Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.

Verifiable Claims are a new type of data resource with high-definition qualities. This represents a unique new class of information. High-definition data has very many useful applications in the digital world that could profoundly change how society operates in the physical world, as this is the basis for establishing webs of trust, between people, machines and information.Data captured in this format can be high in resolution and high in fidelity. This article explains the core concepts of these new standards and proposes how thinking about data having ‘high-definition’ qualities could produce engineering and data-science breakthroughs.
Let’s start with some easy information theory
Information theory is a way of explaining how information gets quantified, stored and communicated. I would add to this scope how information gets valued.
Graphs
A particularly useful sub-domain of information theory is Graph Theory. This helps us explain the ways in which information is inter-connected.
We can use the analogy of friendships to understand how information (about people) is connected by describing their relationships (such as friendship).
In Graph Theory, the terminology Nodes and Edges provide basic abstractions for describing information objects (Nodes) and their connections (Edges). You can mentally build the components of a graph by thinking of people as nodes and their relationships as edges. In this analogy, people are dots and relationships are the lines connecting them.
Friendships are usually reciprocated, so the edges connecting two friends will have arrows at each end. This is cyclical and dynamic. It recognises interactions as information flows (including feelings!) — both ways, between friends.
But if someone thinks of you as a friend and you think of them as just an acquaintance, the edge between you could point only to you, as a one-way edge. Nodes that are connected exclusively by one-way edges create a directed graph. The fact that each individual is unique and has unique edges, means that the graph is acyclic. The graph does not repeat as you traverse it. In technical terms this is a Directed Acyclic Graph (DAG).
Why this distinction between general graphs and directed acyclic graphs is relevant becomes more obvious when we look into specific applications of graph theory in information technologies, such as the Web and blockchains.
Linked-data graphs
Linked-data is a new web specification that has been formalised by the World Wide Web Consortium (W3C), with the belief that this can organise and connect data in ways that will create a better Web.
Linked Data empowers people that publish and use information on the Web. It is a way to create a network of standards-based, machine-readable data across Web sites. It allows an application to start at one piece of Linked Data, and follow embedded links to other pieces of Linked Data that are hosted on different sites across the Web.
Generally speaking, the data model for linked-data (encoded as JSON-LD) is a generalised, labeled, directed graph that can have cyclical connections, be acyclic, or both. The graph contains nodes that are typically data such as a string, number, typed values (dates, times…), or a resource locator (IRI).
This simple data model is incredibly flexible and powerful. It is capable of modelling almost any kind of data — including the example of networks of friends with reciprocal relationships!
Directed acyclical graphs
In the data model for directed acyclical graphs (DAGs), each node is unique and has unique edges.
This simple data model is also incredibly flexible and powerful, as it is capable of modelling almost any kind of data. In our human relationship analogy this describes the one-way relationships between a network of people who are only acquaintances — when there is no reciprocity!
Where DAGs have the edge over general linked-data graphs, is that they are a deterministic. This is the reason that DAGs are the basis for blockchain-type data structures, where the ordering of information is consequential.
Merkle DAGs
A Hash is a practical abstraction of information. It is produced by algorithmically transforming any data input into a deterministic fixed output — such as a 256 character string of letters and numbers.
Data has higher degrees of fidelity when it can be reliably reproduced and the information it encodes does not become corrupted or decayed through the forces of entropy over time. We say the data is verifiable. Cryptographically encoding data, using a hash function, provides mathematically provable informational fidelity. This also makes data easier to find through content addressability. The uniqueness of each data resource, represented by its hash value, gives the information an identifiable fingerprint. This makes the data non-fungible, which is a big deal for reducing data errors and accounting fraud, such as double-counting.
Ralph Merkle made a massive contribution to information technology when he proposed a method of hashing data and then linking this data using its hash-value. The hash value of a node of information is added to the header of a new node of information, which is then hashed. This creates an encoded relationship between the nodes. The data is linked through the hash reference directing back to the previous node, in a chain of links. As each node (represented by its hash value) is unique, the edges between these nodes are also unique. As information can only be added deterministically, this creates a directed acyclic graph. In this case, we refer to it as a Merkle DAG.
A Merkle DAG solidifies digitally-encoded information into a series of unchangeable state representations.
