Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
 Photo by rawpixel on Unsplash
Photo by rawpixel on Unsplash
Back in 2018 I was finishing my graduation in Computer Science, and for my graduation final project I decided to work with transparency in governments, specifically with the Chamber of Deputies open data.
Here in Brazil, our deputies have a monthly quota to perform their job. Let’s say that some deputy needs to buy a flight ticket or buy gas to the car in order to go to a meeting, he or she can use this monthly quota to do that. However, this money is public, therefore there are some rules to use it. One specific rule caught my attention, and it says that the deputies cannot use the money to buy a product or a service with companies that he or she is a partner, or a relative until third degree is a partner.
With that information in mind I wondered if it would be possible to discover whether a deputy was using this quota illegally. So that was the goal of my work, to discover possible fraud patterns inside the open data that the Chamber o Deputies provides regarding the deputies expenses. During the project I also tried to find if some deputy used the money with a given company that provided funds to his campaign back in 2014, the year that they were elected, which is not illegal but it is a good information for our society.
To perform all that I decided to use a graph oriented database. I chose OrientDB as the DBMS because of the query language derived from SQL. In the next sections I will explain the whole process to achieve those goals.
Open Data
The first thing that I had to do was obtain the data. First I downloaded the deputies expenses report from 2017 from this link: CEAP open data. There are a lot of file options to download, I worked with a CSV file to import the data in OrientDB. After obtaining the expenses report, I had to obtain the campaign donations to the deputies in 2014 elections, and you can find in this link: TSE open data. It’s also a CSV file with all the donations for each deputy campaign.
Data Model
Once I had the data files with me, I was able to analyse it and build a data model. A data model is used to provide a general vision of how the information will be organized inside the database, along with the data properties and relationships. The data model was built following the GRAPHED model, that proposes a way to model data for graph databases. The image below is the model that I built trying to evidence the possible fraud patterns mentioned.
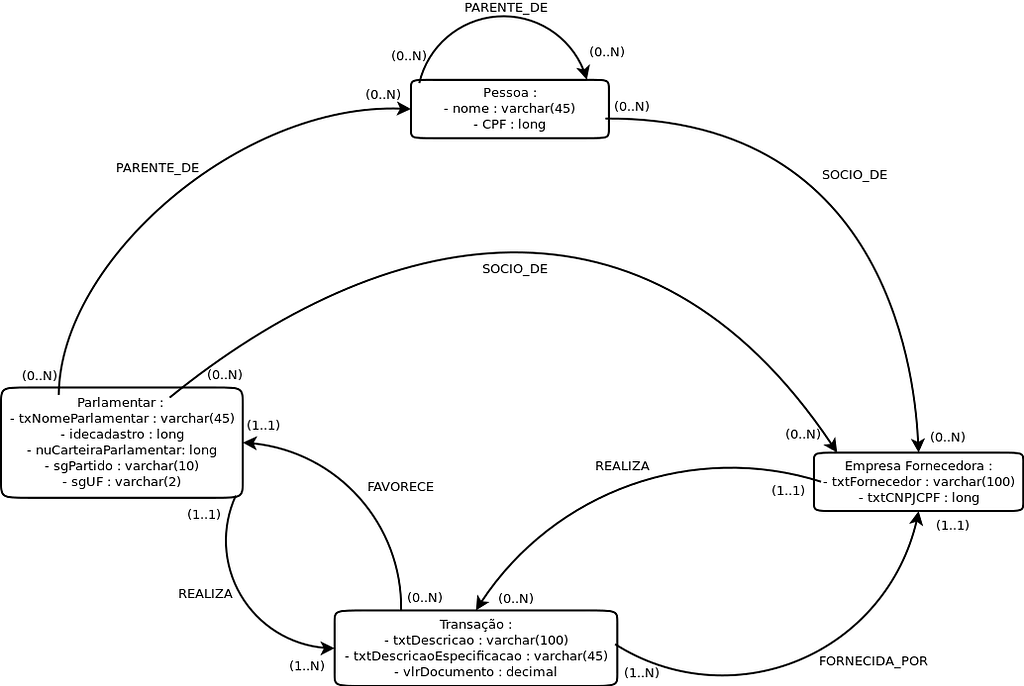
Unfortunately the model is in Portuguese, but we can see that the boxes will turn into vertices inside the database, and the arrows express how the boxes / vertices relate to each other. The left box named “Parlamentar” represents a deputy, and we can see that a deputy can perform multiples “Transação” or transactions, while transactions are usually provided by a “Empresa fornecedora” or supplying company. And at the same time I modeled in a way that a company can also perform transactions that are donated to a deputy. With that pattern we can discover if a deputy used the monthly quota money with companies that donated money to the deputy’s campaign.
