Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
This article is part 1 of a 5-part mini-series on DataOps at Alibaba. This installment looks at how Alibaba uses a project migration method to remove bottlenecks in its operations with big data platform MaxCompute, among other optimizations.
In the world of big data, elaborate computing platforms are a necessary tool for dealing with the sheer scale of processing needs that users’ business goals present. More recently, however, they have also become the focus of efforts to evolve from human decision making toward data-driven decision making in operations and maintenance, creating a series of development challenges for major tech firms like e-commerce giant Alibaba.
MaxCompute, formerly known as ODPS, stands alone in Alibaba’s technical ecosystem as an internally-developed big data platform carrying vast amounts of transaction data vital to the group’s operations. While this platform greatly facilitates the work of operations and maintenance professionals, it is nevertheless prone to performance-limiting congestion, requiring the group to devote considerable efforts toward optimization.
Logically, MaxCompute is grouped as a unified big data pool, with transparent, interdependent EB-scale data. Physically, however, it is a cluster assembly spanning multiple regions, which presents a huge challenge in terms of capacity bottlenecks that can lead to the hinderances mentioned above.
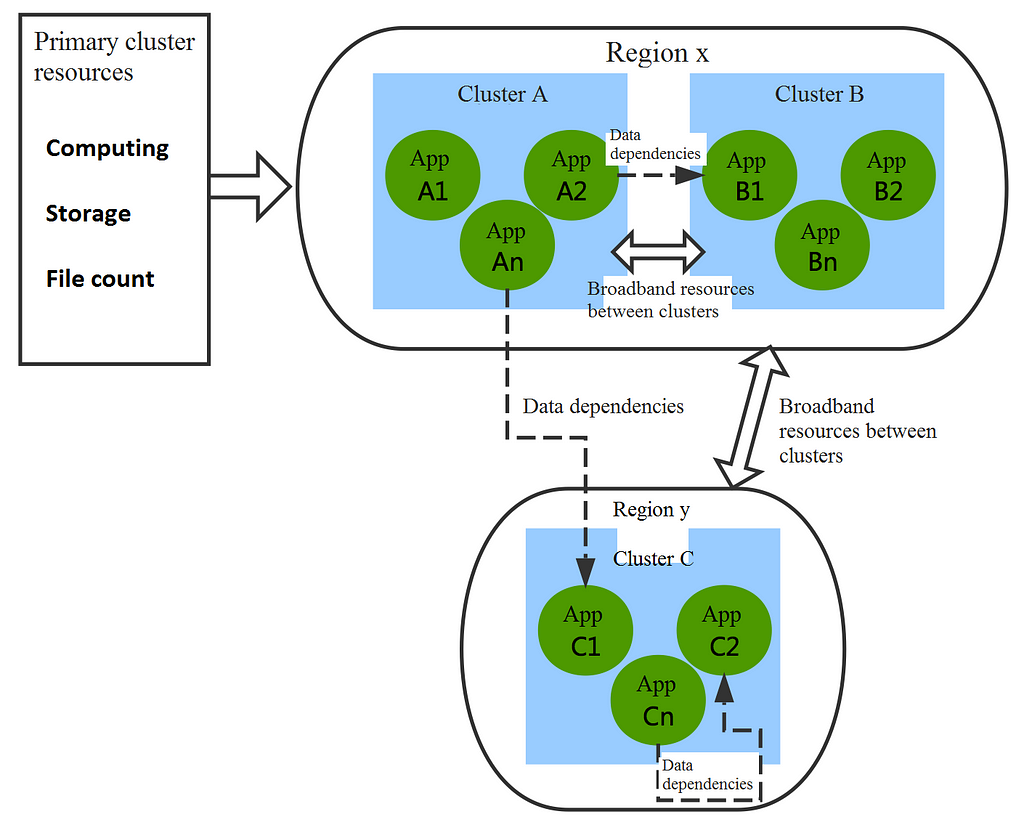
In MaxCompute, clusters contain multi-dimension resources such as computing, storage, and file count. They also have bandwidth resources for communications between clusters, with bandwidth costs varying according to the distance between clusters. Projects, meanwhile, differ in their consumption of resources in different dimensions, as well as in the time periods required for computing resource consumption. In addition, there are data access dependencies between projects that consume bandwidth resources between clusters. As business demands grow, the number and size of clusters likewise continue to expand, making the dependencies between projects increasingly complex.
In light of these conditions, optimization is a process both of understanding and subsequently addressing a series of interdependent computing problems. In today’s article, we look more closely at the basis for these issues and the migration methods Alibaba employs specifically for its operations on MaxCompute, with insights aspiring data professionals can apply to their own work.
