Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Learn how to implement a sequence-to-sequence model in this article by Matthew Lamons, founder, and CEO of Skejul — the AI platform to help people manage their activities, and Rahul Kumar, an AI scientist, deep learning practitioner, and independent researcher.
In this article, you’ll implement a seq2seq model (an encoder-decoder RNN) for a simple sequence-to-sequence question-answer task. This model can be trained to map an input sequence (questions) to an output sequence (answers), which are not necessarily of the same length as each other.
This type of seq2seq model has shown impressive performance in various other tasks such as speech recognition, machine translation, question answering, Neural Machine Translation (NMT), and image caption generation.
The following diagram helps you visualize the seq2seq model:
 The illustration of the sequence to sequence (seq2seq) model
The illustration of the sequence to sequence (seq2seq) model
Each rectangle box is the RNN cell in which blue ones are the encoders and Red been the Decoders. In the encoder-decoder structure, one RNN (blue) encodes the input sequence. The encoder emits the context C, usually as a simple function of its final hidden state, and the second RNN (red) decoder calculates the target values and generates the output sequence. One essential step is to let the encoder and decoder communicate. In the simplest approach, you use the last hidden state of the encoder to initialize the decoder. Other approaches let the decoder attend to different parts of the encoded input at different time steps in the decoding process.
So, get started with data preparation, model building, training, tuning, and evaluating your seq2seq model, and see how it performs. The model file can be found at https://github.com/PacktPublishing/Python-Deep-Learning-Projects/blob/master/Chapter05/3.%20rnn_lstm_seq2seq.py.
Data preparation
Here, you build your question-answering system. For the project, you need a dataset with question and answer pairs, as shown in the following screenshot. Both of the columns contain sequences of words, which is what you need to feed into your seq2seq model. Also, note that your sentences can be of dynamic length:
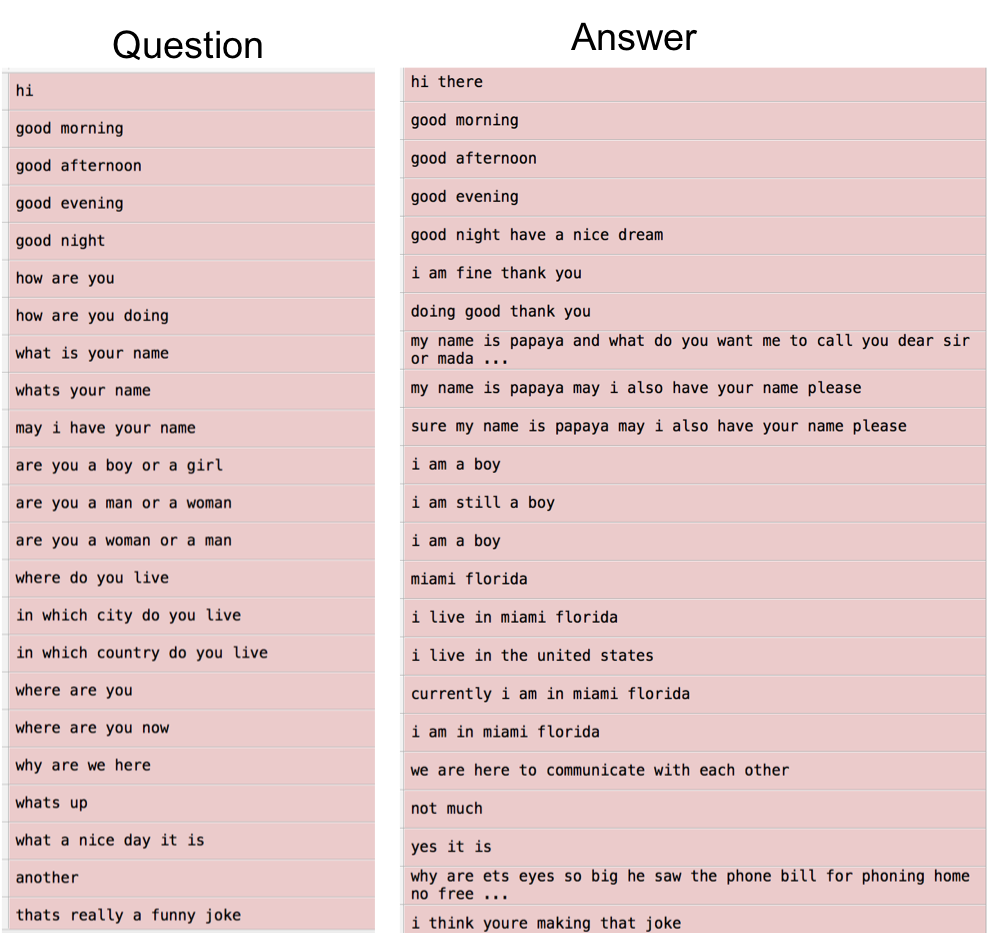 The dataset prepared with a set of questions and answers
The dataset prepared with a set of questions and answers
Now, load them and perform data processing using build_dataset(). In the end, you will have a dictionary with words as keys, where the associated values are the counts of the word in the respective corpus. Also, you have four extras values:
import numpy as np
import tensorflow as tf
import collections
from utils import *
file_path = './conversation_data/'
with open(file_path+'from.txt', 'r') as fopen:
text_from = fopen.read().lower().split('\n')with open(file_path+'to.txt', 'r') as fopen:
text_to = fopen.read().lower().split('\n')print('len from: %d, len to: %d'%(len(text_from), len(text_to)))concat_from = ' '.join(text_from).split()
vocabulary_size_from = len(list(set(concat_from)))
data_from, count_from, dictionary_from, rev_dictionary_from = build_dataset(concat_from, vocabulary_size_from)
concat_to = ' '.join(text_to).split()
vocabulary_size_to = len(list(set(concat_to)))
data_to, count_to, dictionary_to, rev_dictionary_to = build_dataset(concat_to, vocabulary_size_to)
GO = dictionary_from['GO']
PAD = dictionary_from['PAD']
EOS = dictionary_from['EOS']
UNK = dictionary_from['UNK']
Defining a seq2seq model
In this section, you will outline the TensorFlow seq2seq model definition. You’ll employ an embedding layer to go from integer representation to the vector representation of the input. This seq2seq model has four major components: the embedding layer, encoders, decoders, and cost/optimizers.
