Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
In a previous post, we have discussed some of the features of MapR-DB that make this distributed database especially interesting. In this post, we intend to continue that effort by presenting a specific use case.
The Problem
The problem to be solved can be described as follows.
A serie of message are coming through a stream. Each value has an idand a count. For eachid, we must update the existing count in the data base by incrementing its value using the count coming in the stream.
The following image shows an example of the problem.
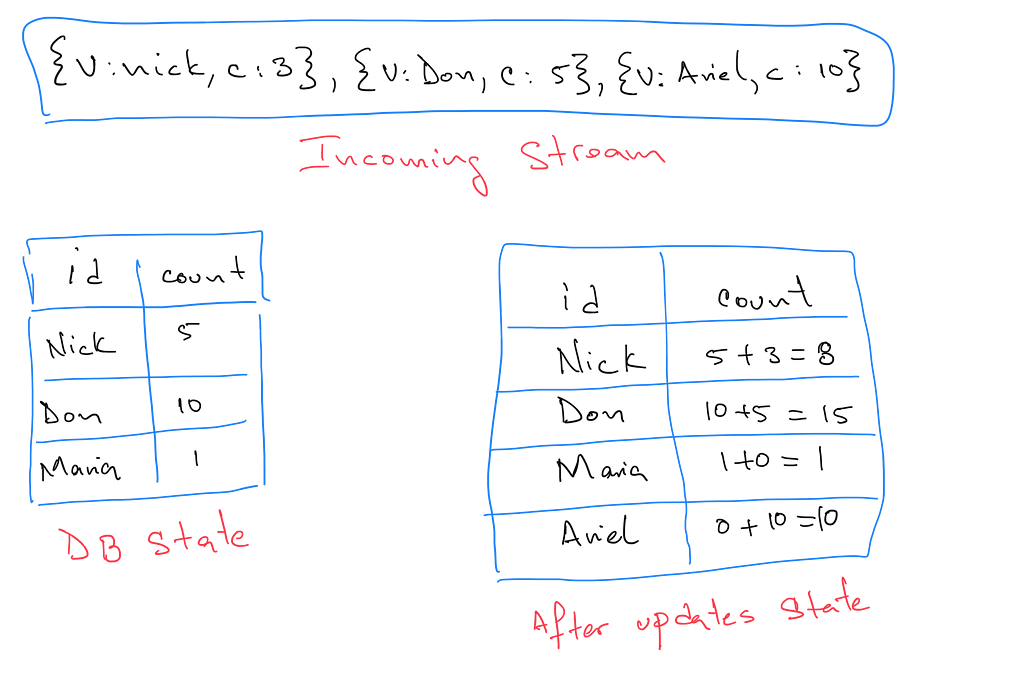 The problem in an image.
The problem in an image.
There are various ways to solve this problem. One could be by reading the current state of a given idstored on the database, then update its count using the values on the stream to finally save the updated values back to the database.
Let’s see this process in details.
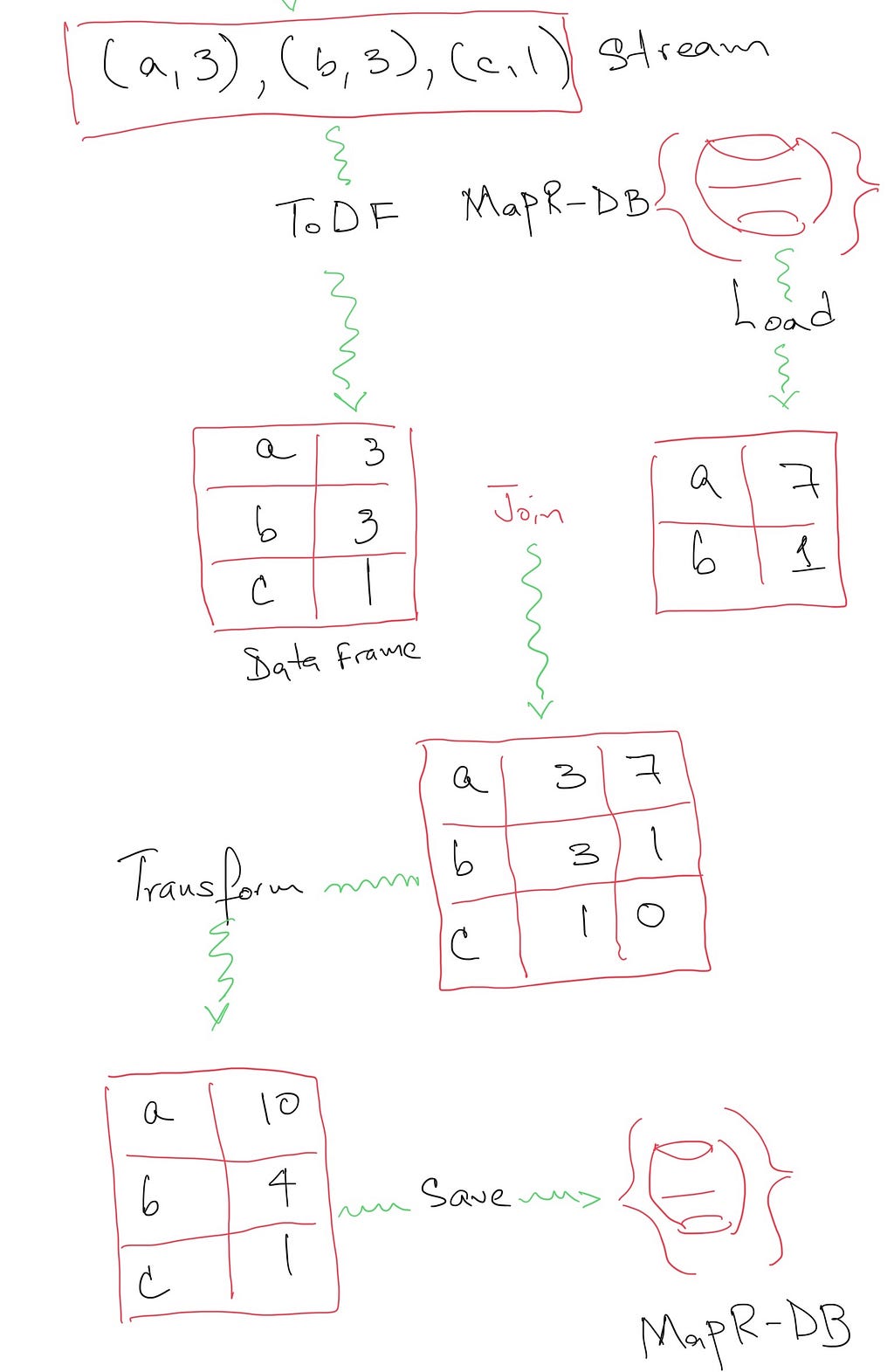 Loading, merging, and saving.
Loading, merging, and saving.
As we can see in the image above, in order to update the state in the database, we need to load every piece of data first from it, join the value with the incoming stream to calculate the new state, and finally, save the new state back to persistent storage. In general, we will have to follow this same process regardless of the database technology we choose to use, whether it is MapR-DB or any other persistent technology.
The following code shows how we could implement this idea using Apache Spark integrated with MapR-ES (MapR Streams technology) and MapR-DB.
It is important to notice that on every streaming slide, we load from MapR-DB (or any other Db for this matter) and merge the loaded data frame with the stream. Then we save the current, recently calculated, new state back to the database.
This process makes total sense, and in most databases out there, there is no way around it. However, these operations are costly to execute every time we receive data on the stream.
MapR-DB Mutations
When others fall shorts, MapR-DB shines.
MapR-DB is able to incrementally update documents without the need of loading them first. More specifically, it is possible to update only some of the fields of a document without touching anything else at the document level.
A reasonable question that quickly raises is: Are this updates atomically applied given the distributed nature of MapR-DB? The answer is YES.
Let’s first write some code to prove the last statement and then we will move to solve the problem in question using this concept.
