Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
A senior Alibaba technical expert introduces the algorithms that overcome limits proposed in the CAP theorem
In distributed systems, availability and consistency are the most basic prevailing issues, for which reason their relationship has been the subject of extensive study. The well-known CAP theorem defines their relationship as mutually exclusive in large-scale distributed environments, where the third factor in such systems, partition tolerance, cannot be treated as a variable. In an attempt to circumvent these issues, the Turing-award winning Paxos Protocol has since been proposed to maximize the efficiency of availability and consistency in such systems. To further address issues prevalent in this the Paxos algorithm, the ZAB Protocol was subsequently developed from an original algorithm, going well beyond basic optimization to improve on its predecessor.
Drawing on insights from senior Alibaba technical expert Jiandu, this article introduces the CAP theorem and outlines how the above-mentioned algorithms are applied to distributed systems to better balance availability, consistency, and partition tolerance.
Challenges in Distributed Systems
Distributed systems are systems of components that are located on different networked computers and communicate and coordinate their actions by passing messages to each other. Within these systems, consistency is a status where all nodes (or components) can access the latest version of data, which is easy to implement in a stand-alone scenario by using shared memory and locks.
Nevertheless, there are two major limitations to data storage in a stand-alone machine. Firstly, stand-alone machine failure leads to the entire system being unavailable. Secondly, system throughput is limited by the computing power of the stand-alone machine.
These two restrictions, however, can be overcome by using multiple machines to store multiple copies of the data. In this scenario, the client responsible for the update simultaneously updates multiple copies of the data. This then raises the potential problem of the network between multiple machines not being able to connect. If that is the case, the client responsible for updating would not be able to connect to multiple machines at once, making it impossible to ensure that the latest version of the data could be read on all clients.
To illustrate this, let’s take the example shown below with three clients and two servers. Client A is responsible for updating data. To ensure that the data on Server 1 and Server 2 are consistent, Client A sends the write of X=1 to Server 1 and Server 2 simultaneously. But when a network partition (an unavailable network) occurs between Client A and Server 2, if the write of X=1 on Server 1 is successful, then Client B and Client C will read inconsistent values of X from Server 1 and Server 2. To maintain the consistency of the X value, the write of X=1 must fail on both Server 1 and Server 2. This type of scenario is incorporated into the CAP theorem, which states that under the premise of tolerating network partitions, either the consistency of data or the availability of write operations must be sacrificed.
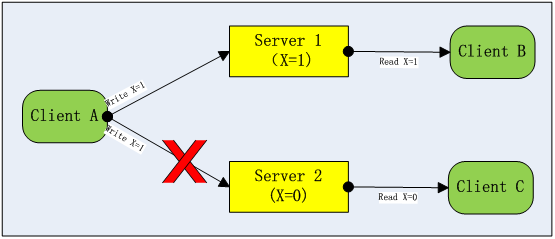 Schematic diagram of the CAP theory
Schematic diagram of the CAP theory
To solve this problem, one option would be for Client C to read and use the X values and version information on Server 1 and Server 2 simultaneously, as shown in the figure below. However, network partitioning may also occur between Client C and Server 1, which essentially sacrifices read availability for write availability and still does not break the scope of the CAP theorem.
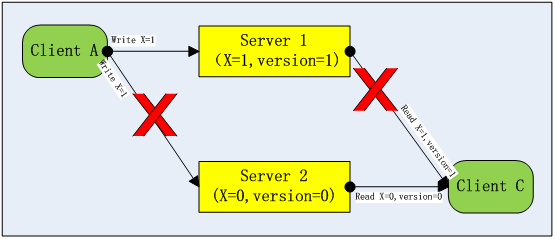 Optimization of the availability from the previous figure
Optimization of the availability from the previous figure
The CAP Theorem
The core idea behind the CAP theorem is that network-based data sharing systems can only provide two of the following three guarantees:
· Consistency (All nodes read the latest version of data)
· Availability (Data is highly available)
· Partition tolerance (Network partitioning is tolerated and the network is unavailable between partitions)
For large-scale distributed systems, network partitioning is a reality that must be tolerated and so the only real choice is between availability and consistency. The CAP theorem seems to define a pessimistic ending for distributed systems, where popular distributed systems are seemingly judged according to the theory. For example, HBase is considered to be a CP system, while Cassandra is considered to be an AP system.