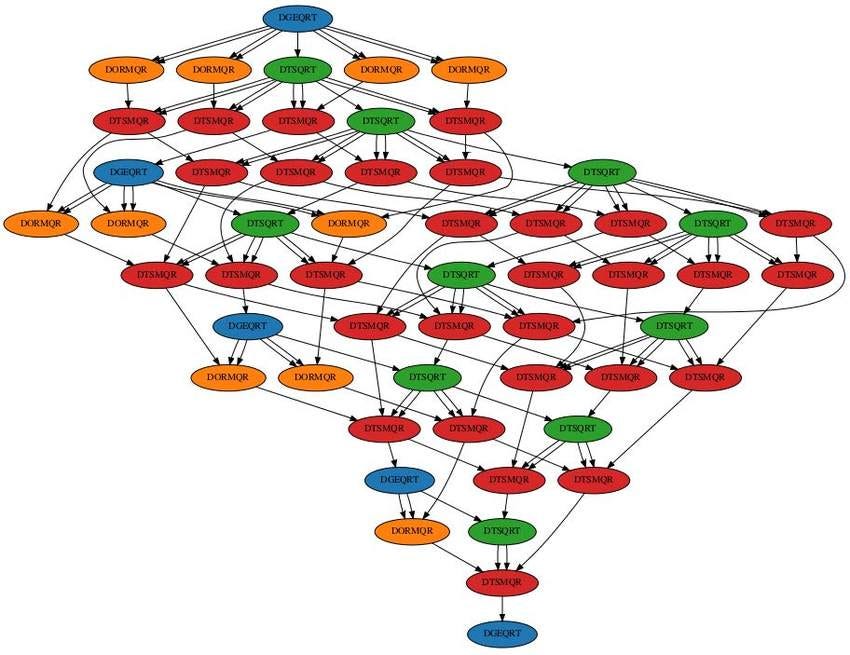
The content address of any node of claims data can be defined by the cryptographic hash of the data. The direction of the graph flows from children to parents. Nodes with no parents are considered leaves and must have at least one child vertex in order to be connected to the graph.This is represented in the figure, where each claim that can be attributed to another claim is shown as a node. The relationships between nodes are represented as edges in the graph of the nodes (the lines that connect nodes on the visual representation of this graph).
These data structures add a powerful new capability to capture the state of a whole graph of information — including the state of all the nodes and the state of all their relationships. We will see how this elevates both the resolution and fidelity of information — especially when this information is about a uniquely identified subject. This produces high-definition data which can be used for a range of applications that were not previously possible!
Decentralised Identifiers
Identifiers can be thought of as record-locators. In the context of databases, these are the Primary Keys of the database. The problem is that each database has its own set of record locators and the keys are owned and controlled by owners and administrators of the database. This results in records being ‘trapped’ — which is not great if they contain personal information about us, or if we want to share records across database systems.
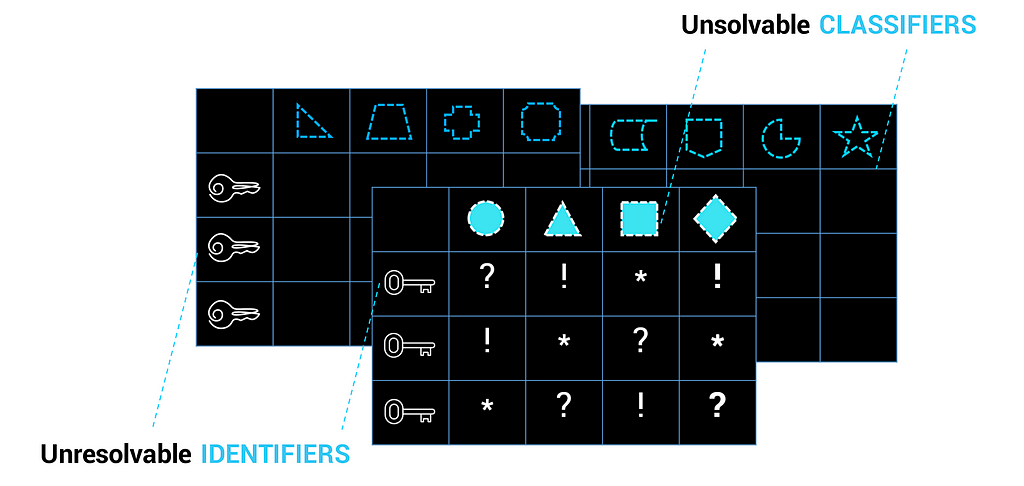 Limitations of traditional (Web 2.0) Databases
Limitations of traditional (Web 2.0) Databases
A new identifier standard has been born out of the work of the Rebooting the Web of Trust community. This is now being formalised through the W3C as the Decentralised Identifier (DID) specification. A DID is a universally unique identifier (UUID) that is derived using a specific method (such as hashing other specific information). This could be placed on a decentralised public key infrastructure (DPKI), such as a blockchain, where it is available as a record-locator.
A DID enables records to be created in which data resolves to the unique identifier (or to deterministic derivatives of this identifier). These records do not have to be trapped in any one database. Multiple records about the same subject identifier can be correlated across systems and over time. This potentially means more nodes and more edges. It increases the density of the data, which effectively elevates the definition of this data to higher degress of resolution. Now finally we have the prospect of truly ‘high-resolution’ data — much liken we have seen the evolution of ever higher-resolution cameras for capturing images! The technological advance from here is to further liberate data from Web 2.0 databases, to grow more connected and increasingly useful graphs of information.