You can see the model in graphical form in the following diagram:
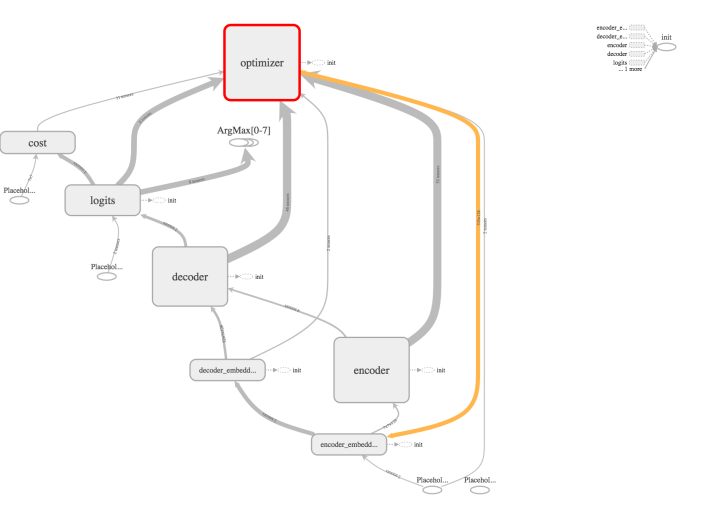 The TensorBoard visualization of the seq2seq model
The TensorBoard visualization of the seq2seq model
This graph shows the connection between the encoder and the decoder with other relevant components like the optimizer. The following is a formal outline of the TensorFlow seq2seq model definition:
class Chatbot:
def __init__(self, size_layer, num_layers, embedded_size,
from_dict_size, to_dict_size, learning_rate, batch_size):
def cells(reuse=False):
return tf.nn.rnn_cell.LSTMCell(size_layer,initializer=tf.orthogonal_initializer(),reuse=reuse)
self.X = tf.placeholder(tf.int32, [None, None])
self.Y = tf.placeholder(tf.int32, [None, None])
self.X_seq_len = tf.placeholder(tf.int32, [None])
self.Y_seq_len = tf.placeholder(tf.int32, [None])
with tf.variable_scope("encoder_embeddings"):encoder_embeddings = tf.Variable(tf.random_uniform([from_dict_size, embedded_size], -1, 1))
encoder_embedded = tf.nn.embedding_lookup(encoder_embeddings, self.X)
main = tf.strided_slice(self.X, [0, 0], [batch_size, -1], [1, 1])
with tf.variable_scope("decoder_embeddings"):decoder_input = tf.concat([tf.fill([batch_size, 1], GO), main], 1)
decoder_embeddings = tf.Variable(tf.random_uniform([to_dict_size, embedded_size], -1, 1))
decoder_embedded = tf.nn.embedding_lookup(encoder_embeddings, decoder_input)
with tf.variable_scope("encoder"):rnn_cells = tf.nn.rnn_cell.MultiRNNCell([cells() for _ in range(num_layers)])
_, last_state = tf.nn.dynamic_rnn(rnn_cells, encoder_embedded,
dtype = tf.float32)
with tf.variable_scope("decoder"):rnn_cells_dec = tf.nn.rnn_cell.MultiRNNCell([cells() for _ in range(num_layers)])
outputs, _ = tf.nn.dynamic_rnn(rnn_cells_dec, decoder_embedded,
initial_state = last_state,
dtype = tf.float32)
with tf.variable_scope("logits"):self.logits = tf.layers.dense(outputs,to_dict_size)
print(self.logits)
masks = tf.sequence_mask(self.Y_seq_len, tf.reduce_max(self.Y_seq_len), dtype=tf.float32)
with tf.variable_scope("cost"):self.cost = tf.contrib.seq2seq.sequence_loss(logits = self.logits,
targets = self.Y,
weights = masks)
with tf.variable_scope("optimizer"):self.optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(self.cost)
Hyperparameters
Now that you have your model definition ready, define the hyperparameters. Keep most of the configurations the same as in the previous one:
size_layer = 128
num_layers = 2
embedded_size = 128
learning_rate = 0.001
batch_size = 32
epoch = 50
Training the seq2seq model
Now, train the model. You will need some helper functions for the padding of the sentence and to calculate the accuracy of the model:
def pad_sentence_batch(sentence_batch, pad_int):
padded_seqs = []
seq_lens = []
max_sentence_len = 50
for sentence in sentence_batch:
padded_seqs.append(sentence + [pad_int] * (max_sentence_len - len(sentence)))
seq_lens.append(50)
return padded_seqs, seq_lens
def check_accuracy(logits, Y):
acc = 0
for i in range(logits.shape[0]):
internal_acc = 0
for k in range(len(Y[i])):
if Y[i][k] == logits[i][k]:
internal_acc += 1
acc += (internal_acc / len(Y[i]))
return acc / logits.shape[0]
Now, initialize your model and iterate the session for the defined number of epochs:
tf.reset_default_graph()
sess = tf.InteractiveSession()
