Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.

Introduction
“My AI will seek to collaborate with people for the greater good, rather than usurp the human role and supplant them” — from the Hippocratic oath on artificial intelligence by Oren Etzioni [1]
Artificial Intelligence (AI) is currently one of the most hotly debated topics in technology with seemingly every business leader and computer scientist voicing an extreme opinion on the topic. Elon Musk, Bill Gates, and Stephen Hawking are all pessimists who have posited that AI poses an existential threat to humanity. Musk even publicly states that, “AI is far more dangerous than nukes” [2]. Famed futurist and technologist Ray Kurzweil, who studied under the inventor of the AI field, has a more optimistic outlook, “My view is not that AI is going to displace us. It’s going to enhance us. It does already” [3]. Billionaire Mark Cuban has said that AI will produce the world’s first trillionaire.
All these brilliant minds have caused an intense public interest in the field, but what many people may not realize is that the field of AI is more than 60 years old and that there have been a couple of hype cycles throughout its relatively short history. Periods marked by intense investment and euphoric speculation followed by disappointment, disillusionment, and precipitous declines in funding.
Although it’s right to be cautious about any life altering technology, AI in its current state is already changing every industry including even the ones most resistant to change such as healthcare. Already AI can diagnose diseases such as diabetic retinopathy with just as good or better accuracy than board certified ophthalmologists [4]. The fields of radiology, dermatology, and pathology which require doctors to eyeball images and make decisions based on what they see can all be very easily replaced by algorithms that do the work faster and more accurately. Startup companies as well as big international tech conglomerates (think Google, Apple, and IBM) are spending huge amounts of money to collect enormous healthcare data sets which can be used to train disease detection algorithms. This paper will take a closer look into the intersection between healthcare diagnostics and AI. We will discuss the most commonly used AI techniques in medical diagnostics, the history of AI, the current AI platforms that have received FDA approval, how the FDA is preparing for a tsunami of AI software products, future AI projects in the pipeline, and the obstacles that lay ahead of the AI healthcare revolution.
How Do Researchers Use AI? ELI5.
“Big data is like teenage sex: everyone talks about it, nobody really knows how to do it, everyone thinks everyone else is doing it, so everyone claims they are doing it.” — Dan Ariely [5]
Actually using AI techniques requires a basic understanding of calculus, probability, and linear algebra. We will skip the math and instead describe the tools of machine learning (ML) and natural language processing (NLP) using plain English. Both ML and NLP are subsets of AI and are currently the most commonly used tools [6]. ML in medicine has become extremely popular in the past few years because of the exponentially increasing amounts of data that is being generated and recorded in digital format aka “big data”. All this data needs to be analyzed and that’s where ML comes in, because it can be used to learn about patterns in the data and make predictions. Broadly speaking ML can be separated into unsupervised and supervised learning.
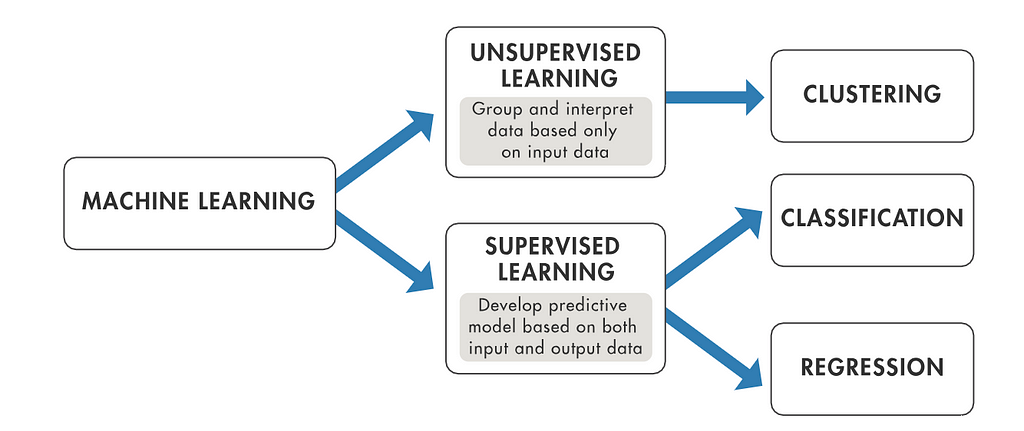 Image from Mathworks.com
Image from Mathworks.com
Unsupervised learning uses unlabeled data and can be a good way to find and group data based on similarities. For example if you have scans of chest x rays, you could then use unsupervised learning to divide the data into x rays that resemble pneumonia vs those that resemble a collapsed lung (pneumothorax), vs those that resemble congestive heart failure. You would NOT provide labeled chest x rays with the model, however in supervised learning you WOULD provide labels.