Optimization Basics: Two Approaches
When any of a cluster’s resources (computing, storage, or file count) reaches a bottleneck in MaxCompute, it affects the corresponding services and reduces the utility efficiency of other resources, causing capacity management problems. There are currently two main solutions to this issue.
The first approach is capacity extension through machine procurement, which requires accurate forecasting of clusters’ future resource consumption and a reasonable procurement budget.
The second is optimization of MaxCompute’s project layout across different clusters, including global layout optimization and local migration strategy optimization. Global layout optimization is equivalent to disorganizing all online projects and re-allocating them among clusters. Local migration strategy optimization involves project dispatching in advance for clusters prone to resource bottlenecks and stability issues. Due to restrictions from the degree of automation, migration efficiency, and actual business conditions surrounding project migration, implementing global layout optimization presents certain difficulties.
To date, Alibaba has made significant progress in both procurement budgeting and local project migration. The following sections will introduce the limitations of previous approaches before explaining in detail how the data- and algorithm-based solution can be used to achieve local project migration strategies.
Experience and Its Limits: Human-driven Solutions
In the past, project migration work in MaxCompute relied heavily on the experience of Alibaba’s operation and maintenance personnel and their sensitivity to the “high water mark” for resources in each dimension. However, relying on human decision-making presents several limitations.
First, since cluster resources span many dimensions, operation and maintenance personnel are liable to overlook migration needs in time to handle them, despite spending much of their time monitoring indicators.
Another restriction is the high number of projects online, each of which has multi-dimensional attributes. Due to the differing intensity of data dependencies in different projects, it is difficult to consider all factors and make the optimal migration decisions. Operation and maintenance personnel usually develop a migration solution at a coarse granularity according to the category of the service.
Finally, migration of a project will affect the entirety of MaxCompute at all levels, and it is difficult to accurately estimate and quantify this impact before the migration strategy has been fully implemented. In order to prevent a shortage of resources or a contraction in inter-cluster bandwidth following migration, migration plans generally err on the side of caution.
Toward a data-driven solution: DataOps
The resource dispatching experience that operation and maintenance personnel contribute is highly valuable. Still, big data platform construction and service providers need a weapon-like command of data and the ability to use it in decision-making to break through bottlenecks human insight alone cannot resolve.
In this sense, data can help with rapid and even early detection of migration needs, refine solutions in project migration optimization strategy, and provide accurate quantitative assessment of migration results.
Optimized Algorithm Design: A Blueprint for Migration
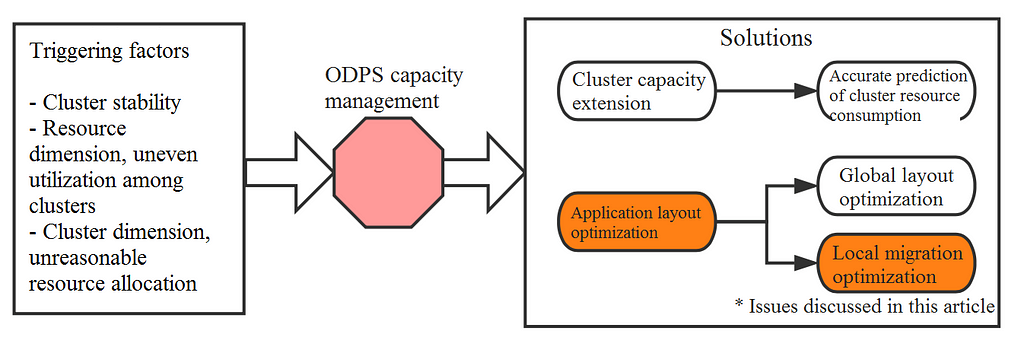
Overall, data-based solutions to bottlenecking consists of three key steps.
