Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Best practice from the Alibaba tech team to build flexible and scalable applications in the Cloud Age
The cloud native era of application development has arrived, and with it a growing range of opportunities and challengers for developers. Designed to enable loosely coupled, resilient, manageable, and observable systems, cloud native technologies are fundamentally changing the way applications can be built and run for improved scalability in new, cloud-based environments.
Drawing on insights from an Alibaba developer, this article looks at the key practices cloud native developers should observe as they write these highly-autonomous applications, from ensuring elastic scalability and fault tolerance to enhancing ease of management and observation.
Giving Shape to Cloud Native Applications
The first step in cloud native development is to give applications their required shapes. Traditional applications are often akin to snowballs that continue to accumulate functions, meanwhile becoming increasingly cumbersome and difficult to modify while falling out of step with the businesses they support as they evolve. By contrast, one of the primary goals of cloud native development is to enable rapid iteration, trial and error, and business innovation. To this end, developers must start by defining their applications’ structures with the architectural concepts present in microservices.
Application decomposition
Ensuring the agility of an entire application system requires decomposing the application into multiple self-contained parts that can be independently implemented, pushed through evolution, and scaled — i.e., microservices.
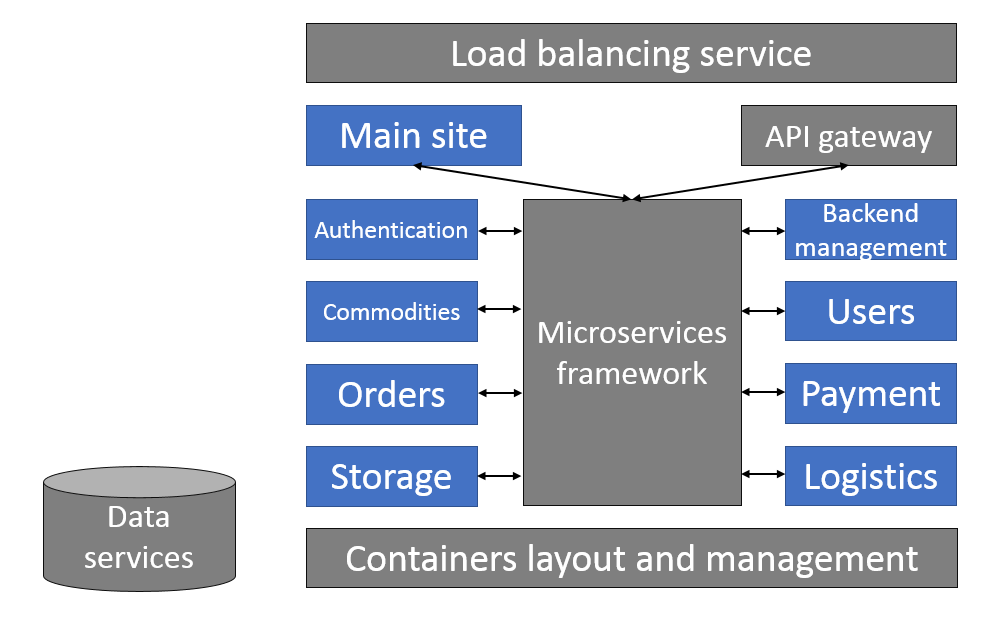
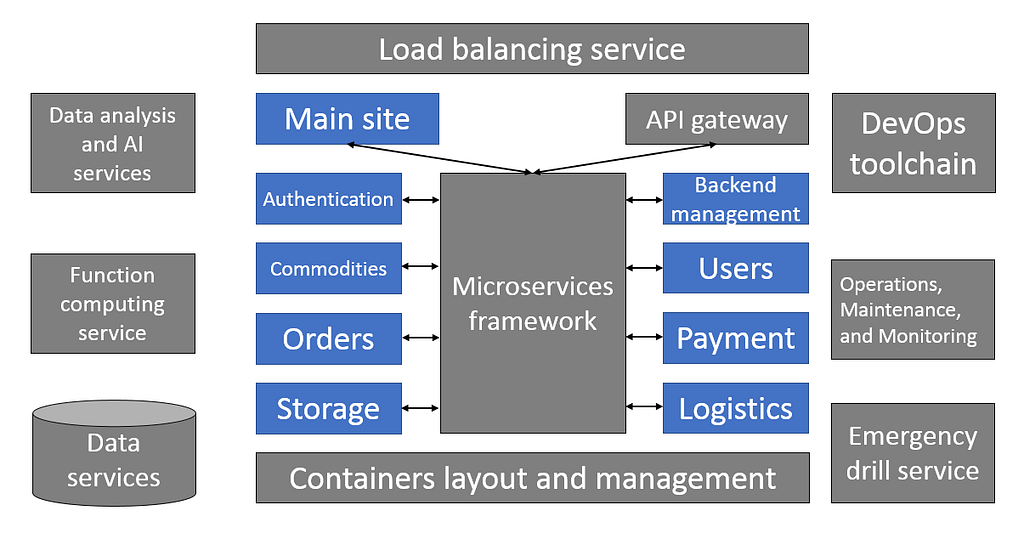