In terms of healthcare, supervised learning is more commonly used. Supervised learning comes in multiple different flavors including linear regression, logistic regression, naïve Bayes, decision tree, nearest neighbor, random forest, discriminant analysis, support vector machine (SVM) and neural networks (NNs). By far the most commonly used supervised learning techniques in medicine are SVM and NNs [7]. SVM is very simply used to separate subjects into 2 different categories given a set of traits. For example, for the disease pneumonia there could be a number of disease traits including cough, fever, and difficulty breathing. Each of these traits would be weighted differently depending on how much each of these individual traits is statistically associated with the disease. If the weighted average of these 3 traits is above a critical level the patient is diagnosed with pneumonia. If below the critical level then they do NOT have pneumonia.
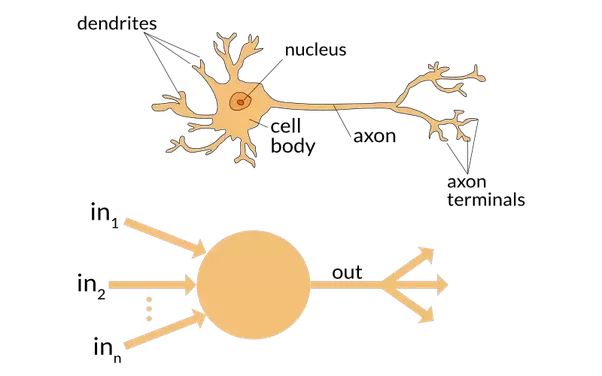
NNs are the second most commonly used form of supervised learning in medicine and were originally inspired by the structure of neurons. NN’s use an input layer, a middle hidden layer(s), and an output layer. The input layer is the equivalent of the dendrites and the output layer is the equivalent of the axon which carries the signal. When a NN is first being trained all the weights and the threshold values are set to random values. The weights and thresholds in the hidden layer are randomly adjusted a bunch of different times until the input layer data consistently produces the labeled output layer data. Put very crudely it’s a way to get from input to output by trying a lot of different things in the middle to see what works best.
If you have a model that has a LOT of separate hidden layers (layers between the input and output) then this is called deep learning, which has also become very popular recently. The number of papers in medical research that mentioned deep learning doubled just from 2015 to 2016 [6]. Deep learning is especially popular with diagnostic imaging analysis. While ML and deep learning are excellent tools for these types of imaging studies, the use of NLP is also often necessary given that so much clinical information is stored as text. NLP can be used to process text and then classify keywords associated with diseases [8]. With a basic understanding of the most commonly used AI tools in medicine, we will now look back at the history of AI.
A History of Booms and Busts
“The excitement of making something, that’s the spark of God” — Childish Gambino [9]
 The Mechanical Turk
The Mechanical Turk
Like any good origin story, the history of AI can perhaps be traced back to the world’s most infamous hoax. In 1769 a humble thirty-five-year-old civil servant named Wolfgang von Kempelen created the Mechanical Turk — a chess playing machine designed to amuse Austrian empress Maria Theresa [9]. The machine was created to look like a life sized human head and torso wearing Ottoman robes and a turban that could play a mean game of chess. The Mechanical Turk received significant fame during its time and even managed to beat Napoleon Bonaparte and Benjamin Franklin during its tour. The European and American public were fascinated by how the machine could play chess so well on its own, yet little did they realize that underneath the cabinet of the machine there was an actual human chess champion making masterful moves. Fast forward to the early 20th century and two visionary computer scientists, who had never met, were simultaneously dreaming of intelligent machines: the British Alan Turing and the German Konrad Zuse.
