Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Node.js, one of the popular programming languages for a web software engineer, has a drawback — by default it only runs on a single thread. By using a single thread, Node.js runs the code by using a terminology called Event Loop.
To understand how event loop works, I encourage you to read this official documentation. This terminology is essential to understand the performance issue in Node.JS.
The Node.js Event Loop, Timers, and process.nextTick() | Node.js
To give you a quick summary of how Event Loop works in Node.js, we could refer to this diagram below,

If you look at this diagram, an issue could appear when you need to “pause and wait until all of this stuff is completed”. On this step, there are two kinds of output. First, the process is successfully executed and continue to the next step. Second, it gets stuck. When an unprocessable entity occurs, there would be a bunch of unhandled requests that lining up. In Node.js terminology, we call it as blocked.
This is a disaster for the Node.js developer because of 3 reasons. First, the stuck request could not be completed. Second, there would be a bunch of incoming requests that need to be handled. Third and the worst, your system would be force stopped because of overload.
 Source: Diner Dash!
Source: Diner Dash!
To give you a different perspective, we can imagine a restaurant that was run by a single waiter. He could serve every single customer — flawlessly, especially if he already has a bunch of experience in this field. However, this kind of experience will not be useful when he needs to serve a customer that asks something your chef could not serve, and they neither have a solution nor able to leave this customer.
Node is fast when the work associated with each client at any given time is ‘small’ .
— Node.js Official Documentation
Internally, Node.js library divides into two type of dependencies — V8 and libuv. V8 is a library that was used to run Javascript code outside the browser, including the Event Loop. On the other hand, libuv is a C++ open source library that offers a Worker Pool to handle an expensive process by providing access to the operating system underlying file system, such as file I/O, networking, and some aspects of concurrency as well.
I encourage you to read the blog below to learn more about Event Loop and Worker Pool.
Don't Block the Event Loop (or the Worker Pool) | Node.js
Event Loop and Worker Pool have their own method to maintain queues for pending events and pending tasks. Both of it could run simultaneously. In order to understand this phenomenon, you could copy and paste the code below and run it by yourself.
As we see from the code below, programmatically, the code runs from top-to-bottom, but the output shows in this order:
HTTP Request: 958Hash: 1012File system: 1013Hash: 1051Hash: 1061Hash: 1581
Whenever you run it again and again, it would show a similar order with different timelapse. Even though the hash function was run after the fs.readFile function, the first hash function would return the output first. To demystify it, we could refer to this diagram below.
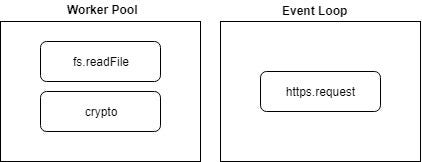
fs and crypto modules were run by Worker Pool while https module was run by Event Loop. Because the https was run by a different method, it would be done as soon the request has completely executed. Hence, it would return the output first even though it was initialized in the middle.
On the other hand, even though the fs module is being called before the hash function, the first hash function will give an output first and then follow by the fs output. This happens because there is a gap between Node.js and file accessing method on the fs module. To demystify it, I visualize this explanation by using this graph:
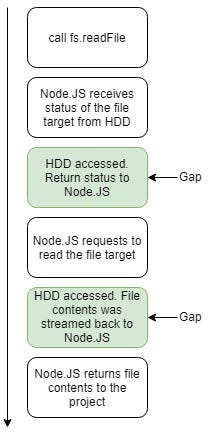
By referring to the explanation on this graph, there are two gaps, and it occurs whenever the Node.js needs to get a response from the HDD. Hence, Node.js put the following entity process into pending and allocate the current thread into the next task, which is the hash function. After it finishes and returns the output, it continues the fs.readFile process until it meets another gap or the process is finished.
The behaviour of Worker Pool depends on the total number of available thread on the environment. We could customize the total thread that we want to use to take advantage of the multi-core system. There are two basic approaches. First, we configure the thread pool size on the project environment by hand. Second, we configure the thread pool size based on the total number of cores in the project. Try to run the code below on your local system and see the behaviour of each approach.
There are several additional resources that I would like to recommend for the in-depth explanation:
- Cluster | Node.js v11.1.0 Documentation
- Libuv thread pool UV_THREADPOOL_SIZE in a node cluser setup · Issue #22468 · nodejs/node
To give you another perspective about how the worker pool works, we use the diagram below to visualize it.