Making divisions among microservices is somewhat of an art, in which the general principle is to divide them according to their business domains. This can be done at a fine or coarse level of granularity. A general approach is to identify the primary business components that can be individually implemented by a microservice, as shown in the following example from an online store divided into components like commodities, users, payment, and inventory:
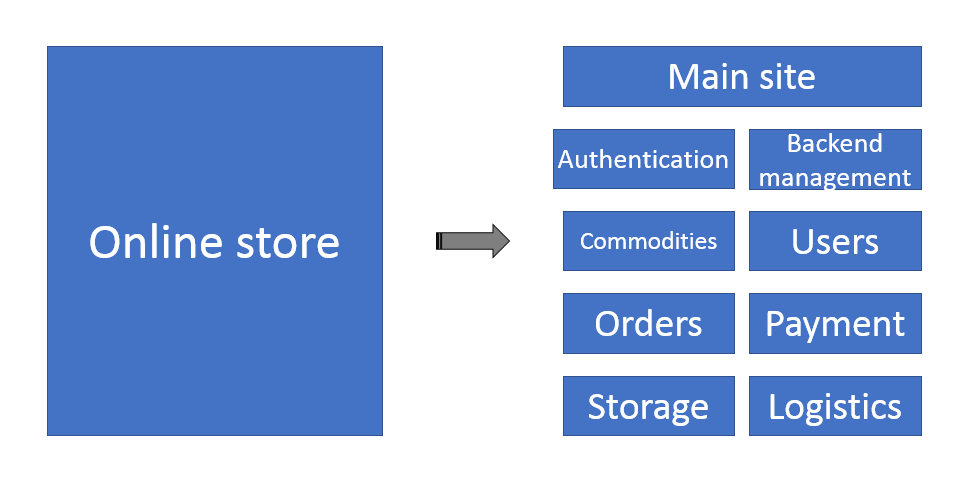 Application development
Application development
Having determined the appropriate divisions, the next logical step is to define and implement each microservice.
The most important part of defining a microservice is defining its API, which can be an HTTP protocol API, a REST-style API, or an RPC-based API. The advantages of the HTTP approach are that the HTTP protocol is widely accepted (with mature and complete standards, support for all programming languages, and sound programming frameworks and ecosystem) and that it is ubiquitous in the network infrastructure with a full package of supporting features such as load balancing, firewall, and cache optimization. In terms of disadvantages, the HTTP approach has a higher level of encapsulation that leads to increased overhead and lower performance. While RPC approaches like the Thrift and Dubbo protocols have better performance and latency, they are not as widely accepted despite being able to achieve cross-language operations. As a compromise between the above approaches, gRPC is based on HTTP 2.0.
In the past, choosing a particular protocol had a strong influence on the subsequent choice of which microservice invocation framework to use. For example, using the HTTP approach, it would make sense to use the Netflix open-source components as an invocation framework for microservices, including Eureka, Ribbon, Zuul, and so on. Spring made a good choice for Java developers, given its good integration of these Netflix components and its being fused into its Spring Boot system. Using the RPC approach, Dubbo’s complete operation and management system would make a good option, and its support for multiple languages has been gradually improving through previous years.