In 1936 Turing proposed an idealized computational device called a Turing machine and in 1950 he went several steps further and proposed the famous Turing Test, which simplistically posits that the test will be satisfied when a human cannot tell the difference between talking to a computer vs another human [10, 11]. In essence talking to a computer is indistinguishable from talking to a human. Tragically after Turing created his famous Turing Test he was persecuted by the British Government for being gay and he committed suicide a few years later. The other man Konrad Zuse was equally ahead of his time if not more so. In 1941 Zuse created the first functionally programmable computer called the Z3. As early as 1943 he was daydreaming of whether intelligent machines could be created to play chess. In 1945 he created the world’s first higher level programming language called Plankalkuel which he used to design the world’s first chess program. If that wasn’t enough the year after that he created the world’s first computer startup company and even managed to convince investors to back his venture [12]. Talk about a man with conviction. These two men were perhaps the most famous progenitors of computing science preceding the official birth of AI in the 1950’s.
 Konrad Zuse: computer pioneer
Konrad Zuse: computer pioneer
In the winter of 1955 a group of scientists including Allen Newell, Cliff Shaw, and Herbert Simon proposed the Logic Theorist, which entailed using machines to prove mathematical theorems from the Principia Mathematica [13]. The proposal received funding from the RAND corporation. As a major foreshadowing event even so early on in AI history, one of the theorems was proven more elegantly using the machines than the one produced by the actual authors, which astounded Bertrand Russell, one of the key authors of the Principia Mathematica. [14] The discoveries were presented at a key conference called the Dartmouth Summer Research Project on Artificial Intelligence (DRPAI) organized by John McCarthy and Marvin Minsky in the summer of 1956. The idea behind the conference was to collect the 10 foremost experts on the topic at hand and have them elucidate “every aspect of learning or any other feature of intelligence [that] can in principle be so precisely described that a machine can be made to simulate it.” [15] These are the exact words that they submitted to the Rockefeller Foundation, which led to them securing $7,500. The field of AI was born at a fun little summer conference bankrolled by one of the richest families in America. And thus it began.

Since that faithful conference about 60 years ago we have had at least 3 AI booms, marked by increased public attention and funding, of which we are now in the third. In between these booms are what historians refer to as AI winters, in which the overly optimistic predictions made by scientists fell short and investors tightened their purse strings. To give you an example of the way these cycles work consider Herbert Simon (aforementioned creator of the Logic Theorist) who publicly predicted in 1957 that in within a decade a computer would be able to beat the world chess champion [16]. He was off by 30 years when IBM’s Deep Blue famously defeated Garry Kasparov. Still such optimistic predictions made by well-respected public scientists fueled investment dollars, but when the promises/predictions were not seen to come to fruition the public and investors grew disheartened.