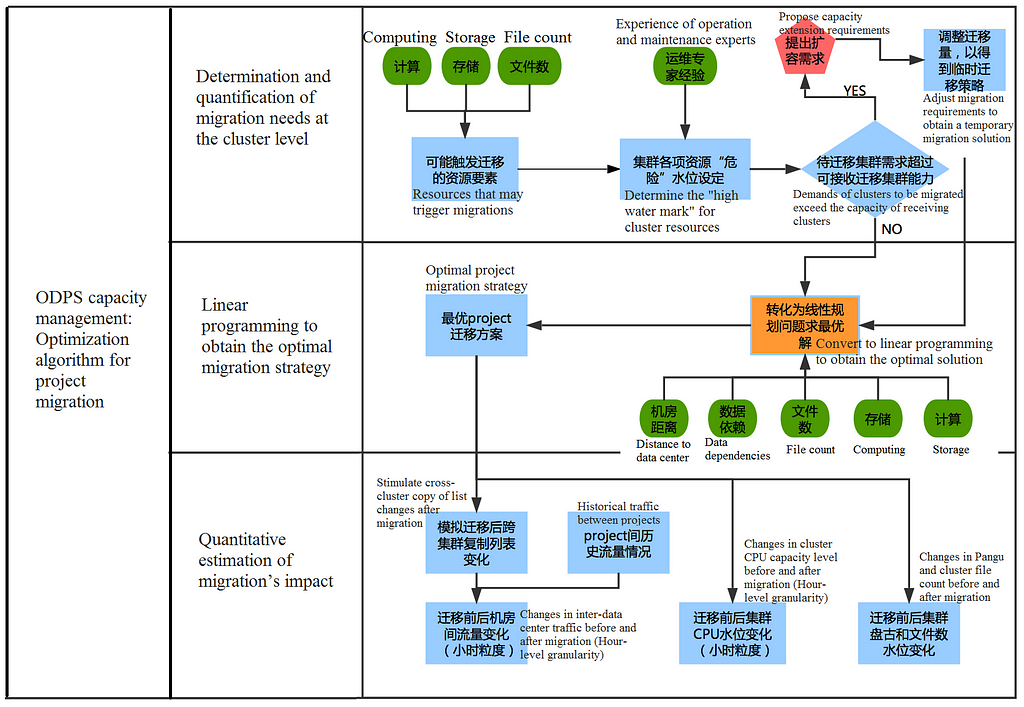
First, migration needs need to be determined and quantified at the cluster level. This decides which clusters and how many resources need to be migrated, which clusters will be able to receive the migrated project, and how much capacity each resource has.
Second, linear programming is needed to obtain the optimal migration strategy. The objective of this step is to pick the most appropriate project to migrate to the most appropriate cluster.
Lastly, quantitative estimation of the migration’s impact enables analysis of its consequences at the resource level and the bandwidth consumption of the cluster. Because real-life scenarios are complex and introduce problems such as cross-cluster replication, some impact factors can only be quantified with simulation computing according to the layout of the new project once the migration solution has been obtained. The purpose of quantifying the migration’s impact is to give operation and maintenance personnel a graphic, visual display which can help them judge the feasibility of the algorithm, which is especially important in its initial stage. You can also type a keyword to search online for the video that best fits your document. To make your document look professionally produced, Word provides header, footer, cover page, and text box designs that complement each other.
 Quantifying migration needs at the cluster level
Quantifying migration needs at the cluster level
Each online cluster on MaxCompute has a different server size, computing and storage capacity, and scalability. Therefore, based on the expertise of operation and maintenance personnel and historical operation records of the clusters, Alibaba sets a custom “migration threshold” and “receiving threshold” for each resource of each cluster.
Next, MaxCompute’s resources show obvious peak usage periods which are considered to help quantify migration needs, mainly in terms of the thresholds found during peak hours. Combined with the overall capacity of cluster resources, this yields an accurate sense of the specific migrating and receiving quantities.
In addition, sometimes the demand presented by the clusters which need to be migrated exceeds the capacity of receiving clusters, indicating that the overall platform needs further capacity extension. However, since capacity procurement takes time, the algorithm adjusts migration needs according to the receiving capacity and generates a temporary migration solution to solve immediate online problems.
Deploying linear programming
After determining migration needs and receiving capabilities at the cluster level, the next step is to choose the best migration solution among the many projects in the clusters to be migrated. For this, there are several key points to consider.
First, the solution must meet the migration needs presented by the computing, storage, and file count in the clusters to be migrated, and must not exceed the capacity of each corresponding resource in the receiving clusters.
Secondly, unlike storage and file count, the consumption of computing resources of different projects depends highly on their time frames. Thus, computing resources need to be refined to hour-level granularity.
Finally, as previously mentioned, there are data access dependencies between projects which consume bandwidth between clusters, with the bandwidth costs between clusters differing by regional location. In migrating projects, it is important to control bandwidth consumption between clusters.
The process described above can be expressed as a constrained optimization problem, and both constraints and objective functions are linear. Linear programming is one of the best-known methods for solving optimization problems.
The standard form of a typical linear programming is as follows:
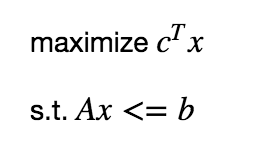
In the migration problem, a decision variable x can be used to determine whether a project should be migrated from cluster A to cluster B, with x=0 meaning that it should not be and x=1 meaning that it should. That is to say, the decision variable is a “0 or 1” variable, and therefore the linear programming problem here actually corresponds to 0/1 integer programming.
In the objective function, the distance between data centers (the bandwidth cost) and the data dependencies between projects should be considered. Under the constraints, the migration needs for the resources of the clusters to be migrated and the capabilities of the receiving clusters are crucial information.