Today, the emergence of Service Mesh technology makes the data plane and management plane for microservices clearly decoupled, allowing multi-protocol support and various management capabilities to be plugged in more easily. More importantly, the sidecar approach enables applications to run independently from the microservices management system, greatly reducing its intrusiveness on applications. Istio is a popular service mesh implementation, supporting protocols like HTTP, gRPC, and TCP. The Dubbo protocol support is also being added.
The microservice API is mainly intended for internal interactions — i.e., interactions between individual microservices. As a native cloud application, it also needs an external public API in order to communicate flexibly with other applications on the cloud and various end devices. APIs at this layer are usually managed and exposed through an API gateway, which talks to the API of backend microservices. The API gateway can support simple orchestration and enable access control, traffic control, metering, and analytics.
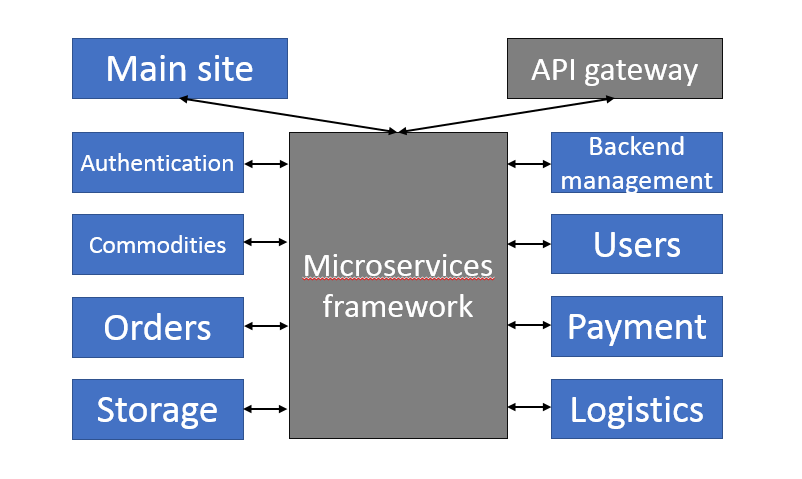 Application deployment and management
Application deployment and management
The third step involves the application’s deployment and management. Containers are undoubtedly the ideal packaging and deployment vehicle for cloud native applications, with their greatest advantage being portability. This not only makes the development and deployment environments more consistent, but also allows applications to more easily migrate between private and public clouds of different vendors.
Each microservice can be packaged into one or more containers for deployment. Although it is possible to use an atomic tool such as Docker for deployment, deploying and managing these containers using a container orchestration tool such as Kubernetes saves a great deal of trouble, due to the tendency for cloud native applications to have a large number of containers. Meanwhile, Kubernetes also supports configuration externalization through Secrets and ConfigMaps, which is one of cloud native’s best practices for following the principles of immutable applications.
Mainstream cloud vendors provide Serverless Kubernetes service, with which users do not need to manage the underlying computing nodes required in the run of containers, but can rather describe the application according to the Kubernetes specification and then deploy it in one command or click; further, resources are provisioned on demand, which also boosts the experience of cloud native development.
Cloud Foundry takes a more radical approach, and is aimed to give developers a pure application-centric experience. As long as code is pushed, Cloud Foundry calls the corresponding buildback to package the application, finally deploying it in the form of a container. This method is better suited to applications that have simple topology and inter-dependencies, and especially web applications.
Everything comes at some cost, and while Cloud Foundry offers developers greater convenience it also limits their control over applications’ environments and the underlying management. OpenShift attempts to introduce a similar deployment experience for the Kubernetes system while retaining developers’ control over the Kubernetes layer, but its broader ecosystem remains relatively monotonous at present.
