Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Data mining is to extract valid information from gigantic data sets and transform the information into potentially useful and ultimately understandable patterns for further use. It not only includes data processing and management but also involves the intelligence methods of machine learning, statistics and database systems, as Wikipedia defines.
Data mining is also the important technology in the field of Data science, which has been ranking as the №1 best job in the USA from 2016 to 2018, from Glassdoor’s list of 50 Best Jobs in America. Besides, comparing with 1700 job openings in 2016, the number of listed job openings has increased significantly by 160% in two years. It can be foreseen that the demand for data scientists or the people who have the skills or data analysis will keep growing in the next few years.
To help our audience master the technology of data science, we have published 80 Best Data Science Books That Are Worthy Reading and 88 Resources & Tools to Become a Data Scientist before. So in this article, I would like to focus on the field of data mining, to round up the 10 essential skills you gonna need.

Computer Science Skills
1 Programming/statistics language: R, Python, C++, Java, Matlab, SQL, SAS, Unix shell/awk/sed…
Data mining relies heavily on programming, and yet there’s no conclusion on the question which is the best language for data mining. It all depends on the dataset you deal with. Peter Gleeson put forward four spectra for your reference to choose which programming language: Specificity, Generality, Productivity, and Performance, which can be regarded as a pair of axes (Specificity- Generality, Performance — Productivity). Most languages can fall somewhere on the map. R and Python are the most popular programming language for data science, according to a research of KD Nuggets.
Which Languages Should You Learn for Data Science [Freecode Camp]
Data Mining Algorithms in R [Wikibooks]
Best Python Modules for Data Mining [KD Nuggets]
2 Big data processing frameworks: Hadoop, Storm, Samza, Spark, Flink
Processing frameworks compute over the data in the system, like reading from non-volatile storage and ingesting data into your data system, which is the process of extracting information and insight from large quantities of individual data points. It can be sorted out into 3 classifications: batch-only, stream-only and hybrid.
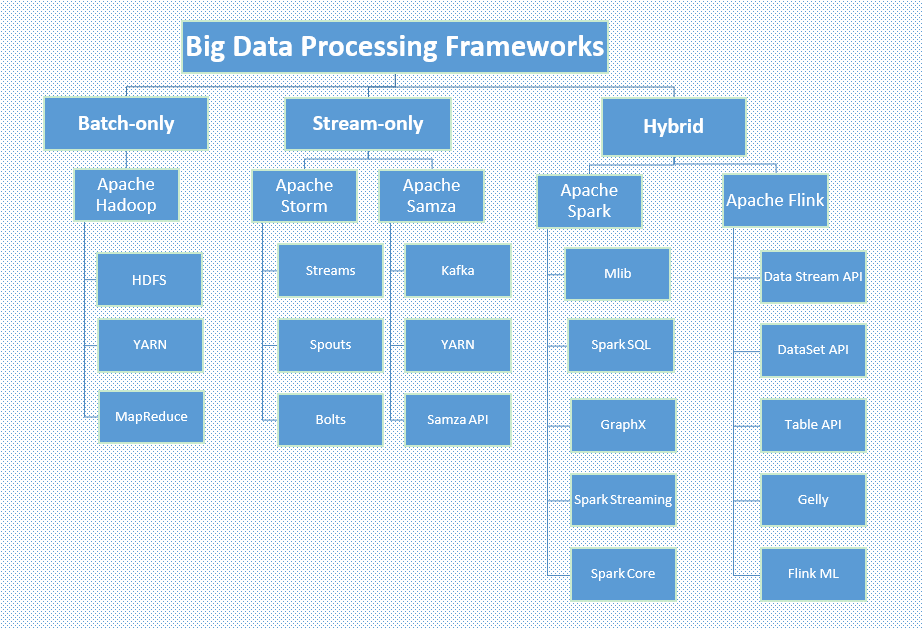
Hadoop and Spark are the most implemented frameworks so far since Hadoop is a good option for batch workloads that are not time-sensitive, which is less expensive to implement than others; while, Spark is a good option for mixed workloads, providing higher speed batch processing and micro-batch processing for streams.
Hadoop, Storm, Samza, Spark, and Flink: Big Data Frameworks Compared [Digital Ocean]
Data Processing Framework for Data Mining[Google Scholar]
3 Operating System: Linux
Linux is the popular operating system for data mining scientist, which is much more stable and efficient o/s for operating large data sets. It would be a plus if you know about common commands of Linux, and be able to deploy a Spark distributed machine learning system on Linux.
Why you should use Linux for Data Science and R [PATRICK SCHRATZ]
4 Database knowledge: Relational Databases & Non-Relational Databases
To manage and process large data sets, you must know about knowledge of relational databases, like SQL or Oracle, Or non-relational databases, whose mainly types are: Column: Cassandra, HBase; Document: MongoDB, CouchDB; Key value: Redis, Dynamo.
Statistics & Algorithm Skills
5 Basic Statistics Knowledge: Probability, Probability Distribution, Correlation, Regression, Linear Algebra, Stochastic Process…
Just recalling the definition of data mining at the beginning, we know that data mining isn’t all about coding or computer science but sits at the interfaces between multiple fields, among which Statistic in an integral part. Basic knowledge of statistics is vital for a data miner, which helps you to identify questions, obtain more accurate conclusion, distinguish causation and correlation, and quantify the certainty of your findings as well.
More resources:
What Statistics Should I Know to do Data Science [Quora]
Statistical Methods for Data Mining [Research Gate]
6 Data Structure & Algorithms
Data structures include arrays, linked list, stacks, queues, trees, hash table, set…etc, and common Algorithms includes sorting, searching, dynamic programming, recursion…etc
Proficiency in data structures and algorithms is critically useful for data mining, which helps you to come up with more creative and efficient algorithmic solutions when you’re processing large volumes of data.
7 Machine Learning / Deep Learning Algorithm
This is one of the most important parts of data mining. Machine learning algorithms build a mathematical model of sample data to make predictions or decisions without being explicitly programmed to perform the task. And deep learning is part of a broader family of machine learning methods. Machine learning and data mining often employ the same methods and overlap significantly.
More re
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.