The CAP theorem asserts that data in a distributed system cannot achieve availability and consistency simultaneously. However, in a system, there are often many types of data. Some data (for example, the balance of a bank account) requires strong consistency, while other data (for example, the total number of accounts in a bank) does not. Therefore, generally, the theorem is used to divide the whole system. The Alibaba team nevertheless sees the value of the CAP theorem as a guide to taking into consideration the characteristics of various data when designing a distributed system. It is also useful when carefully choosing between availability or consistency for the data when there’s a small probability that network partitioning occurs.
Another misunderstanding of the CAP theorem concerns the choosing of one issue without optimizing the other issues when designing a system. The range of the values of availability and consistency is not only 0 and 1. The value of availability can be defined as a continuous interval between 0 to 100%, while consistency can be divided into multiple different levels, such as strong consistency, weak consistency, read and write consistency, and final consistency. To be more precise, what the CAP theorem defines is that under the condition of partition tolerance, “strong consistency” and “ultimate availability” cannot be achieved simultaneously.
(Note: “Ultimate availability” is used here instead of “100% availability”, as a distributed system composed of multiple servers is less than 100% available even if consistency is not considered. If the availability of a single server is P, then the ultimate availability of n servers is . This formula means that a system is considered available as long as one or more servers are available.)
Although it is impossible to achieve strong consistency and ultimate availability simultaneously, one of them can be selected according to the data type to optimize the other one. The Paxos protocol is an algorithm that optimizes availability under the premise of ensuring strong consistency.
The Paxos Protocol
The Paxos protocol proposes that if f+1 nodes out of 2f+1 nodes in a system are available, then the system as a whole is available and can guarantee strong data consistency, which is a great improvement for availability. If we continue to assume that the availability of single nodes is P, then the normal availability of any combination of more than f+1 nodes out of 2f+1 nodes is P(total)= ; and if we assume that P=0.99, f=2, P(total)=0.9999901494, then availability will be improved from two 9s to five 9s per node. This means that a system’s annual downtime will drop from 87.6 hours to 0.086 hours, which is enough to meet the requirements of 99.99999999% applications on the planet.
The Paxos protocol compares the write request of each piece of data to a proposal. Each proposal, with a unique number, will be forwarded to the Proposer to submit and must be accepted by f+1 nodes out of 2f+1 nodes to take effect. The 2f+1 nodes are called the Quorum of this proposal, and the nodes among the Quorum are called Acceptors.
Moreover, the Paxos protocol process must meet two conditions. Firstly, the Acceptor must accept the first proposal it receives. Secondly, if the V value of a proposal is accepted by most Acceptors, then all subsequent accepted proposals must also contain V values (the V value can be understood as the content of a proposal, which consists of one or more Vs and a proposal number).
The Paxos protocol process is divided into two phases. The first phase is the preparation phase for the Proposer to learn the latest state of the proposal and includes the following steps:
1. Proposer selects a proposal number n and then sends a prepare request with the number n to more than half of the Acceptors.
2. If an Acceptor receives a prepare request with the number n and the value of n is greater than the number of all prepare requests it has responded to, then it guarantees that no proposal with a number less than n be accepted. Meanwhile, the largest numbered proposal that it has accepted, if any, is responded to.
The second Paxos phase is the submission phase of the correct proposal based on the learned state and includes the following steps:
1. If the Proposer receives a response from more than half of Acceptors for its prepare requests (numbered as n), then it sends an accept request for the proposal with the number n and the value as v to Acceptors, where v is the value of the proposal with the highest number in the response received. If the response does not contain a proposal, then v is an arbitrary value.
2. If an Acceptor receives an accept request for a proposal with number n, it can accept the proposal as long as it has not responded to a prepare request with a number greater than n.
An overview timing diagram of the Paxos protocol is shown below.
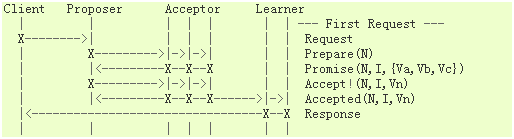 The Paxos protocol incorporates Client, Proposer, Acceptor, and Learner components
The Paxos protocol incorporates Client, Proposer, Acceptor, and Learner components
The above Paxos protocol process seems complicated because the completeness of the protocol must be guaranteed under a number of boundary conditions. For example, the initial test value must be empty and the two Proposers submit proposals simultaneously. However, the core of the Paxos protocol can be simply described as: the Proposer first learns the latest content of the proposal from the majority of Acceptors and then forms a new proposal based on the learned proposal with the largest number. If the proposal is voted by most Acceptors, it is passed. Since the set of the Acceptors that learn the proposal and the ones that accept the proposal are more than half of the total, the Proposer can definitely learn the latest proposal value. There must also be a public Acceptor in the Acceptor set passed by two proposals, and this public Acceptor guarantees data consistency when constraint b is satisfied. Therefore, the Paxos protocol is also known as the majority protocol.
