Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Advanced Go Panic Programming I do it cause I need to…Prerequisites
I do it cause I need to…Prerequisites
I do it cause I need to…Prerequisites
This article expects you to be already familiar with golang, panic & recover functions and with any other programing language which has exceptions (try-catch) concept.
Introduction
You probably have already seen in “The Little Go Book” something like this:
Go’s preferred way to deal with errors is through return values, not exceptions
And maybe you’ve seen ”CodeReviewComments” page on go wiki, which says:
Don’t use panic for normal error handling. Use error and multiple return values
Also, you may have already seen “Effective Go” article which says:
The usual way to report an error to a caller is to return an error as an extra return value
Also, you may already seen on Dave Cheney’s blog article “Why Go gets exceptions right” which says:
When you panic in Go, you’re freaking out, it’s not someone elses problem, it’s game over man
And it may feels like panic is something that it’s better to avoid in own project….But does it mean that no one use panic?Let’s check it out! Let’s run next command against popular go projects and see whether panic is something that no one using:
grep "panic(" -r --include=*.go . | wc -lResults:
+-------------+-----------------+| name | count of panics |+-------------+-----------------+| go | 4050 || kubernetes | 4087 || gin | 46 || prometheus | 693 || terraform | 1161 || echo | 14 || dep | 157 || gorilla mux | 9 || mysql | 5 || pq | 46 |+-------------+-----------------+
Well…
How to live with it
At first sight, it may feels confusing that documentation, books and articles say don’t use panic but reality is another and we can see panics everywhere…
Hope you will be agree with idea that panic is not something simple to say “use or don’t use”.
So let’s try to dive deeper and clarify where is the boundary between bright and dark sides of panic and why we have such a big number of panics on github and why all books and documentation don’t like panic.
What is panic
Official documentation says:
The panic built-in function stops normal execution of the current goroutine
“PanicAndRecover” wiki page says:
The panic and recover functions behave similarly to exceptions and try/catch in some other languages
And “Go by Example” also says:
A panic typically means something went unexpectedly wrong. Mostly we use it to fail fast on errors that shouldn’t occur during normal operation
Okay… Now it feels that panic is something like exceptions in other languages and it explains a big count of panics in github projects mentioned earlier.
But if you had seen Dave Cheney’s blog article “Why Go gets exceptions right” you may have seen this:
you might imagine that panic is the same as throw, but you’d be wrong
And it means that panic is little bit different from throw exception in other languages and has own advantages and disadvantages.
Advantages
- Like throw exception in other languages stops program execution and unwind the stack to the top-level function call.
- No need to deal with multiple return values, no need to write boring check: if err != nil { // handle error }.As result — code is easier to read.
Disadvantages
- Will stop the program in case you don’t recover.
- When go performs unwind the stack it collects information about whole call stack and it may be slow.
- Function recover returns interface{} and you have to perform type check for obtained value which may be slow (especially in case of reflection). And it’s not like catch certain exception in other languages.
- Function recover won’t stop panic in case of panic in goroutine. And it’s also not traditional way of try-catch like in other languages.
When to use panic
Now it’s clear that panic is sharp* tool, and you have to think twice before using it. And it explains all cautions provided in the introduction section.
Also “Effective Go” says:
One possible counterexample is during initialization: if the library truly cannot set itself up, it might be reasonable to panic
And if you have case when it’s impossible to continue execution due to some circumstances you may stop the program with panic.
One more extra reason to use panic
I believe in case you’re building reach application with sophisticated business logic and layered architecture (moreover, with support domain-driven design) — you have to use panic.You may hate me, but I believe it is the only way don’t drown in errors handling and have clear business logic.
Panic everywhere
First of all, numbers provided in introduction section means that we always have to handle panic (even though we don’t use panic in our code explicitly)because something downstream may panic even language itself may panic, and with purpose avoid program stop we have to have panic handler (recover).It’s also very important in case project has user interface (gets commands/requests from users/other services and provides results/responses) because we always must provide result/response in determined message format even in case of unhandled critical error.So in main.go we have to have something like this:
func main() { defer func() { if r := recover(); r != nil { // handle panic } }() // ...}It’s just simple example, but you may read more about defer-recover here.