We can start with the following code snippet.
As we can see, the run function will increment the countfor a given id, specifically, times times.
Based on this code, we can create another function that does the same in parallel by creating a number of threads and execute UpdateSameId.run on each thread.
We can run the above code in the following way.
This will print out the final state of each document on MapR-DB, and by that, we can certainly say that updates are atomically applied.
The entire code is part of the Reactor project that you can find here.
As we can see, even when running on a multi-thread or multi-processor environment, MapR-DB guarantees that values are consistently (atomic) update. We could write similar code using Apache Spark in order to increase parallelism, but the results will be the same; we tried it out.
Based on these findings, we could improve our original app to solve the problem we first stated.
Let’s start by removing the parts that first load from MapR-DB and replace them by updates instead.
Let’s review a few important changes from our original app.
First, there is no need to load the current state from the database at all. We, instead, create the necessary mutations and apply them in parallel to MapR-DB.
Secondly, we have significantly reduced the number of tasks that Spark has to execute, increasing the overall performance and while reducing the load in our database.
Thirdly, the code is simpler, more elegant and easy to understand, increasing the maintainable indexes while making other people life easier.
Finally, we are creating a connection per partition so we avoid any Spark serialization issue while increasing parallelism since each partition operations will be run at the same time (Spark magic at work here).
After the process runs, we can rest assured that our data will be correctly and efficiently updated by our latest approach.
Conclusions
As discussed before, MapR-DB is a non-SQL database with very interesting features that are worth exploring. These features not only put it on top of the pick for highly performant and distributed workloads but also make our lives easier as problem solvers. Even though the intrinsic distributed nature of MapR-DB, we can abstract ourselves from many of the issues that complex systems like this one has and use MapR-DB with easiness to solve the most complicated business problems in the market.
Please, read Interacting with MapR-DB for a more comprehensive view about how to use MapR-DB and the tooling around it.
MapR-DB Atomic Document Updates was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.