The strength of the Paxos protocol is its simplicity. Any message in the Paxos protocol flow can be lost. Consistency guarantee does not depend on the success of a particular message delivery, which greatly simplifies the design of distributed systems. It is extremely compatible with the characteristics of possible network partitioning in a distributed environment. Compared with the “two-phase commit (2PC)” before the Paxos protocol, strong consistency can be guaranteed, but it is highly complex and depends on the availability of a single coordinator.
Despite the effectiveness of Paxos, ZAB has also emerged as a powerful protocol.
The ZAB Protocol
Although the Paxos protocol is complete, there are still some issues to be solved in applying it to an actual distributed system.
First, in the scenario of multiple Proposers, Paxos does not guarantee that the first submitted proposal is accepted first. It is unclear what should be done to ensure that multiple proposals are accepted in order in the actual application.
Further, Paxos allows multiple Proposers to submit proposals, so a livelock problem may occur. When the proposal n is not completed in the second phase, the first-phase prepare request of the new proposal n+1 has arrived at the Acceptor. According to the protocol, the Acceptor will respond to the new proposal’s prepare request and guarantee that it will not accept any request with a number less than n+1, which may result in the proposal n not being accepted. Likewise, if the second phase of the proposal n+1 is not completed, and the Proposer that submitted the proposal n has already submitted the proposal n+2, then the proposal n+1 may fail too.
Lastly, The Paxos protocol stipulates that as long as the v value of a proposal is accepted by most Acceptors, all subsequent proposals cannot modify the v value. In reality, this causes difficulty when there is a need to modify the v value.
By contrast, ZooKeeper’s core algorithm, or ZAB for short, solves the two aforementioned problems with a simple constraint: all proposals are forwarded to a unique Leader (selected from the Acceptors by the leader election algorithm) to submit, and the Leader guarantees the order of multiple proposals, thus avoiding the livelock problem caused by multiple Proposers.
The process of the ZAB protocol is described by a timing diagram as shown in the following figure. Compared to the Paxos protocol, the prepare phase is omitted, because the Leader itself has the latest state of the proposal, and the process of learning the proposal content is not needed. The Follower in the figure corresponds to the Acceptor of the Paxos protocol and the Observer corresponds to Learner in Paxos.
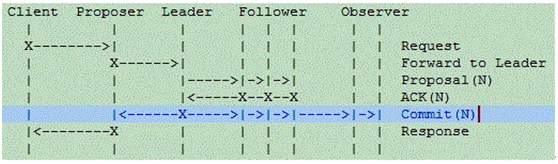 Working process of the ZAB protocol
Working process of the ZAB protocol
When ZAB introduces the Leader, it also introduces a new problem: what happens if the Leader crashes? The solution is to elect a new leader. The process of electing the Leader is also a Paxos proposal resolution process, which is not discussed further here.
So how can the v value of the proposal be modified? This is not the scope of the ZAB protocol. After studying the ZooKeeper source code, the Alibaba team realized that ZooKeeper provides a concept of znode and that it can be modified. ZooKeeper records an auto-increasing and continuous version number for each znode. Any modification (create/set/setAcl) to znode triggers a Paxos majority vote process. After the vote is passed, the version number of znode is increased by 1. This is equivalent to using multiple Paxos protocols of different versions of znode to break the limitation that a single Paxos protocol cannot modify the proposal value.
As far as the core of the algorithm to ensure consistency is concerned, ZAB does draw on the majority idea of Paxos, but it is the global timing guarantee it provides and the modifiable znode ZooKeeper provides to the user that make Paxos shine in the open source world. ZAB does not simply provide an optimized implementation of the Paxos algorithm, making it clear that ZAB is a different algorithm from Paxos.
Summary
The CAP theorem presents the claim that network partitioning is unavoidable in a distributed environment and that it results in a tradeoff between consistency and availability. The Paxos protocol proposes an extremely simple algorithm to maximize availability while guaranteeing consistency. ZooKeeper’s ZAB protocol further simplifies Paxos and provides a global timing guarantee that leads to the wide application of Paxos in industrial scenarios, making it a key reference for Alibaba’s work in computing.
(Original article by Li Jinhui李金辉)
Alibaba Tech
First hand and in-depth information about Alibaba’s latest technology → Facebook: “Alibaba Tech”. Twitter: “AlibabaTech”.
Exploring Distributed System Theory: Availability and Consistency was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.