Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Apache Spark — Tips and Tricks for better performance
Apache Spark is quickly gaining steam both in the headlines and real-world adoption. Top use cases are Streaming Data, Machine Learning, Interactive Analysis and more. Many known companies uses it like Uber, Pinterest and more. So after working with Spark for more then 3 years in production, I’m happy to share my tips and tricks for better performance.

Lets start :)
1 - Avoid using Custom UDFs:
UDF (user defined function) :
Column-based functions that extend the vocabulary of Spark SQL’s DSL.
Why we should avoid them?
From the Spark Apache docs:
“Use the higher-level standard Column-based functions with
Dataset operators whenever possible before reverting to
using your own custom UDF functions since UDFs are a
blackbox for Spark and so it does not even try to optimize them.”
What actually happens behind the screens, is that the Catalyst can’t process and optimize UDFs at all, and it threats them as blackbox, which result in losing many optimisations like: Predicate pushdown , Constant folding.
How to avoid it?
Try to avoid UDFs as much as possible and instead use Spark SQL function — make sure to find the ones that are relevant to your Spark version
Make sure your query are optimized using
dataframe.explain(true)
Noteworthy
Avoiding UDFs might not generate instant improvements but at least it will prevent future performance issues, should the code change. Also, by using built-in Spark SQL functions we cut down our testing effort as everything is performed on Spark’s side. These functions are designed by JVM experts so UDFs are not likely to achieve better performance.
for example the following code can be replaced with notNull function
//udf exampledef notNull(s:String):Boolean = { s != null}sparkSession.udf.register[Boolean,String]("notNull",notNull)val newQuery = "select * from ${table} where notNull(some_column)"val dataframe = sparkSession.sqlContext.sql(newQuery)//builtin functionval dataframe = dataframe.filter(col("some_column").isNull)When there is no built-in replacement, it is still possible to implement and extend Catalyst’s (Spark’s SQL optimizer) expression class. It will play well with code generation. For more details, Chris Fregly talked about it here (see slide 56). By doing this we directly access Tungsten format, it solves the serialization problem and bumps performance. Implementing expression are bounded to newer Spark versions and is still considered experimental.
{kind=link}
Avoid UDFs or UDAFs that perform more than one thing
Clean code principles apply when writing big data stuff. By splitting UDFs we are able to use built-in functions for one part of the resulting code. It also greatly simplify testing and great practice in general.
2 — Look under the hood