Also we can see that a deputy can be a “Socio_de” or partner of a company, and that a deputy has relatives that can also be partners of a company. With that we can discover if a deputy used the money with companies that he or a relative is a partner.
ETL
Once the data model was built, it was time to write some code to import all that data to OrientDB. OrientDB is written in Java, and there is a good interface with Java language, therefore I wrote an ETL in Java that read the CSV files and saved the information in OrientDB with all it’s properties and relationships following the data model.
The code is open and can be found in github through this link: CEAP_ETL.
The only point worth noticing here is that I had to be constantly checking if some vertex were already persisted in the database, in order to avoid two vertices representing the same deputy. The same goes for the supplying companies.
The expenses report from 2017 had 209496 transactions and took 16 hours to finish the import process, in a Ubuntu 16–04 LTS, Intel Core i5–5200U CPU 2.20GHz * 4 and 6 Gb RAM machine. The donations file had to be filtered to use only federal deputies and the final version had 19302 donations and took 5 hours to finish being imported.
Discovering Patterns
With the database holding the data and structured according to the data model, I was able to use the OrientDB tools for my advantage and find some interesting results.
In OrientDB if you want to find some specific pattern inside your graph you can use the MATCH operator. Let’s see the query below:
MATCH{class: Parlamentar, as: p}−RealizaTransacao−>{class: Transacao ,as: t}−FornecidaPor−>{class: EmpresaFornecedora, as: e},{as: e}−RealizaTransacao−>{class: Transacao, as: t2}−FornecidaPara−> {as: p}RETURN $elementsThat query is pretty descriptive, we can see that it tries to find a pattern inside that graph that has a deputy “p” that executes a transaction “t” supplied by a company “e”. And the same company “e” executes a donation “t2” that is donated to the same deputy “p” declared in the beginning.