A further characteristic of DIDs is that they enable records to be located by using associated URIs in a DID Document record. They also enable the controller (owner?) of the DID to be authenticated, using cryptographic signing keys that are recorded in the DID Document. These are powerful features, but a topic for another article.
Verifiable Claims
What brings this together is Verifiable Claims. This provide a new way of collecting, communicating and storing data about an identified subject, using a data structure that can be reliably reproduced and proven not to have changed.
Note: Verifiable Claims are now referred to as Verifiable Credentials by the W3C working group that is formalising this specification. Although this is semantic, I feel it limits interpretation of the scope of applicability of this important new data standard. We continue to use the term Verifiable Claims for the general use-case and refer to Verfiable Credentials for the sub-set of claims about identity.
Verifiable Claims uses Linked-data in the JSON-LD format, to provide context to information being claimed. This relates the data contained in the claim to external information sources. For instance: in the context of claiming that the “name” attribute value of this person is “Alice”, we are referring to the “schema.org/person” definition of “name”.
A Verifiable Claim embeds the decentralised identifier (DID) of the subject. This enables specific attribute values to be correlated with the subject across multiple claims.
The claim is hashed to secure the information it contains and this produces a unique identity for the claim. Further fidelity is added to the claim by the issuer adding their DID to the record and cryptographically signing the claim, which means this can be authenticated.
Higher-definition Verifiable Claims
Now we get to the innovations that could be made possible by thinking with the paradigm of High-definition Data.
What if we combine Verifiable Claims with Merkle DAGs?
DAGs work well for recording claims (which could include statements, attestations, opinions, or other observations) that are attributed to identifiable things that already exist — including abstract things. This is because DAGs can only be created by hashing existing information.DAGs can therefore be used to establish graphs of verifiable claims that are correlated with decentralised identifiers.
Claims exist as temporal (point-in-time) opinions or factual states. Past claims may not be changed, regardless of subsequent events, so the edges of an attribution DAG only point upstream, to earlier claims or events.For this reason, DAGs are ideal for describing how a given claim is connected to past claims about a target subject. This provides the information for building graphs of claims wherein chains of attribution can add levels of assurance for each claim.
Verifiable Claims could be connected through multi-class attribution networks. This will product graphs of different classes of attribution pointing to a credential that will have a deterministically higher level of resolution and fidelity. This would be achieved by adding classifying meta-data to Verifiable Claims and then linking this metadata through Directed Acyclical Graphs. Classifiers could include types of attestations, or attestation weightings.
The density of these graphs increase as a function of both the number of unique data points, as well as the strength of the relationship ties between nodes and the target identifier. As more data points become linked together into this graph and as these become reinforced through chains of attribution, claims become higher-definition.
Recording the existence of a Verifiable Claim, by referencing its hash value in a Merkle DAG (or blockchain transaction), also adds provenance to the credential by recording an original state of the claim that can be compared to future states of the claim.
Applications and use-cases
For digital identity applications, the high-definition format of Verifiable Claims could increase both the informational value and the utility of identity credentials. For instance, by using attribution networks to increase the level of identity assurance (which is the probability that a credential is both true and positively correlated with a subject).
These principles equally apply to applications beyond identity. We have proposed the concept of High-definition Impact Claims in the ixo protocol.
For recording impact, the Verifiable Claims format generates valuable digital assets that have provable attribution and statistical integrity. These types of assets can be further enriched through intelligent transformations — adding more information to the claim. For instance, claims of carbon emission reductions from Kilowatt hours of clean energy generated can now be used to quantify carbon credits.
Through the verification process, uniquely identified digital assets get produced. These assets can be cryptographically tokenised. Carbon Credits become Carbon Tokens. This has the advantages of decreasing the fungibility of the data, whilst increasing the financial fungibility — which gives these assets more liquidity, as they can now be trustlessly traded through low-friction digital transactions and exchanges.
Initial thoughts on how to engineer a High-Definition Data system
A DAG encodes the relationships between claims in a way that can increase both the resolution and fidelity of each claim in the chain. Each claim in this construct attributes information to the identified subject in a way that is measurable and that can be relatively valued for its degree of attribution. This mapping can be encoded and stored in a hash table or IPFS. The graph is read by using the hash address of the data to return the data itself. The attribution metadata can be statistically weighted and rated to calculate probabilistic determinants about the identified target claim.
Further ideas to explore
Now that we have this generic structure for attributing chains of claims with target identifiers, we could start considering how new classes of claims metadata might add degrees of informational definition to a claim and make it even higher-defintion in both resolution and fidelity.
Acknowledgements:
Michael Zargham and Matt Stephenson for their paper on Colored Directed Acyclic Graphs for Multi-class Attribution Networks (which inspired and informed this article)
High-definition Data was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.