Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Image classification using PyTorch for dummies

{kind=link}
Facebook recently released its deep learning library called PyTorch 1.0 which is a stable version of the library and can be used in production level code.
I’m a part of Udacity’s PyTorch Scholarship Challenge program and learned a lot about PyTorch and its function. Coming from keras, PyTorch seems little different and requires time to get used to it.
In this article, I’ll be guiding you to build a binary image classifier from scratch using Convolutional Neural Network in PyTorch.
The whole process is divided into the following steps:
1. Load the data2. Define a Convolutional Neural Network3. Train the Model4. Evaluate the Performance of our trained model on a dataset
1. Load the data
When comes to loading/ preprocessing the data PyTorch is much simpler as compared to other libraries. However, PyTorch has a built-in function called transforms using which you can perform all your pre-processing tasks all at once which we’ll see in a while.
For the dataset, I couldn’t find one with the faces as positive labelled, therefore I made my own dataset manually by using the images from LFW Face Dataset for positives and added some random images for the negatives which includes the images of vehicles, animals, furniture etc. If you want, you can download the dataset from here: link
The data needs to be split in Train, Test and validation set before training. Train set will be used to train the model, validation set will be used for validating the model after each epoch, and the Test set will be used to evaluate the model once it is trained.
First, we need to get the dataset into the environment, which can be done by:(Note: ‘face’ is the name of the directory which contains a positive and negative example of faces)
train_data = datasets.ImageFolder('face',transform=transform)We’ll also need to define a transform object to perform the preprocessing steps. We can mention in the object what types of processing we need. In the following code, I have defined the transform object which performs Horizontal Flip, Random Rotation, convert image array into PyTorch (since the library only deals with Tensors, which is analogue of numpy array) and then finally normalize the image.
transform = transforms.Compose([ transforms.RandomHorizontalFlip(), transforms.RandomRotation(20), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) ])
Once we are done with the loading the dataset and defining transform object we can split the dataset into train, test and validation sets as discussed before. For carrying out splits:
#For testnum_data = len(train_data)indices_data = list(range(num_data))np.random.shuffle(indices_data)split_tt = int(np.floor(test_size * num_data))train_idx, test_idx = indices_data[split_tt:], indices_data[:split_tt]
#For Validnum_train = len(train_idx)indices_train = list(range(num_train))np.random.shuffle(indices_train)split_tv = int(np.floor(valid_size * num_train))train_idx, valid_idx = indices_train[split_tv:],indices_train[:split_tv]
# define samplers for obtaining training and validation batchestrain_sampler = SubsetRandomSampler(train_idx)test_sampler = SubsetRandomSampler(test_idx)valid_sampler = SubsetRandomSampler(valid_idx)
#Loaders contains the data in tuple format # (Image in form of tensor, label)train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, sampler=train_sampler, num_workers=1)
valid_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, sampler=valid_sampler, num_workers=1)
test_loader = torch.utils.data.DataLoader(train_data, sampler = test_sampler, batch_size=batch_size,num_workers=1)
# variable representing classes of the imagesclasses = [0,1]
The train_loader, test_loader and valid_loader will be used to pass the input to the model.
Here are some random images from the dataset after applying transformations which includes resizing, random rotation, Normalizing:

2. Initialising the Convolutional Neural Network(CNN)

The CNN in PyTorch is defined in the following way:
torch.nn.Conv2D(Depth_of_input_image, Depth_of_filter, size_of_filter, padding, strides)
Depth of the input image is generally 3 for RGB, and 1 for Grayscale. Depth of the filter is specified by the user which generally extracts the low level features, and the size of the filter is the size of the kernel which is convolved over the whole image.
To calculate the dimension of the new convolution layer, the following formula is used:dimension=(dimen_of_input_image- Filter_size(int)+(2*padding))/stride_value + 1
Now it’s time to initialise the model:
class Net(nn.Module): def __init__(self): super(Net, self).__init__() # convolutional layer self.conv1 = nn.Conv2d(3, 16, 5) # max pooling layer self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(16, 32, 5) self.dropout = nn.Dropout(0.2) self.fc1 = nn.Linear(32*53*53, 256) self.fc2 = nn.Linear(256, 84) self.fc3 = nn.Linear(84, 2) self.softmax = nn.LogSoftmax(dim=1) def forward(self, x): # add sequence of convolutional and max pooling layers x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = self.dropout(x) x = x.view(-1, 32 * 53 * 53) x = F.relu(self.fc1(x)) x = self.dropout(F.relu(self.fc2(x))) x = self.softmax(self.fc3(x)) return x
# create a complete CNNmodel = Net()
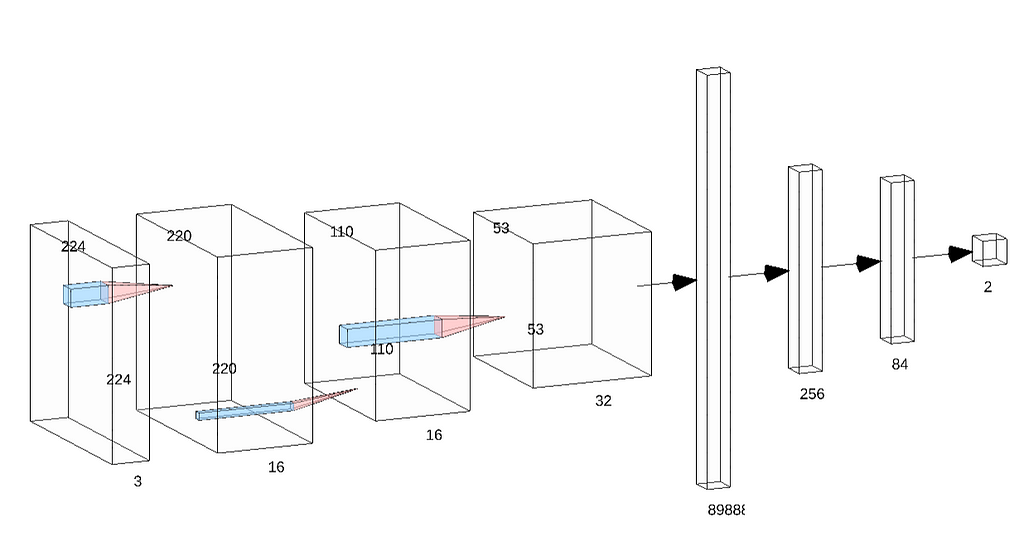 Model Architecture
Model Architecture
We’ll also need to initialise our loss function and an optimizer. Loss Function will help us in calculating the loss by comparing the prediction and original label. The optimizer will minimize the loss by updating the parameters of the model after every epoch. They can be initialised by:
# Loss functioncriterion = torch.nn.CrossEntropyLoss()
# Optimizeroptimizer = torch.optim.SGD(model.parameters(), lr = 0.003, momentum= 0.9)
3. Train the Model
It’s time to train the model!

Training a model requires us to follow some steps which are:
- Clear the gradients of all optimized variables:There could be gradients from previous batches, therefore it’s necessary to clear gradient after every epoch
- Forward pass: This step computes the predicted outputs by passing inputs to the convolutional neural network model
- Calculate the loss:As the model trains, the loss function calculates the loss after every epoch and then it is used by the optimizer.
- Backward pass: This step computes the gradient of the loss with respect to model parameters
- OptimizationThis performs a single optimization step/ parameter update for the model
- Update average training loss
Following is the code for training the model (it’s for a single epoch)
4. Model Evaluation
To evaluate the model, it should be changed from model.train() to model.eval()
model.eval()# iterate over test datalen(test_loader)for data, target in test_loader: # move tensors to GPU if CUDA is available if train_on_gpu: data, target = data.cuda(), target.cuda() # forward pass output = model(data) # calculate the batch loss loss = criterion(output, target) # update test loss test_loss += loss.item()*data.size(0) # convert output probabilities to predicted class _, pred = torch.max(output, 1) # compare predictions to true label correct_tensor = pred.eq(target.data.view_as(pred)) correct = np.squeeze(correct_tensor.numpy()) if not train_on_gpu else np.squeeze(correct_tensor.cpu().numpy()) # calculate test accuracy for each object class for i in range(batch_size): label = target.data[i] class_correct[label] += correct[i].item() class_total[label] += 1
# average test losstest_loss = test_loss/len(test_loader.dataset)print('Test Loss: {:.6f}\n'.format(test_loss))for i in range(2): if class_total[i] > 0: print('Test Accuracy of %5s: %2d%% (%2d/%2d)' % ( classes[i], 100 * class_correct[i] / class_total[i], np.sum(class_correct[i]), np.sum(class_total[i]))) else: print('Test Accuracy of %5s: N/A (no training examples)' % (classes[i]))print('\nTest Accuracy (Overall): %2d%% (%2d/%2d)' % ( 100. * np.sum(class_correct) / np.sum(class_total), np.sum(class_correct), np.sum(class_total)))After evaluation, we find the following result:
Test Loss: 0.006558
Test Accuracy of 0: 99% (805/807) Test Accuracy of 1: 98% (910/921)
Test Accuracy (Overall): 99% (1715/1728)
The result that we got was using only 2 Convolutional Layers, though researchers are using deeper networks which can extract much more detailed features.
Contact: about.me/jayrodge
Binary Face Classifier using PyTorch was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.