Pretty simple, right? The image below shows the result
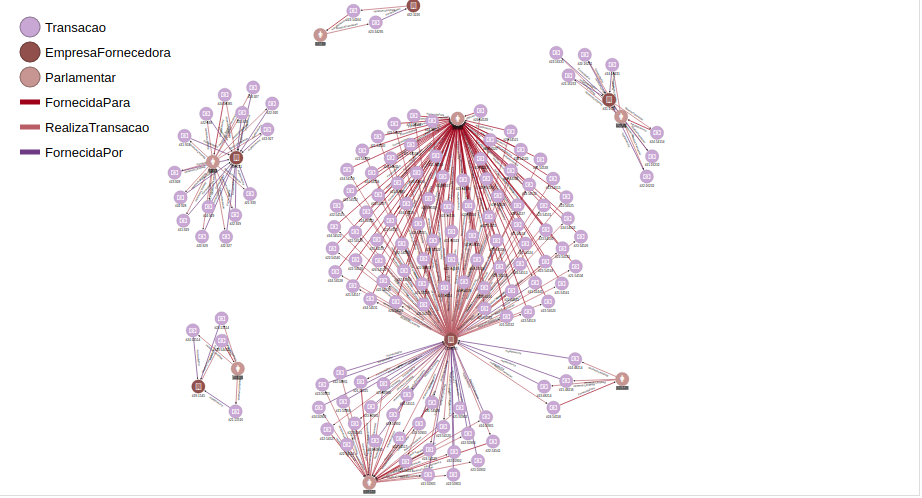
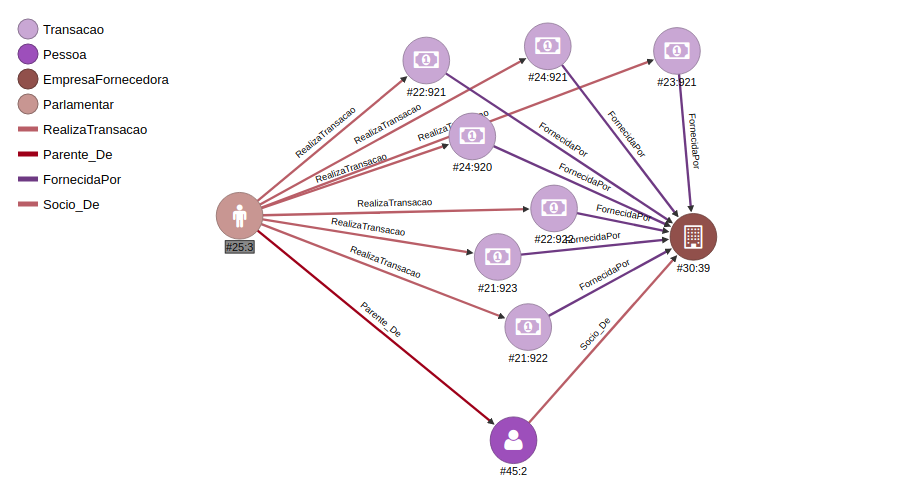
So the result shows us that seven deputies used the monthly quota money with companies that donated money to them in 2014. The light brown vertex represents a deputy, the dark brown vertex represents a company and the purple vertex represents transactions. The picture is hard to see the patterns because it is trying to show the whole result, the image below shows the pattern in more details:
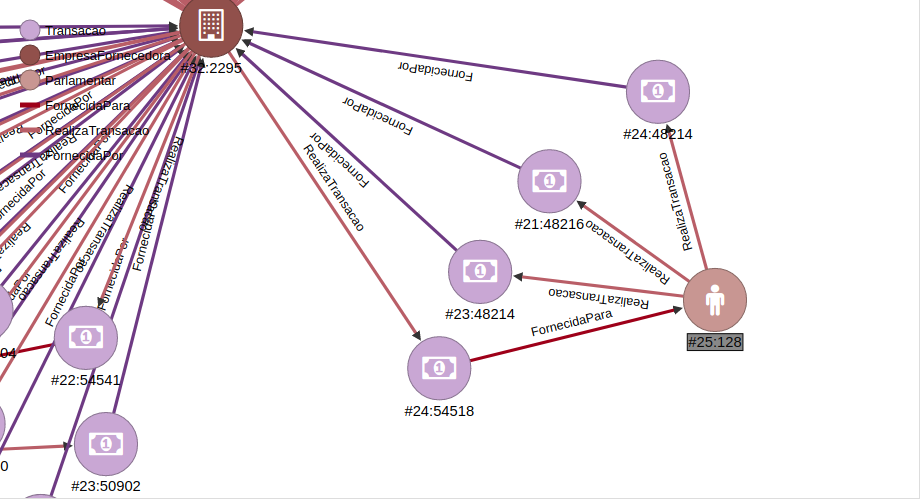
Here we can see that some deputy received one donation from a company and performed three transactions with the same company. Again it is not illegal to do that but it is important to know these kind of information.
But what about the fraud patterns? Unfortunately, the deputies relatives information is not public. One way out would be to built a web scraper and retrieve that information from Facebook, Twitter and other sites. But to validate the model and the whole process I inserted fake data to simulate the fraud scenarios, and hopefully if the Chamber of Deputies has this kind of data they could use the same process to inspect the deputies expenses.
The query below was built to find a possible fraud pattern in the graph using the fake data that I’ve mentioned.
MATCH{class: Parlamentar, as: p}−RealizaTransacao−>{class: Transacao, as: t}−FornecidaPor−>{class: EmpresaFornecedora, as: e},{as: p}−Socio_De−> {as: e}RETURN $elementsHere we can see that the pattern looks for a deputy “p” that executes a transaction “t” supplied by a company “e”, and the same deputy “p” is a partner of the same company “e” defined before. This is a fraud pattern inside the graph, the image below shows the result.