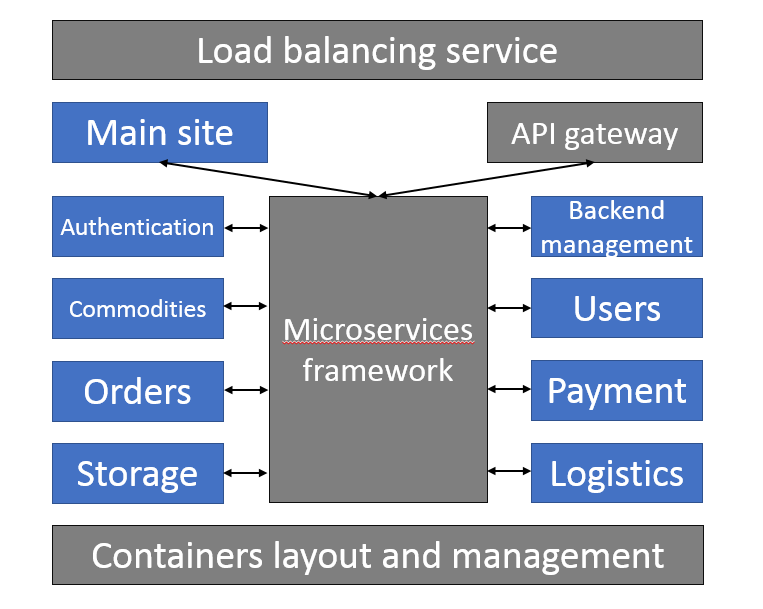
Putting Soul into Cloud Native Applications
With its shape established, the next step for developers is to give a cloud native application its “soul”, or unique character. This requires a series of involved processes ranging in emphasis from scalability to support for frequent changes.
Elastic scalability
Giving applications the quality of scalability requires a series of three steps, beginning with ensuring the scale-out capability of the application logic itself; this forms a key foundation in that the application logic of each microservice can thus achieve more powerful processing capabilities by spinning up more instances. An important practice is to externalize application data and state, which can be supported by a range of off-the-shelf cloud services on the public cloud, such as by putting data into RDS or NoSQL services and putting state into Redis services. With this foundation, it becomes possible to further implement auto-scaling, which is to say that the application can automatically scale in or out according to the load. Kubernetes offers auto-scaling capability, thus enabling each of the application’s microservices to scale independently.
The second step is to ensure application management ability, such that the load balancing rules of the front-end access layer and the invocation routing among microservices can be updated in real time to reflect the coming and going of each microservice instance. This is generally realized by virtue of the load balancing service and microservice invocation frameworks provided by cloud vendors.
The third step is to ensure the scalability of the cloud services that the application depends on. Cloud services need to be able to match changes in the scales of applications. For stateless applications, the data layer often becomes the bottlenecks, so having a scalable data service is critical. If cloud services cannot provide transparent scalability, scalability of the application is out of the question. Cloud native databases like AWS’s Aurora and Alibaba Cloud’s POLARDB offer high scalability and make the best choice for future-proofing applications.
It is also important, however, to choose an appropriate transaction model according to the characteristics of the business that the application supports. Traditionally, developers have become accustomed to storing all data in a relational database and using the ACID transaction model, which is simple for the purposes of programming but sacrifices performance and scalability. In cloud native applications, NoSQL database and BASE transaction strategy offer another option. They can be used to manage non-transactional data like user reviews, tags, and so on in order to improve performance and scalability.
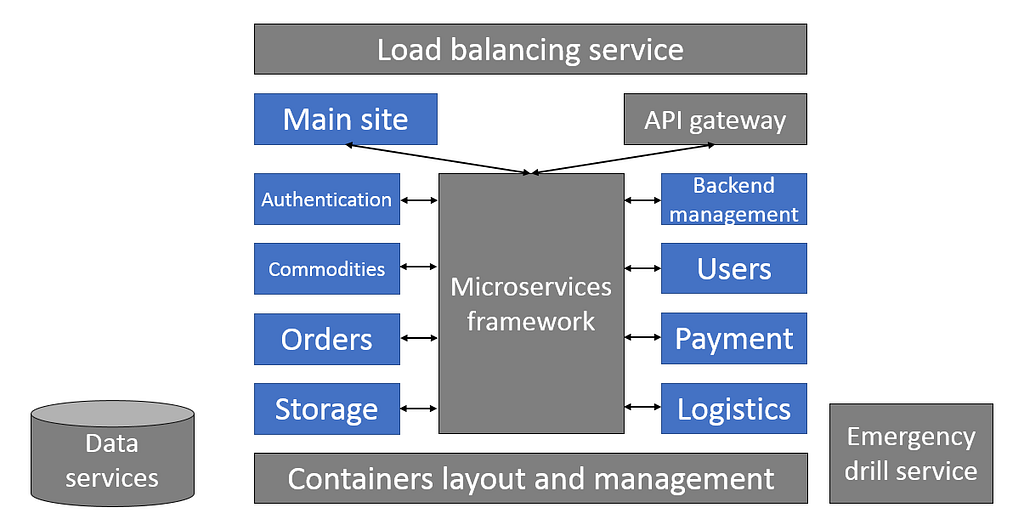
 Fault tolerance
Fault tolerance
As with elastic scalability, giving applications the quality of fault tolerance involves work on multiple levels.