Also it’s important admit that you have to have defer-recover in case you’re starting new goroutine otherwise you won’t handle panic from goroutine.You may read more about this in book “Go in Practice” in chapter “Handling errors and panics”, and here I’ll provide most interesting pictures:
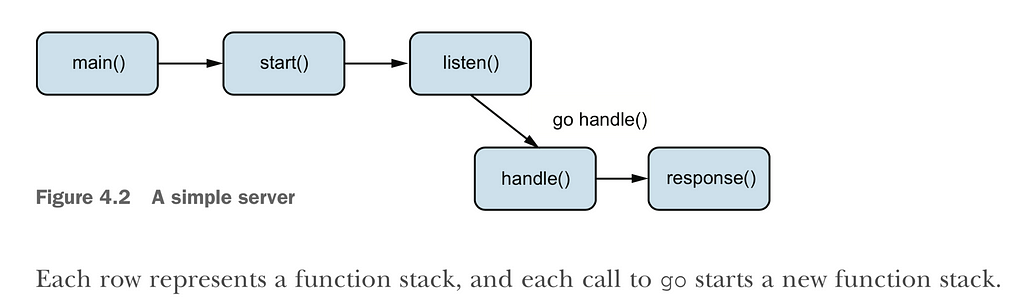 Normal flow.
Normal flow.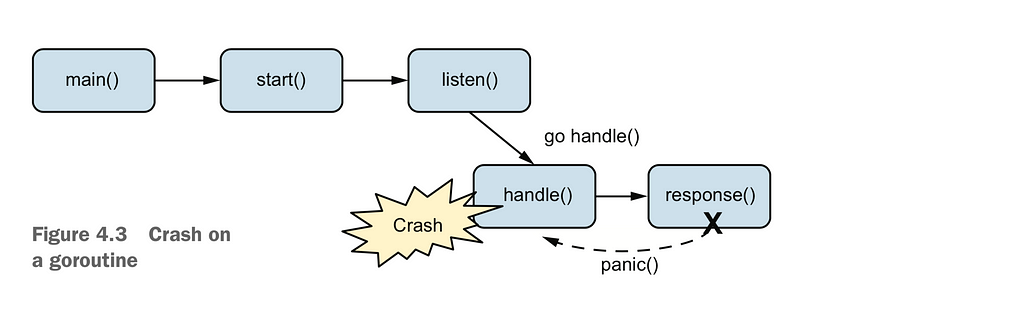 Panic.Syntax sugar
Panic.Syntax sugar
Once you start to use panic more often you also have to perform recover more often and with purpose to do it in little bit pleasant way you may use something like package recover. The main idea under the hood of this package — is just simplify panic recovery and provide an opportunity to perform recovery in next way:
You may find this syntax very similar to the traditional way of catch exception from other languages but the main goal of this approach is simplicity and conciseness, also, it’s easy to read, understand and predict behavior of this code block.
Comparison
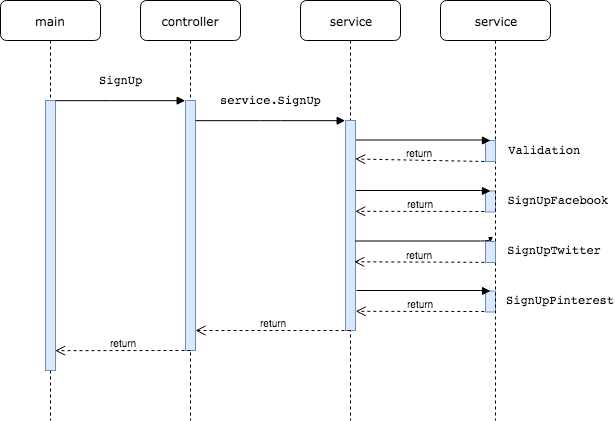
Let’s compare two approaches: 1 — return error, and 2 — panic.For comparison let’s use simple example: suppose we have:1) facade — service which creates a user on facebook, twitter and pinterest.2) controller which calls facade service, checks errors and prints result.Sequence diagram looks like this:
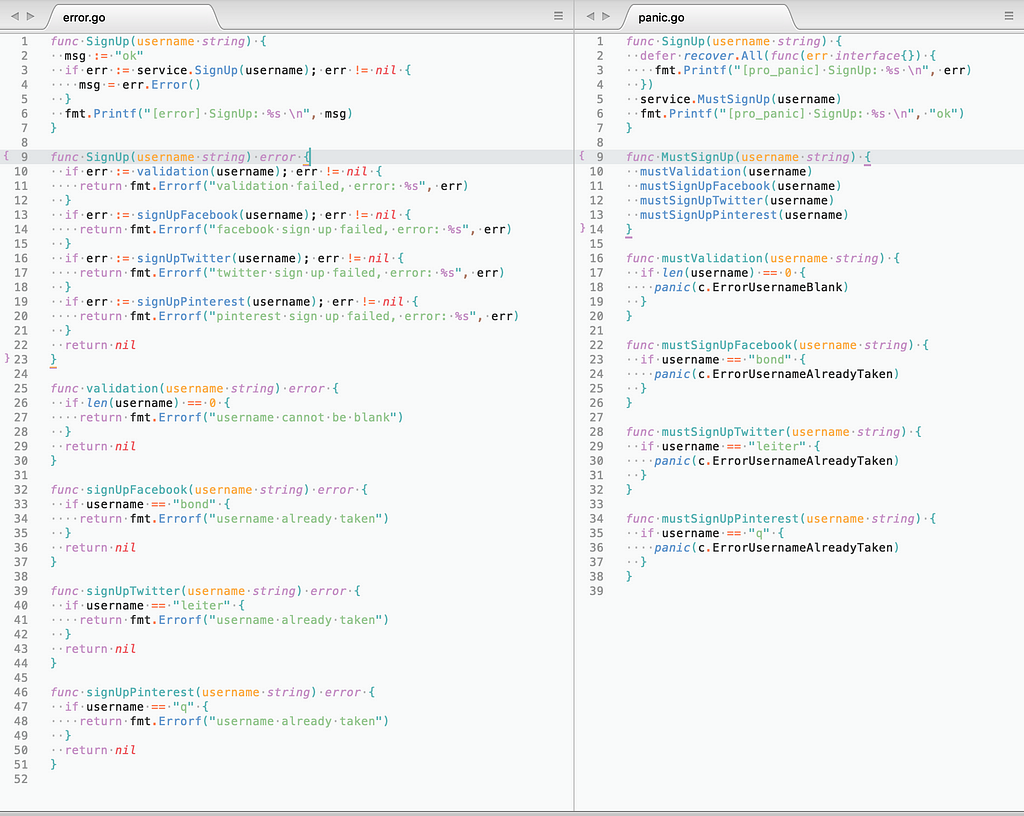
 Implementation #1
Implementation #1
Here you can see super simple functionSignUp in controller, which calls service.SignUp then checks error from service and prints result (everything clear, simple and straightforward).
This code is known to be idiomatic to handle errors in go. And it’s great!
But when it comes to service — here you can find lot of repetitive code and it feels like something is going wrong…
(You can find source code here).
Implementation #2
Here you can see the same functionSignUp in controller, which calls service.MustSignUp then performs recover (by recover package) and prints result (same flow).And if you take a look to service you may find that now it looks way shorter and simpler and it’s easier to read and understand such business logic.
But this code is known to be prohibited in go due to reasons specified earlier…
(You can find source code here).
Is it really bad