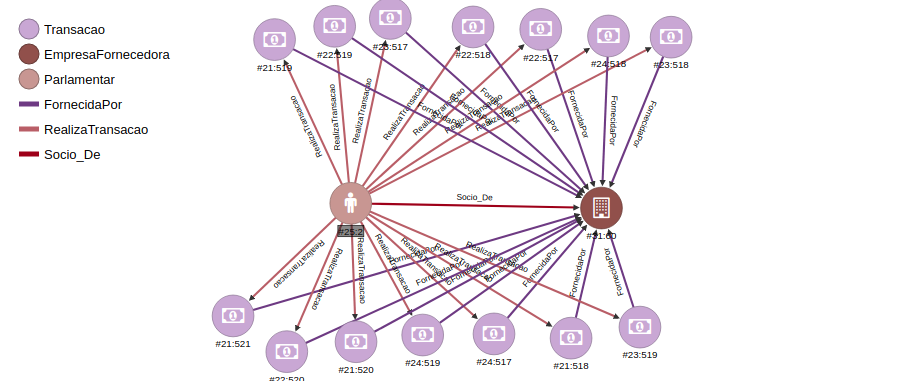
In the image we can see that the deputy in light brown vertex is associated to a company in a dark brown vertex, at the same time the deputy executed several transactions supplied by the same company. As I said before if the Chamber of Deputies has information regarding the companies that the deputy is a partner, they can approach this problem using graphs instead of relational structures.
Finally, the query below shows the last pattern that tries to find if the deputy relative is a partner of a company that he or she used money to buy a product or a service.
MATCH{class: Parlamentar, as: p}−RealizaTransacao−> {class: Transacao ,as: t}−FornecidaPor−> {class: EmpresaFornecedora, as: e},{as: p} −Parente_De−>{class: Pessoa, as: p2}−Socio_De−>{as: e}RETURN $elementsThe query follows the same approach as the other ones, the difference is that now the deputy “p” is a relative of a person “p2” and the person is a partner of the previously defined company. The result is shown below (Also using fake data).
Transparency
After all that process the project goal was achieved, but all that discoveries along with others that I will show next, had to be published so everyone could see whether our deputies are using the money correctly or not.
For that I’ve built a web system in Ruby on Rails that uses HTTP to communicate with OrientDB, retrieve the result from the queries above and display a graph in the system. The system also displays other information regarding the expenses report from 2017. The query below displays the parties that most used the monthly quota in 2017.
select SgPartido, count (SgPartido) from Parlamentar GROUP BY SgPartido
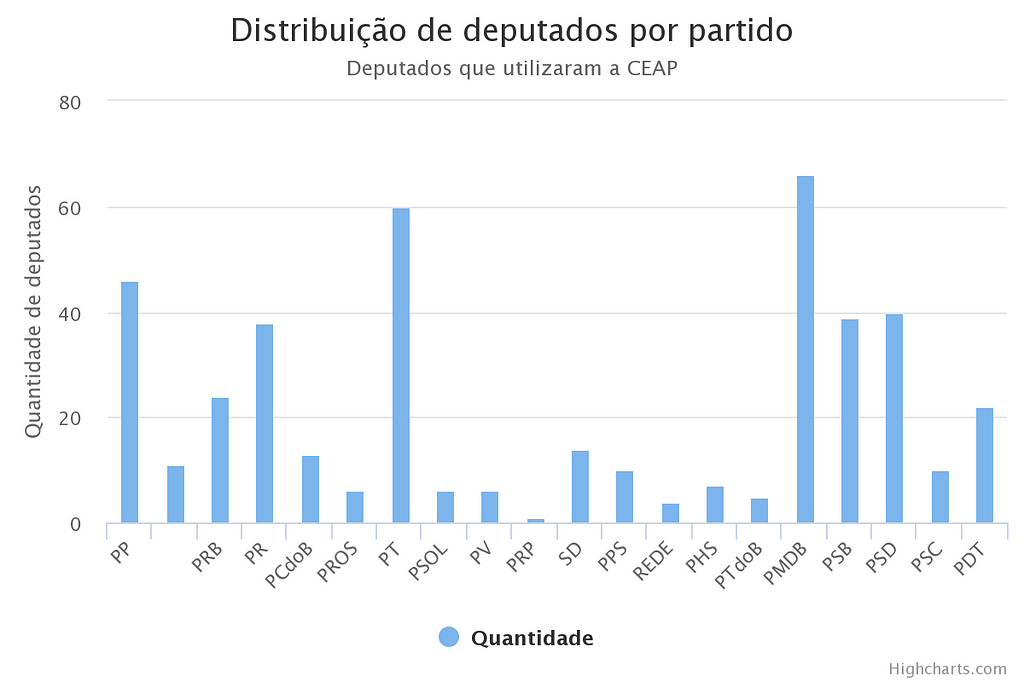
The chart above was displayed in the screen after the system sent a HTTP request for OrientDB and retrieved the result as JSON. The JSON was passed to a Javascript chart library known as Highchart.js. With that we are able to see that PMDB was the party that most used the money in 2017. Here we can see the similarity with the SQL language, which makes real easy to adapt to this NoSQL DBMS.
