and it’s boring anyway. Ultimately, you might want to get a little bit of insight on how these libraries work. But for now, just start using the machine learning libraries and completely ignore linear algebra.
Your uncertainty is unsettling me. Can I trust you?
Also, before I forget. Don’t actually use TensorFlow. Use Keras because it makes TensorFlow much easier to work with.
Speaking of machine learning, does linear regression really qualify as machine learning?
Yes, linear regression is lumped into the “machine learning” tool bag.
Awesome, I do that in Excel all the time. So can I call myself a machine learning practitioner too?
*Sigh* technically, yes. But you might want to expand your breadth a bit. You see, machine learning (regardless of the technique) is often two tasks: regression or categorization. Technically, categorization is regression. Decision trees, neural networks, support vector machines, logistic regression, and yes… linear regression all execute some form of curve-fitting. Each model has pros and cons depending on the situation.
Wait, so machine learning is just regression? They all are effectively fitting a curve to points?
Pretty much. Some models like linear regression are crystal clear to interpret while more advanced models like neural networks are by definition convoluted, and are difficult to interpret. Neural networks are really just multi-layered regressions with some nonlinear functions. It may not seem that impressive when you have only 2–3 variables, but when you have hundreds or thousands of variables that is when it starts to get interesting.
Well when you put it that way, sure. And image recognition is just regression too?
Yes. Each image pixel basically becomes an input variable with a numeric value. That reminds me, you have to be wary of the curse of dimensionality. This basically means the more variables (dimensions) you have, the more data you need to keep it from becoming sparse. This is one of many reasons why machine learning can be so unreliable and messy, and can require ridiculous amounts of labeled data you will likely not have.
body[data-twttr-rendered="true"] {background-color: transparent;}.twitter-tweet {margin: auto !important;}
A data scientist is a statistician who lives in San Fransisco" #monkigras
I now have a lot of questions.
(Here we go)
What about problems like scheduling staff or transportation? Or solving a Sudoku? Can machine learning solve all these problems too?
Well when you go into these types of problems, there are folks who would say this is not data science or machine learning. This is “operations research”.
These seem like practical problems to me. So operations research has nothing to do with data science?
Actually, there is a decent amount of overlap. Operations research has given a lot of optimization algorithms that machine learning uses. It also provides a lot of solutions to common “AI” problems like the ones you mentioned.
So what algorithms do we use to solve these kinds of problems?
Well definitely not machine learning algorithms, and too few people know this. There are better algorithms that have been around for decades. Tree search, metaheuristics, linear programming, and other operations research methodologies have been used for a long time and do a much better job than machine learning algorithms for these categories of problems.
So why is everybody talking about machine learning and not these algorithms?
*Sigh* because those optimization problems have been satisfactorily solved for quite awhile, and the methods have not made headlines since. Believe it or not, the first AI hype cycles focused on these algorithms several decades ago. Nowadays, AI hype was re-ignited from machine learning and the types of problems it solves well: image recognition, natural language processing, image generation, etc.
So when people propose using machine learning to solve a scheduling problem, or something as simple as a Sudoku, they are wrong in doing so?
Pretty much, yes. Machine learning, deep learning, etc… whatever is being hyped up today usually does not solve discrete optimization problems, at least not well. People have tried, but with very sub-optimal results.
So if machine learning is just regression, why is everybody making such a fuss about robots and AI jeopardizing our jobs and society? I mean… is fitting a curve really that dangerous? How much self-awareness does an “AI” have when it is just doing a regression?
Well people have found some clever applications for regressions, like finding the best chess move on a given turn (which discrete optimization can also do) or a self-driving car calculating which direction to turn. But yes, there is quite a bit of hype, and regression can only have so many applications and on only one task.
I’m still reconciling this disconnect. I keep reading articles about DeepMind replicating human-like intelligence in chess games and now it is beating human players in StarCraft! These machine learning algorithms are beating human players in all these games! Does this mean they are going to replace me at my job next?
How many human StarCraft gamers are threatening to take your job?
(Confused silence)
Can you really say playing StarCraft is at all similar to doing your job?

If you are not threatened by a human StarCraft player, why should you be worried about a robot StarCraft player? They are hardcoded and trained to do that one task well: playing StarCraft. You can say the same about a person who has done nothing else with their time, and they are no more a threat to you.
I am not sure whether to be relieved or skeptical. First it’s chess, then it is StarCraft… maybe next it will be automated analytics and robots making strategic business decisions. But maybe the third item is a big leap from the first two. I don’t know anymore.
Some guy wrote an article on Towards Data Science about deep learning hitting its limitations. You might want to read it.
Alright, so how did we go from data science to artificial intelligence anyway? The more I try to define “data science” the more I just… I just… I can’t describe it. The whole thing is just so insane and vague.
Here, I got another article by the same author. Swell guy.
“Data Science” Has Become Too Vague
Thanks. I need to go for a walk and process all this. If I got anything from this, I think my Excel work qualifies as “data science”. I do not know if I want to have the title of “data scientist” though. It seems like it can be anything and everything. I may invest my time in something else. Hopefully the “next big thing” to follow data science will be less crazy.
Maybe you should follow IBM for awhile?
Why?
Ever hear of Quantum Computing?
How It Feels to Learn Data Science in 2019 was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.