model = Chatbot(size_layer, num_layers, embedded_size, vocabulary_size_from + 4,
vocabulary_size_to + 4, learning_rate, batch_size)
sess.run(tf.global_variables_initializer())
for i in range(epoch):
total_loss, total_accuracy = 0, 0
for k in range(0, (len(text_from) // batch_size) * batch_size, batch_size):
batch_x, seq_x = pad_sentence_batch(X[k: k+batch_size], PAD)
batch_y, seq_y = pad_sentence_batch(Y[k: k+batch_size], PAD)
predicted, loss, _ = sess.run([tf.argmax(model.logits,2), model.cost, model.optimizer],
feed_dict={model.X:batch_x,model.Y:batch_y,
model.X_seq_len:seq_x,
model.Y_seq_len:seq_y})
total_loss += loss
total_accuracy += check_accuracy(predicted,batch_y)
total_loss /= (len(text_from) // batch_size)
total_accuracy /= (len(text_from) // batch_size)
print('epoch: %d, avg loss: %f, avg accuracy: %f'%(i+1, total_loss, total_accuracy))OUTPUT:
epoch: 47, avg loss: 0.682934, avg accuracy: 0.000000
epoch: 48, avg loss: 0.680367, avg accuracy: 0.000000
epoch: 49, avg loss: 0.677882, avg accuracy: 0.000000
epoch: 50, avg loss: 0.678484, avg accuracy: 0.000000
.
.
.
epoch: 1133, avg loss: 0.000464, avg accuracy: 1.000000
epoch: 1134, avg loss: 0.000462, avg accuracy: 1.000000
epoch: 1135, avg loss: 0.000460, avg accuracy: 1.000000
epoch: 1136, avg loss: 0.000457, avg accuracy: 1.000000
Evaluation of the seq2seq model
So, after running the training process for few hours on a GPU, you can see that the accuracy has reached a value of 1.0, and loss has significantly reduced to 0.00045. Now, see how the model performs when you ask some generic questions.
To make predictions, create a predict() function that will take the raw text of any size as input and return the response to the question that you asked. You did a quick fix to handle the Out Of Vocab (OOV) words by replacing them with the PAD:
def predict(sentence):
X_in = []
for word in sentence.split():
try:
X_in.append(dictionary_from[word])
except:
X_in.append(PAD)
pass
test, seq_x = pad_sentence_batch([X_in], PAD)
input_batch = np.zeros([batch_size,seq_x[0]])
input_batch[0] =test[0]
log = sess.run(tf.argmax(model.logits,2),
feed_dict={model.X:input_batch,
model.X_seq_len:seq_x,
model.Y_seq_len:seq_x
}
)
result=' '.join(rev_dictionary_to[i] for i in log[0])
return result
When the model was trained for the first 50 epochs, you’ll have the following result:
>> predict('where do you live')>> i PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD
>> print predict('how are you ?')>> i am PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD
When the model was trained for 1,136 epochs:
>> predict('where do you live')>> miami florida PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD
>> print predict('how are you ?')>> i am fine thank you PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD PAD
Well! That’s impressive, right? Now your model is not just able to understand the context, but can also generate answers word by word.
If you found this article interesting, you can explore Python Deep Learning Projects to master deep learning and neural network architectures using Python and Keras. Python Deep Learning Projects imparts all the knowledge needed to implement complex deep learning projects in the field of computational linguistics and computer vision.
Implementing a Sequence-to-Sequence Model was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.