From Dataset object or Dataframe object you can call the explain method like this:
//always check yourself using dataframe.explain(true)
The output of this function is the Spark’s execution plan and this is a good way to notice wrong executions.
Make sure you are checking yourself using explain method since Map reduce actions includes shuffling (sending data over the network). This is expensive due to network traffic, data serilazaion and disk I/O. Even with in-memory database those are still expensive. Although Spark does in memory map-reduce, during shuffling Spark still uses the disk.
In order to reduce the number of stages and shuffling, best practice is first to understand the stages and then search for a way to reduct the complexity.
This is en example of calling explain method of a query with UDF :
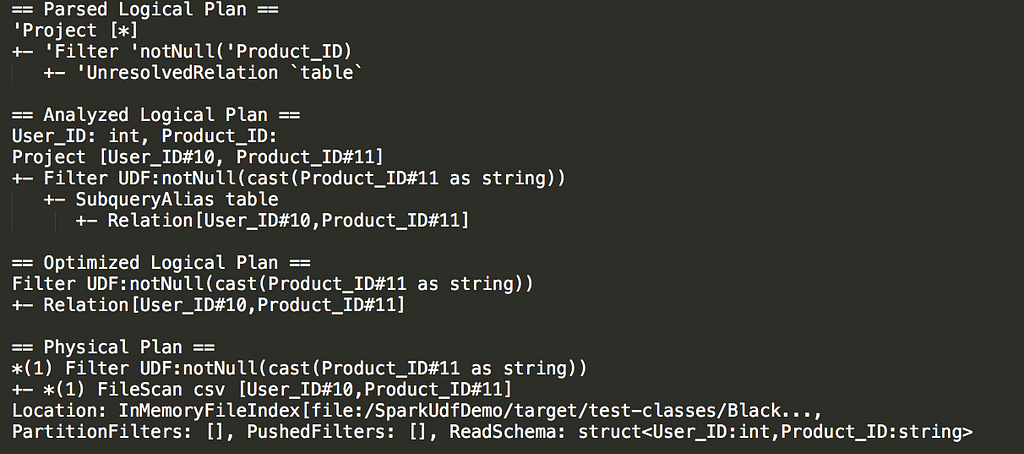 Filter using UDF
Filter using UDF
From the filtering stage you can see that casting takes place and it happens on each time an entry goes through the UDF . In our case it cast it to string.
In the physical plan we see what will actually happen in our executors, we see the partition filters, pushdown filters, the schema, the project method (here it is file scan because it’s a CSV file).
Without UDF — we might benefit from the pushdown filter which will happen at the storage level, that means that it won’t load all the data into Spark memory because the Spark process reads the data after the storage already filtered what’s needed to be filtered. Read here more about why pushdown is extremely important for performance.
This is an example with explain method over our second query where we used the Spark sql function — is null.
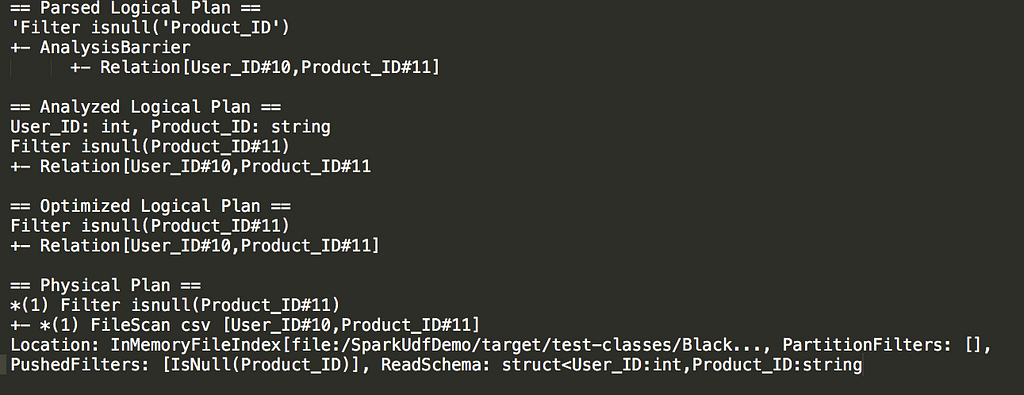 Filter using builtin functions
Filter using builtin functions
From the output, we can see that we are using the power of Pushdown filter (last line in the physical plan).
3- Tungsten makes Spark shines well above others
This is one of Spark’s strength and the reason it shines way above traditional hadoop Map-Reduce.
Tungsten focuses on substantially improving the efficiency of memory and CPU for Spark applications, to push performance closer to the limits of modern hardware. it includes memory management, cache-aware computations, code generations and more. you can read about it here.
4- It’s all about your data
Know your data. Thats relevant to every data at scale system and production products you develop. Distribution of the data, how much data you expect to receive. What is the max data bandwidth, what is normal, min, max etc.This will impact the way you create your product architecture.
5- know your cloud configuration
I’m working with Azure and there are many ways to run Spark on Azure with varies configurations. Apache Spark on HDInsight, Azure Databricks and more. The way to work with them is strictly depended on the end goal.
In the next big data blog post I will share more way to use Apache Spark on Azure with real life use cases.
For now, read Apache Spark — Catalyst deep dive to understand how Spark query engine works.
Follow me on Medium for more posts about Scala, Kotlin, Big data, clean code and software engineers nonsense. Cheers !

Apache Spark — Tips and Tricks for better performance was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.