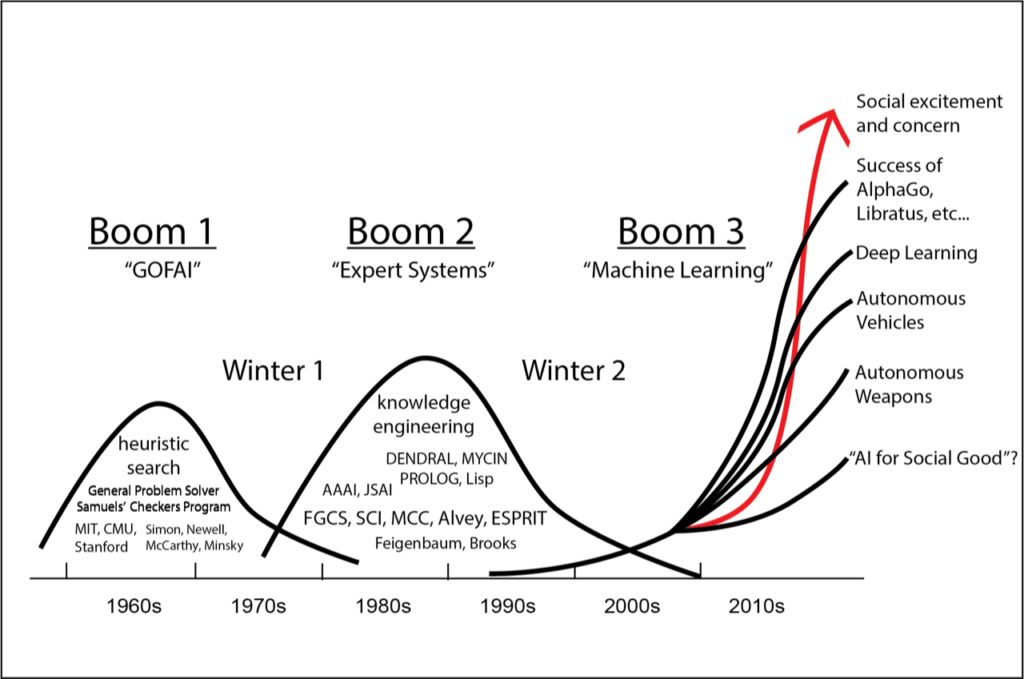
During the first boom, which took place roughly between 1957 to 1974, machine learning methods improved significantly as well as the computational ability of computers while costs dropped. In the early 1950’s only the most prestigious universities had access to computers and they were super expensive costing upwards of $200,000/month [17]. But as the years progressed computers became more powerful and cheaper thanks to Moore’s Law. This trend opened up the doors for more people to get involved. The first boom brought such innovations as the General Problem Solver, Arthur Samuel’s Checkers Program, the OG general purpose robot SHAKEY, and the primitive chatbot ELIZA which ran a program called DOCTOR that used NLP to simulate a psychotherapist. (18) These initial successes were so inspirational that the Defense Advanced Research Projects Agency (DARPA) agreed to plow large amounts of capital into AI research at several US universities. Along with the piles of money and euphoric optimism also came fear that AI would lead to mass unemployment. President Kennedy remarked that unemployment caused by technology was one of the major challenges of the 1960’s. (19) From 1953 to 1964 more than 800 publications discussed the role of technology in eliminating jobs [20]. In 1964 President Johnson created a special committee to discuss the growing public fear of AI and technology displacing jobs [21]. Perhaps at the peak of boom 1 mania in 1970 Marvin Minsky told Life Magazine, “[in] three to eight years we will have a machine with the general intelligence of an average human being.” He was off the mark considering that today we are still working on fulfilling that goal. After being promised so much by celebrity scientists and having drunk so much of the initial AI Kool-Aid, DARPA finally sobered up and cut funding leading to the first AI winter (1974–1980). But the 2nd boom showed signs of life as early as 1980 [23].