There are many ways to solve linear programming problems, such as the simplex algorithm, interior point method, and many scientific calculation tools such as matlab and scipycan. There are also many optimization solvers that can efficiently solve large-scale linear programming, mixed integer programming, and other related problems, such as Cplex, Gurobi, and others.
Migration’s Impact: Quantitative Estimation
The impact of project migration on the cluster can help the operators to intuit the effect and impact of the migration more broadly, and can be divided into three parts for analysis.
First, migration’s impact on the storage capacity level and file count should be considered. Since the data volume and number of files in a project are relatively stable, it is easy to determine the impact of the migration solution on the capacity level of the cluster’s storage and file count.
Second, its impact on computing capacity levels must be examined. A project’s computing resource consumption has a strong correlation with time, and different projects vary greatly in their consumption of computing resources. The CPU consumption of each project in the migration list is amortized to every hour in the run-time period, and then the 24-hour CPU level of the cluster after migration is estimated.
Lastly, the impact on traffic size between clusters needs to be analyzed. In the preceding linear programming, the data dependencies between projects are placed into the objective function for optimization, rather than into constraints. This is because according to the data dependencies between projects and the cluster layout of projects at the time, a cross-cluster replication list based on some complex rules is generated online each day, which converts the data that must be directly read across clusters into internally readable data within a cluster. Thus, there is no way to estimate the traffic between online clusters until the migration strategy has actually been created. After solving the migration strategy with linear programming, a new cross-cluster replication list needs to be simulated based on the rules and the new project layout, and then estimate the change in traffic between data centers brought by migration based on historical online traffic.
Key Takeaways
Smart migration systems allow operation and maintenance specialists to form an accurate quantitative assessment of each migration task, as well as a way to visualize the possible approaches they are aware of based on experience. With such platforms, they can not only see migration solutions dynamically computed according to the current capacity levels of clusters, but also input tailored migration requirements and constraints to customize an optimal migration strategy. Through parallel dispatch, they provide support for simultaneous operation and computation by multiple operation and maintenance engineers.
For each migration requirement, the platform solves and displays the results in detail, including the specific optimal migration strategy obtained by the algorithm, the estimated changes in capacity level of the computing and storage cluster resources before and after migration, the estimated changes in inter-cluster traffic before and after migration, and the estimated changes in cross-region bandwidth usage before and after migration.
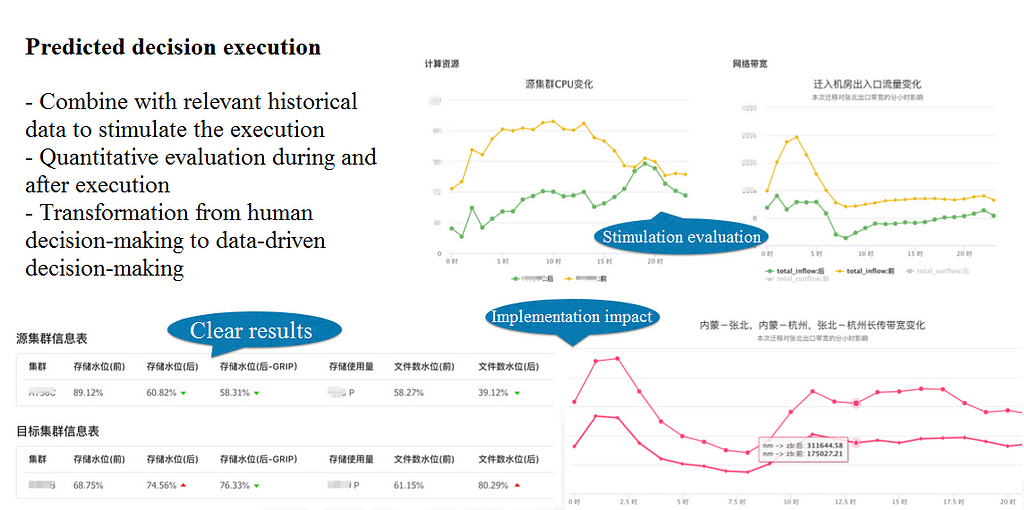
Project migration optimization is a technology for offline big data services that uses DataOps to drive capacity management and resource allocation. In its algorithm model, multi-dimensional resource factors are integrated to find the optimal migration strategy under given constraints and to quantify the impact of migration. While already powerful, these tools still only reflect an early stage of development, and Alibaba continues to invest in optimization strategies that use machine learning and time series analysis methods to predict cluster resource consumption, guide machine procurement, and assist advanced detection of migration needs for early action on solutions.
In our upcoming article, “The DataOps Files II: Resource Consumption”, we will look at how Alibaba is researching advanced forecasting models for future resource consumption.
Alibaba Tech
First hand and in-depth information about Alibaba’s latest technology → Facebook: “Alibaba Tech”. Twitter: “AlibabaTech”.
The DataOps Files I: Project Migration was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.