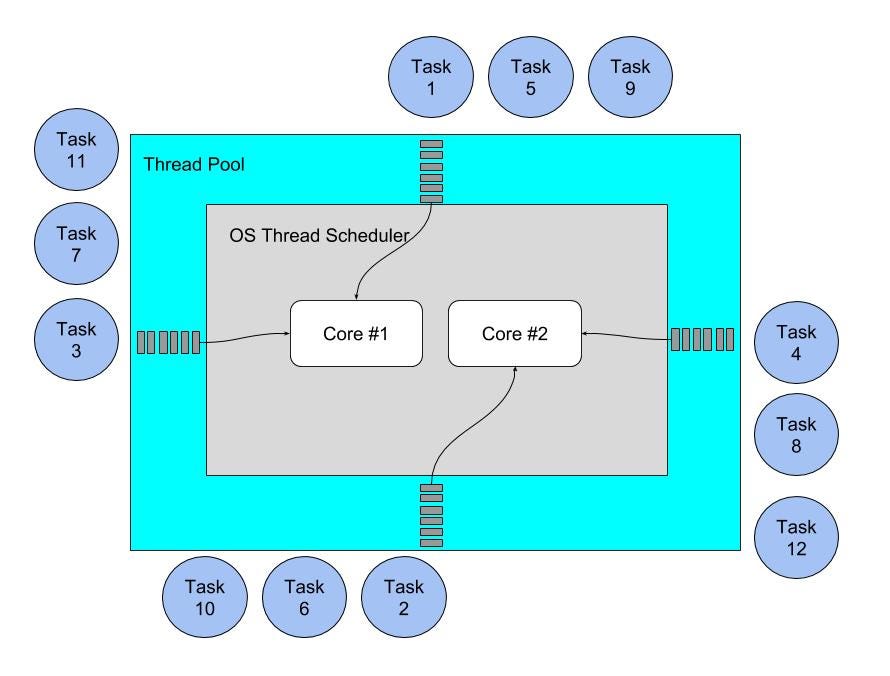
Assume that the local environment has two cores and fork four threads. We could assume that the thread as a bridge to across the thread pool. This bridge only could be crossed by a single task, one-by-one. After that, each task would go to the specific core that processes it simultaneously.
P.S. — The more thread pool that you open up doesn’t mean that it would give a better overall performance
There is a trade-off between the thread pool size and the overall performance. By opening up a lot of thread pools, it means that the Node.js system could handle a lot of tasks simultaneously. However, it also means that the core CPU also need to divide their resources as much as the thread pool size.
On the other hand, using a single thread does not mean that we could maximize the output by focusing on the single request at one time. If we use this approach, we do not use the multi-threading technology that available on most of the current CPUs.
The best practice of clustering in Node.js is by setting the thread pool size based on the total number of CPU in your system.
Here is a comparison that I created based on the benchmark result with a tool called, Autocannon. Here are the code and the outputs
Number of concurrenct connection: 10Total request: 100
1 Thread PoolsStat 2.5% 50% 97.5% 99% Avg Stdev MaxLatency 1900 ms 2319 ms 4750 ms 4766 ms 2678.45 ms 879.03 ms 5099.76 ms100 requests in 35.41s, 21.2 kB read
2 Thread PoolsStat 2.5% 50% 97.5% 99% Avg Stdev MaxLatency 2011 ms 2347 ms 4577 ms 4791 ms 2667.16 ms 821.03 ms 4899.43 ms100 requests in 33.53s, 21.2 kB read
4 Thread PoolsStat 2.5% 50% 97.5% 99% Avg Stdev MaxLatency 1880 ms 2158 ms 4803 ms 4950 ms 2607.7 ms 869.76 ms 4987.97 ms100 requests in 33.69s, 21.2 kB read
Based on total number of CPUs - 8 Thread PoolsStat 2.5% 50% 97.5% 99% Avg Stdev MaxLatency 1870 ms 2201 ms 4556 ms 4562 ms 2556.11 ms 819.97 ms 4620.44 ms100 requests in 33.54s, 21.2 kB read
I also provide my Github repo that contains most code that I use to play around multi-threading in Node.js
weisurya/node-multithread-playground
Surya is a Back-end Engineer in his professional life and a Technology Evangelist in his personal life. This year, he builds a resolution, called “Road to Becoming an Applied AI Scientist”. If you are interested, or want to follow his progress, you can visit him at his personal website, soensurya.com, or on LinkedIn.
Demystify The Multi-threading in Node.JS was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.