Boom 2 was remarkable in the amount of tenacity/ingenuity it took key researchers such as Edward Feigenbaum, who studied under Herbert Simon, to wipe the frost off the face of AI. Feigenbaum’s scientific contribution to the field was a radical new paradigm called expert systems in which AI was trained to be a narrow problem solver in a specific domain of interest such as medicine [24]. Feigenbaum was brilliant and shrewd. Early on he realized that if he was going to bring AI out of the winter he would need to get boatloads of funding into the field, but that he wasn’t going to do it by making outlandishly optimistic prognostications. Instead he would need to use fear as a motivator. During the late 1970’s Japan’s economy was booming and there was a fear amongst the American public that Japan would surpass the US as an economic superpower. Japan was also working on a project called the Fifth Generation Computer System (FGCS) which the Japanese Ministry of International Trade had dumped half a billion dollars into. The FGCS was designed to be a massively parallel supercomputer which could be used to develop expert system artificial intelligence [25]. At the Japanese premier of FGCS in 1981, Feigenbaum was invited to give a keynote address. In the speech he praised the project and Japan’s ingenuity. As soon as he got back to America he visited computer science departments across the country and spearheaded a campaign to raise fear about Japan beating the US in AI development [26]. The US government took notice. Months later DARPA funded a billion-dollar proposal called the Strategic Computing Initiative (SCI) to crush Japan in AI development. Feigenbaum’s plan worked, but it went further than he imagined. The SCI inspired the development of the $1.5 billion European Strategic Programme on Research in Information Technology, and the $500 million Alvey project in the UK [27]. In an effort to bring AI out of the winter Feigenbaum and his contemporaries had sparked an international arms race leading to the 2nd AI boom.
 From Professor Jim Warren
From Professor Jim Warren
The expert systems domain characterizing the 2nd AI boom was especially important in catalyzing innovation in healthcare. In a Stanford paper Feigenbaum described some of the exciting and pioneering applications including MYCIN, VM, PUFF, INTERNIST, and CADUCEUS [28]. MYCIN used AI to diagnose bacteremia and to then recommend the appropriate antibiotic with the correct dosage based on body weight. MYCIN (named after the suffix of common antibiotics i.e. — erythroMYCIN) was never actually used in hospitals due to the lack of computer infrastructure in clinical settings back then. It was however put to test theoretically at Stanford and ended up performing superior to physicians [29]. VM provided real time advice to clinicians about ventilation management settings for critically ill patients who were intubated in the ICU. For example, if a patient showed improved breathing function and could be weaned off the ventilator slowly VM could suggest that course of action to the attending doc. PUFF was created to interpret pulmonary function parameters such as lung volume, flow rates, and diffusion capacity. The program used these measurements in concert with a diagnosis from the referring doctor and knowledge of common obstructive/restrictive lung pathology to diagnose the patient. The system was also automated to create a report that doctors could read and sign. Even as early as 1980, the reports generated at the Pacific Medical Center by PUFF were signed by 85% of doctors without any necessary editing. INTERNIST was a very ambitious program that even by today’s standards was way ahead of its time. INTERNIST, as one could guess from the name provided differential diagnoses in the field of internal medicine. It had knowledge of close to 500 different pathologies. Writing about INTERNIST in 1980 Feigenbaum wrote,
“Because INTERNIST is intended to serve a consulting role in medical diagnosis, it has been challenged with a wide variety of difficult clinical problems: cases published in the medical journals, clinical conferences and other interesting and unusual problems arising in the local teaching hospitals. In the great majority of these test cases, the problem formation strategy of INTERNIST has proved to be effective in sorting out the pieces of the puzzle and coming to a correct diagnosis, involving in some cases as many as a dozen disease entities” [30]
Although INTERNIST was incredibly promising it was far from perfect. Subsequent papers put out by the team who originally created INTERNIST (computer scientist Harry Pople and internist Dr. Jack Myers) showed that the system was not robust enough for regular clinical decision making due to a host of frequent errors so they addressed these errors on the next iteration [31]. CADUCEUS was basically version 2 of INTERNIST-1. It’s estimated that CADUCEUS had working knowledge of more than 500 different disease processes and 3,400 specific disease characteristics [32]. CADUCEUS also improved upon INTERNIST-1 by giving explanations on how it came to its conclusions. At the height of AI boom 2 in 1986 CADUCEUS was described as the “most knowledge-intensive expert system in existence” [33]. Certainly, these were exciting times for the expert systems AI enthusiasts, however good times don’t last forever.