Technically both implementations equal and provide same functionality, same errors and same results (you can check it out here).But regarding amount of code — it’s obvious that 2nd one is simpler, you can see it on next picture:
Also, 1st implementation doesn’t have recover but it should because every user-friendly project has to have recover and it means that 1st implementation will have even more code.
Is it slow
Perform benchmarking on such small examples may looks silly but anyway let’s see how it looks and figure out whether we have skewed numbers:
+---------------------------------+----------+----------+| case | imp. #1 | imp. #2 |+---------------------------------+----------+----------+| error: username cannot be blank | 53000 ns | 45000 ns || error: username already taken | 51000 ns | 46000 ns || ok | 32000 ns | 34000 ns |+---------------------------------+----------+----------+
Looks like in case of error — panic faster but in success case — recover takes some overhead…Please pay attention, all provided numbers represent time in nanoseconds,and it means: for this particular case we don’t have a big difference between both approaches…
(You can find source code related to this benchmarking here).
Go 2 draft
You probably already know that in go 2 error handling will be improved with check-handle combination (if not — please take a look) and it will simplify everything in really elegant way!But will it help to build sophisticated layered applications?And the answer is yes for pretty simple applications like in our case (controller-service) but unfortunately for big applications and especially for applications with support domain-driven design check-handle won't help,and I believe you will still have to use panic…
Conclusion
The point of this article is to show that panic it’s just a tool and you don’t have to afraid this tool, you have to know when and how to use panic…And once you know advantages and disadvantages of this tool you may leverage whether use it or not.
PS
You can find demo project here with layered architecture (not DDD but many layers) which is build with the idea of panic everywhere, maybe it will be illustrative.
Also, you can find more examples of using both approaches errors vs panic here.
In case you don’t like panic you may find another approach how to simplify error handling in another way.
Panic like a PRO was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.