Other interesting information is what they spend the money with. The query below finds that.
select TxtFornecedor, in ("FornecidaPor").size() as servicosfrom EmpresaFornecedoraorder by servicos desc limit 15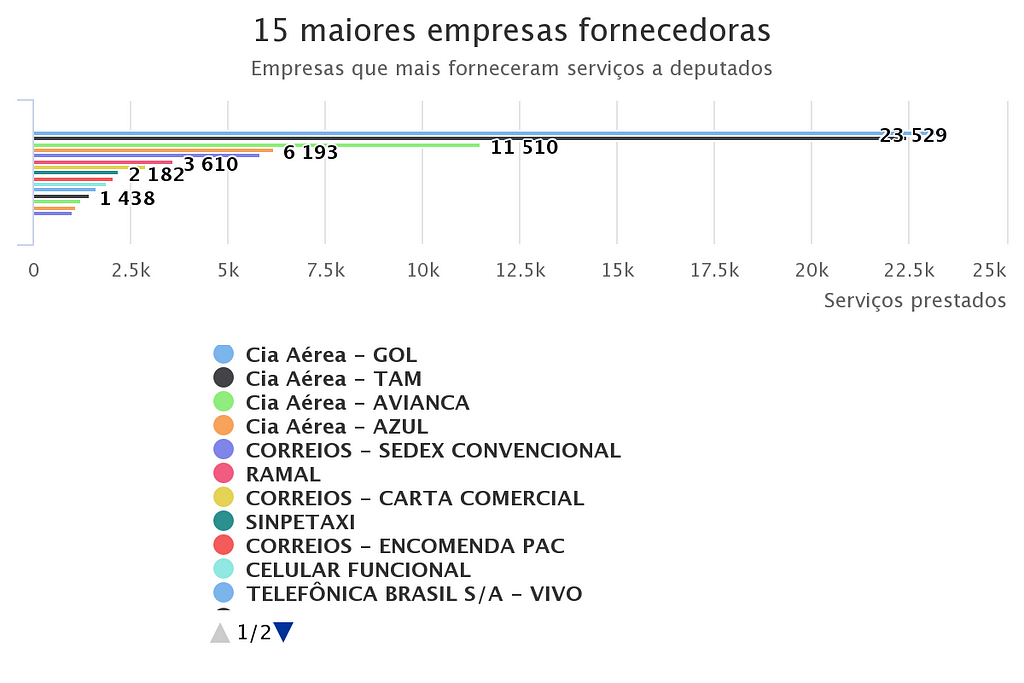
With that we can see that the companies that most supply services are traveling ones. It makes sense since the majority of the deputies comes from other states, and they need to travel for business for example. Again we see the similarity with SQL language, however, OrientDB allow us to get how much edges of type “FornecidaPor”, which means supplied by, enters in the vertex of a company. For exemple 23529 edges of type “FornecidaPor” enters in the “Cia Aérea - GOL” vertex. So the query is basically returning the name of the company and how much edges of the type “FornecidaPor” enter in the vertex, ordered by the size of edges mentioned.
Conclusion
After the project was done I was able to draw some conclusions to the whole process
- Each problem has an ideal way to be solved. Graph databases are great to work with data that are closely related, and has complex relationships. Take for example the case where we need to look for the deputies relatives until the third degree, these kind of relationship is better modeled in graph structures instead of a table structure.
- OrientDB is a great multi-model DBMS. I forgot to mention but it also works with key-value pairs and documents. You can create classes for your vertices and edges and organize your data with these classes, which is really helpful when writing your queries. You can build hierarchy relationships and improve even more your queries.
- Finally, the last conclusion that I had is that graphs are great to expose relationships and it is a viable solution to find patterns with open data, and to provide transparency for our population.
Hope you liked it, feel free to share your thoughts in the comments :)
Discovering Patterns in Brazilian Open Data using OrientDB was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.