These large expert systems of knowledge were expensive, difficult to keep updated, and cumbersome to use by everyday medical professionals. Disappointed by the progress that had been made in the actual use of AI, the SCI and DARPA cut funding to AI projects aggressively in the late 1980’s [34]. The Japanese economy started to collapse in the early 1990’s leading to a global AI bust in which all the major AI funding from international government organizations froze. These were hard times for AI as VC funding dwindled and academics were even embarrassed to be associated with the field. The 2nd AI winter which historians date from 1987 to 1993 may have not been well funded or respected but important research activity still took place and by the early 1990’s it looked like the frost was again thawing. Optimism was rekindled by developments in powerful new AI techniques such as multiple layer neural networks and genetic algorithms in concert with more powerful computers.
The pace of AI started to increase in 1993 but really took off in earnest when IBM Deep Blue made history on May 11th 1997. In a highly publicized multiple day televised chess match between IBM Deep Blue and the reigning chess champion Garry Kasparov, Deep Blue triumphed. Finally the great promises made by the earliest AI pioneers were coming true. It’s estimated that the 1997 Deep Blue was able to calculate 200,000,000 possible chess positions per second [35]. From that year to the present we have seen an exponential increase in the rate of breakthroughs and breathtaking AI discoveries. In February 2011, Watson played against the reigning kings of Jeopardy, Ken Jennings and Brad Rutter. In a televised spectacle Watson clearly beat them both, which stunned audience members as well as computer scientists [36]. In March 2016, AlphaGo (created by Google AI subsidiary DeepMind) played the 18-time world champion of Go, South Korean Lee Se-dol. Lee Se-dol has been called the Roger Federer of Go and is a legend in South Korea.
 AlphaGo v. Lee Se-Dol
AlphaGo v. Lee Se-Dol
Go is an ancient incredibly complex game that has more possible move combinations that there are number of atoms in the universe. It is considered the hardest board game invented in history. Because Go is so complex experts believe it requires human intuition [37]. The researchers trained AlphaGo using deep neural nets on a data set of 100,000 examples of humans playing the game. After that they went one step further and programmed the machine to play millions of games against itself. Through reinforcement learning AlphaGo learned the best possible moves to make by playing itself. It’s estimated that 80 million people worldwide watched the first game between Lee Se-dol and AlphaGo [38]. At the beginning of the 5 game tournament Lee Se-dol remarked that he expected to beat the machine all 5 times. During game 1 Lee Se-dol was caught off guard and was easily defeated. Game 2 was much closer. It was a slower more deliberate game. On move 37 something interesting happened. AlphaGo made a move that baffled experts who were commentating on the game. The machine made a move no human would make. In fact, when the programmers looked at the probabilities there was only a 1/10,000 chance that a human would make that move and yet AlphaGo decided to go for it anyway. Move 37 has been called “beautiful” by professional players. Eventually Lee Se-dol resigned as he realized there was no way to win. He was crushed. AlphaGo beat him on the third game as well and ended up winning the championship. It was the first time in history that the best Go player in the world was a computer.

But that’s not the end of the story. There were after all still 2 more games to be played. During the 4th game Lee Se-dol was much more relaxed. Everyone in the audience wanted him to win so badly because they had seen the despair on his face and felt it the days before. This is a man who had dedicated his entire life to the game. On move 78 Lee Se-dol made a move that stunned professional players. The computer calculated that there was a 1/10,000 chance that a human could have made that move. Later Lee Se-dol remarked that it was the “only” move he could make. The computer tried it’s best but lost. AlphaGo resigned after it realized there was no way it could win. Move 78 is now known as the “hand of god” in the professional Go community. The crowd was happy that humanity had a chance against the machines. But wait there’s still more. In the 5th and final game AlphaGo invented a new way of playing the game. In a documentary called AlphaGo on the match, it shows the DeepMind crew backstage thinking that there was a bug in the software that was causing it make all these weird moves. Even the professional onlookers thought that there was a possible malfunction with the software. As the game progressed, however, the professionals realized this was a new way to play the game and Lee Se-dol was forced into resigning after realizing he had lost [39]. The machine had taught the master a new way to play the game. Google is now using DeepMind’s technology to not just play board games but also to advance the field of healthcare and save lives [40].
