Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.

Learn how to solve a playing chess problem with Bayes’ Theorem and Decision Tree in this article by Dávid Natingga, a data scientist with a master’s in engineering in 2014 from Imperial College London, specializing in artificial intelligence.
Playing chess — independent events
Suppose you are given the following table of data. This tells you whether or not your friend will play a game of chess with you outside in the park, based on a number of weather-related conditions:

Now, establish using Bayes’ theorem, whether your friend would like to play a game of chess with you in the park given that the Temperature is Warm, the Wind is Strong, and it is Sunny.
Analysis
In this case, you may want to consider Temperature, Wind, and Sunshine as the independent random variables. The formula for the extended Bayes’ theorem, when adopted, becomes the following:

Now, count the number of columns in the table with all known values to determine the individual probabilities.
P(Play=Yes)=6/10=3/5, since there are 10 columns with complete data, and 6 of them have the value Yes for the attribute Play.
P(Temperature=Warm|Play=Yes)=3/6=1/2, since there are 6 columns with the value Yes for the attribute Play and, of those, 3 have the value Warm for the attribute Temperature. Similarly, you’ll have the following:

Thus:
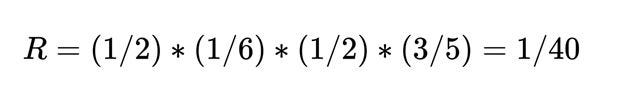
and

Therefore, you’ll have the following:

This means that your friend is likely to be happy to play chess with you in the park in the stated weather conditions, with a probability of about 67%. Since this is a majority, you could classify the data vector (Temperature=Warm, Wind=Strong, Sunshine=Sunny) as being in the Play=Yes class.
Playing chess — dependent events
Now, suppose that you would like to find out whether your friend would like to play chess with you in a park in Cambridge, UK. But, this time, you are given different input data:
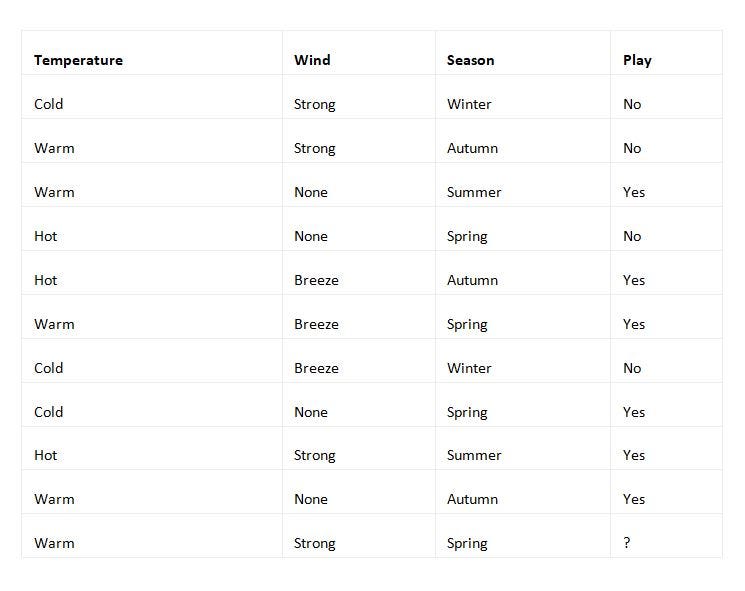
Now you may be wondering how the answer to whether your friend would like to play in a park in Cambridge, UK, will change with this different data in regard to the Temperature being Warm, the Wind being Strong, and the Season being Spring.
Analysis
You may be tempted to use Bayesian probability to calculate the probability of your friend playing chess with you in the park. However, you should be careful, and ask whether the probability of the events is independent of each other.
In the previous example, where you used Bayesian probability, you were given the probability variables Temperature, Wind, and Sunshine. These are reasonably independent. Common sense tells you that a specific Temperature and Sunshine do not have a strong correlation to a specific Wind speed. It is true that sunny weather results in higher temperatures, but sunny weather is common even when the temperatures are very low. Hence, you considered even Sunshine and Temperature as being reasonably independent as random variables and applied Bayes’ theorem.
However, in this example, Temperature and Season are closely related, especially in a location such as the UK, your stated location for the park. Unlike countries closer to the equator, temperatures in the UK vary greatly throughout the year. Winters are cold and summers are hot. Spring and fall have temperatures in between.
Therefore, you cannot apply Bayes’ theorem here, as the random variables are dependent. However, you could still perform some analysis using Bayes’ theorem on the partial data. By eliminating sufficient dependent variables, the remaining ones could turn out to be independent. Since Temperature is a more specific variable than Season, and the two variables are dependent, keep only the Temperature variable. The remaining two variables, Temperature and Wind, are independent.
Thus, you get the following data:
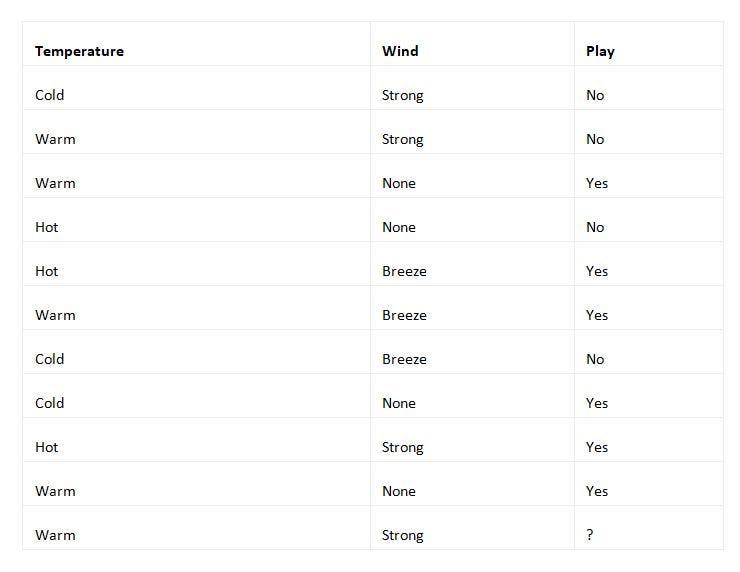
You can keep the duplicate rows, as they give you greater evidence of the occurrence of that specific data row.
Input:
Saving the table, you get the following CSV file:
# source_code/2/chess_reduced.csv
Temperature,Wind,Play
Cold,Strong,No
Warm,Strong,No
Warm,None,Yes
Hot,None,No
Hot,Breeze,Yes
Warm,Breeze,Yes
Cold,Breeze,No
Cold,None,Yes
Hot,Strong,Yes
Warm,None,Yes
Warm,Strong,?
Output:
Input the saved CSV file into the naive_bayes.py program and you’ll get the following result:
python naive_bayes.py chess_reduced.csv
[['Warm', 'Strong', {'Yes': 0.49999999999999994, 'No': 0.5}]]The first class, Yes, is going to be true, with a probability of 50%. The numerical difference resulted from using Python's non-exact arithmetic on the float numerical data type. The second class, No, has the same probability, that is, 50%, of being true. Thus, you cannot make a reasonable conclusion with the data that you have about the class of the vector (Warm, Strong). However, you have probably already noticed that this vector already occurs in the table with the resulting class No. Hence, your guess would be that this vector should just happen to exist in one class, No. But, to have greater statistical confidence, you would need more data or more independent variables to be involved.
Playing chess — analysis with a decision tree
Now, find out whether your friend would like to play chess with you in the park. But this time, use decision trees to find the answer:
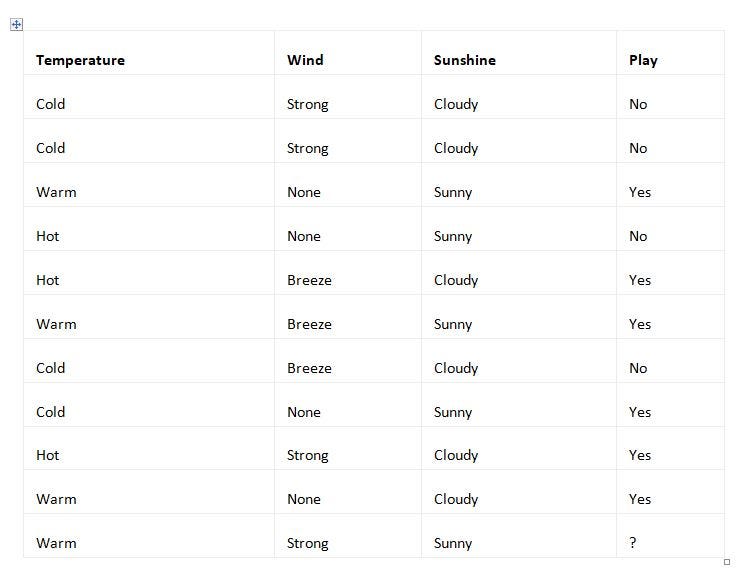 Analysis
Analysis
You have the initial set, S, of the data samples, as follows:
S={(Cold,Strong,Cloudy,No),(Warm,Strong,Cloudy,No),(Warm,None,Sunny,Yes), (Hot,None,Sunny,No),(Hot,Breeze,Cloudy,Yes),(Warm,Breeze,Sunny,Yes),(Cold,Breeze,Cloudy,No),(Cold,None,Sunny,Yes),(Hot,Strong,Cloudy,Yes),(Warm,None,Cloudy,Yes)}First, determine the information gain for each of the three non-classifying attributes: temperature, wind, and sunshine. The possible values for temperature are Cold, Warm, and Hot. Therefore, you’ll partition the set, S, into three sets:
Scold={(Cold,Strong,Cloudy,No),(Cold,Breeze,Cloudy,No),(Cold,None,Sunny,Yes)}Swarm={(Warm,Strong,Cloudy,No),(Warm,None,Sunny,Yes),(Warm,Breeze,Sunny,Yes),(Warm,None,Cloudy,Yes)}Shot={(Hot,None,Sunny,No),(Hot,Breeze,Cloudy,Yes),(Hot,Strong,Cloudy,Yes)}Calculate the information entropies for the sets first:

The possible values for the wind attribute are None, Breeze, and Strong. Thus, you’ll split the set, S, into the three partitions:

The information entropies of the sets are as follows:

Finally, the third attribute, Sunshine, has two possible values, Cloudy and Sunny. Hence, it splits the set, S, into two sets:

The entropies of the sets are as follows:

IG(S,wind) and IG(S,temperature) are greater than IG(S,sunshine). Both of them are equal; therefore, you can choose any of the attributes to form the three branches; for example, the first one, Temperature. In this case, each of the three branches would have the data samples Scold, Swarm, and Shot. At those branches, you could apply the algorithm further to form the rest of the decision tree. Instead, use the program to complete it:
Input:
source_code/3/chess.csv
Temperature,Wind,Sunshine,Play
Cold,Strong,Cloudy,No
Warm,Strong,Cloudy,No
Warm,None,Sunny,Yes
Hot,None,Sunny,No
Hot,Breeze,Cloudy,Yes
Warm,Breeze,Sunny,Yes
Cold,Breeze,Cloudy,No
Cold,None,Sunny,Yes
Hot,Strong,Cloudy,Yes
Warm,None,Cloudy,Yes
Output:
 Classification
Classification
Now that you have constructed the decision tree, use it to classify a data sample (warm,strong,sunny,?) into one of the two classes in the set {no,yes}.
Start at the root. What value does the temperature attribute have in that instance? Warm, so go to the middle branch. What value does the wind attribute have in that instance? Strong, so the instance would fall into the class No since you have already arrived at the leaf node.
So, your friend would not want to play chess with you in the park, according to the decision tree classification algorithm. Note that the Naive Bayes algorithm stated otherwise. An understanding of the problem is required to choose the best possible method.
If you found this article interesting, you can explore Data Science Algorithms in a Week — Second Edition to build a strong foundation of machine learning algorithms in 7 days. Data Science Algorithms in a Week — Second Edition will help you understand how to choose machine learning algorithms for clustering, classification, and regression and know which is best suited for your problem.
Solving a Problem with Bayes’ Theorem and Decision Tree was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.