The first concerns multi-AZ, or even multi-region disaster recovery deployment and backup, which from a macro perspective has long been a best practice for cloud native applications. With this it is possible to ensure that when a certain AZ or even an entire region suffers a system failure the application will still be able to continue providing services.
The next step is to ensure fault tolerance and service downgrading capabilities needed in the event of a microservice or external dependency of an application failing. Netflix has gained notable experience in this area, and its open source Hystrix has achieved strong circuit-breaking and downgrading capabilities.
The third step must address the inevitable failure of some microservice instances, which means their work must be replaced by other instances. Statelessness offers an important means of ensuring this, but the load balancing service and microservice invocation framework need to be able to update the route immediately. Management platforms such as Kubernetes can create new instances to replace failed ones.
As one saying goes, the best way to avoid failures is to fail often. The “chaos engineering” that Netflix advocates has the valuable impact of challenging a team’s creativity to deal with issues as they emerge. To this end, failing proactively can help teams discover weak points in their systems and verify fault tolerance, thus strengthening applications.
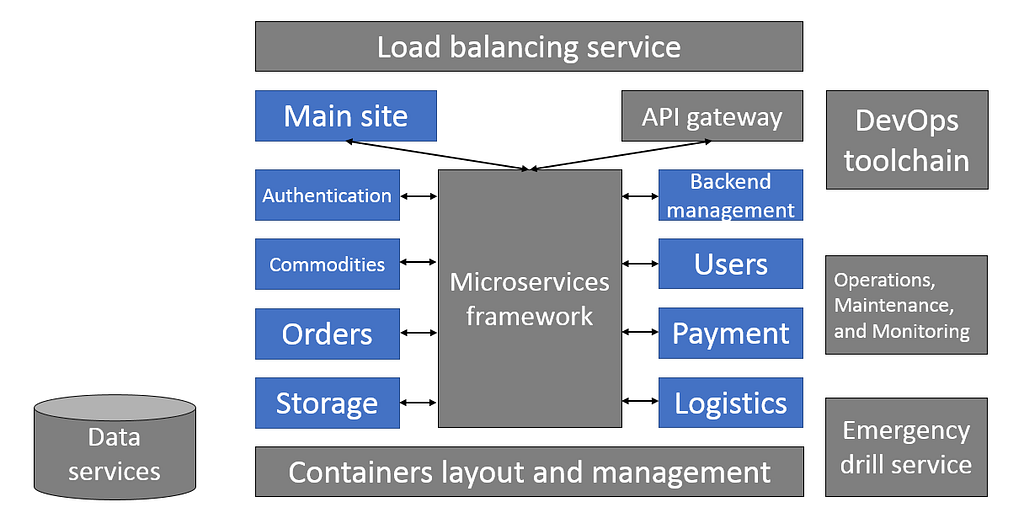
 Ease of management and observation
Ease of management and observation
Giving applications the quality of openness to observation and management requires using the proper tools and platforms. Kubernetes, Dubbo, and Istio, for example, provide numerous convenient management capabilities, with the latter two being able to display multiple indicators for the health of microservices. AIOps has recently become a popular trend. But before we talk about intelligence, visibility into the state of applications and automation (automatically performing specific operations according to the state) are the basis for management; only when these two have been done to a sufficient extent and when enough data has been gathered can an intelligent understanding of data be formed.
Support for frequent changes
Automated continuous build and delivery capabilities like multi-environment testing and Canary Release are indispensable to achieving receptiveness to changes in an application. Mainstream cloud vendors offer off-the-shelf DevOps toolchains, which are highly beneficial to this end. For a cloud native application, it is best to start using such tools for build and release from day one.
The Cloud Native Future
The key trends that will define the future of cloud native development have in fact already arrived: serverless development, and AI. In common, both offer developers a way of diverting human attention from relatively burdensome aspects of development, enabling developers to focus on big-picture questions.
Serverless development
The serverless paradigm allows for an increasingly high level of abstraction in application development, leaving developers with fewer and fewer things to worry about over time. Serverless container service enables developers not to worry about the resources needed to run containers, while serverless function service allows developers to focus exclusively on fragmented code.
In some ways, serverlessness is the purest form of PaaS, and function computing is the epitome of this. The power of function computing is not only its cost-light model but also its ability to weave many services into an event-driven system and to divide application logic to an extremely fine level of granularity. This introduces an unparalleled level of flexibility into the evolution of applications.
Naturally, such a degree of fragmentation also poses challenges for application management, while developers today are still in the midst of struggling with the complexities of application management and operation and maintenance that microservices have introduced. At present, function computing can be used to implement small applications, or as a complement to large-scale application development. In the future, when cloud services are increasingly accessing the event system, function computing may take more of a protagonist’s role, particularly since many developers have adapted to purely event-driven programming models such as Node.js.
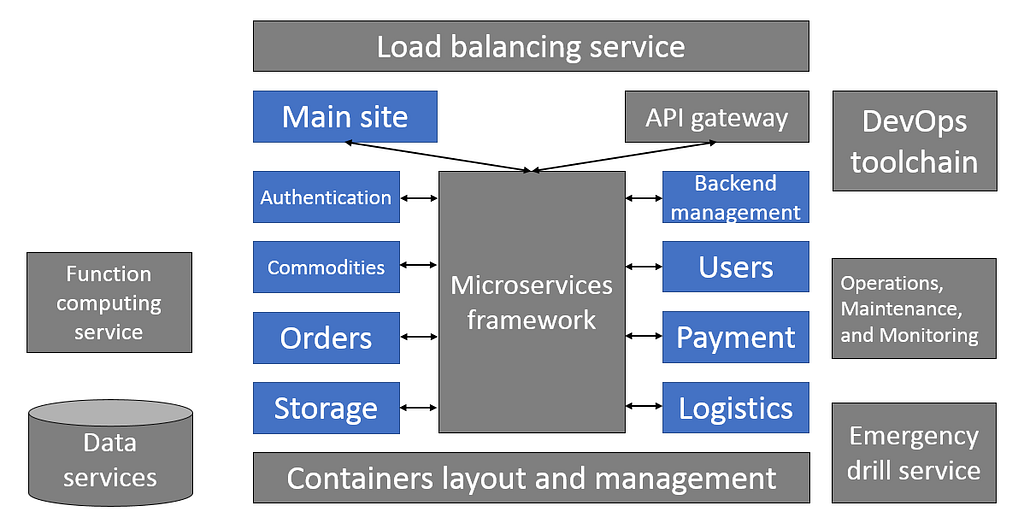 AI
AI
While few are likely to doubt the importance of AI in future applications, the question remains of what developers need to do with their applications to make them AI-ready. The first step in answering this unknown is to identify the scenarios where AI can bring value to services. This now challenges developers to think in terms of what they would hope to do if various impossibilities were all at once made magically possible, or what they would do if they could read their clients’ minds. For instance, AI’s predictive powers raise the question of how one might develop and optimize applications knowing that they would be able to see a day or more into the future. The next problem then becomes seeking out data that would prove decisive in such applications, followed by the actual models and algorithms.
In light of the above, application development should focus on maximizing data collection. What today may not have a meaning could prove valuable beyond measure in future scenarios, meaning that developers should seek ways to record as much as possible of user actions and business events in their applications.
Completing the Picture: Key Takeaways
As cloud native application platforms on the public cloud advance, a growing number of powerful native cloud concepts, best practices, and technical mechanisms like containers, microservices, service mesh, and APIs have emerged. Meanwhile, function computing, data analytics, and AI services continue to mature. Through these changes, the essence of applications remains their data models and processing logic for services, which as always depend on the insight and intelligence of human developers. As such, cloud native development is an advancing approach that can effectively hone developers’ work in a time with great intricacy, exploding information, unpredictable changes, but also endless possibilities.
(Original article by Cai Junjie蔡俊杰)
Alibaba Tech
First hand and in-depth information about Alibaba’s latest technology → Facebook: “Alibaba Tech”. Twitter: “AlibabaTech”.
Writing Sky-high Applications: A Guide to Cloud Native Development was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.