AI is Disrupting Every Industry Including Healthcare
“AI is the new electricity” — Andrew Ng [41]
Interwoven in the AI booms is an interest in not just theoretically making machine intelligence approach that of humans but to use the technology to improve society. One industry that is in desperate need of help is healthcare. These efforts started as early as using INTERNIST-1 and CADUCEUS to make medical diagnosis during the 2nd AI boom. AI applications in the healthcare field are essentially limitless, however, much of the key work requires computer scientists to closely collaborate with physicians, hospitals, and perhaps most crucially the FDA. To date there have been only a handful of AIM (AI in medicine) companies in the US that have finished FDA trials to actually use their platforms in hospitals. We will discuss the 3 that have received the most attention as of now: Arterys, Viz.AI, and IDx.
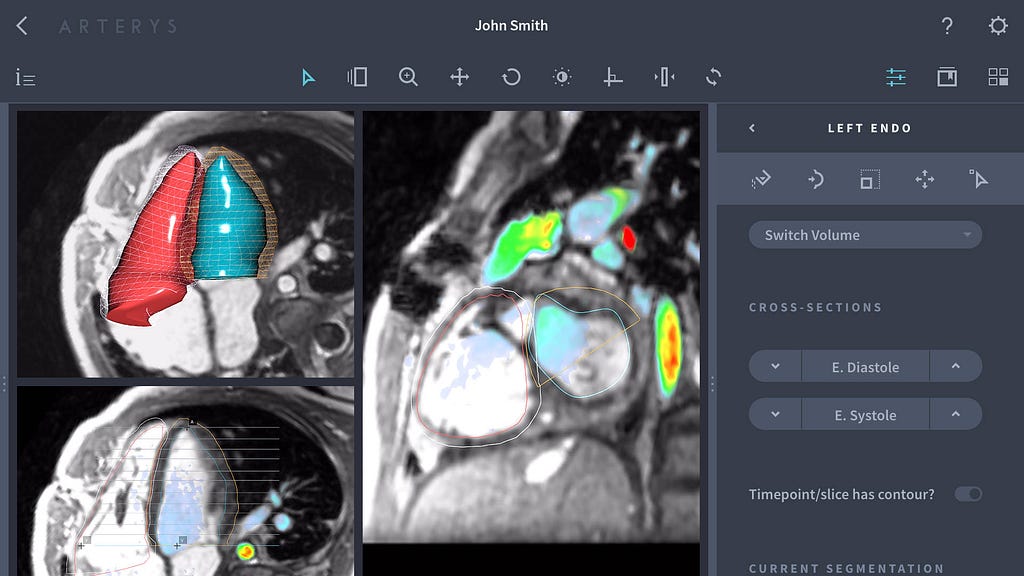 Arterys platform
Arterys platform
In January 2017 the FDA gave San Francisco based startup Arterys the first approval for using AI to diagnose patients in a clinical setting. The company has created a medical imaging service that uses deep learning to analyze MRI scans of the heart. The model was trained using a data set of only 1000 MRI imaging studies which means they will likely need to collect way more studies to increase the robustness of their platform. The company’s 4D Flow cloud-based platform can receive cardiac MRIs and then analyze them with algorithms to determine the ejection fraction — i.e. the volume of blood that the ventricles eject from the heart with each contraction. In February 2017 Arterys partnered with GE healthcare to launch its flagship product at a private practice radiology clinic in Virginia [42]. Arterys’s algorithm is based on 10 million rules and can also produce contours of the heart’s four chambers in just 15 seconds, while it would take a human cardiologist between 30 to 60 minutes [43]. This year Arterys announced it had also won FDA approval for an AI based cancer detection platform. The software employs deep learning to assist radiologists in diagnosing lung cancer lesions on CT images and liver lesions on both CT and MRI [44].
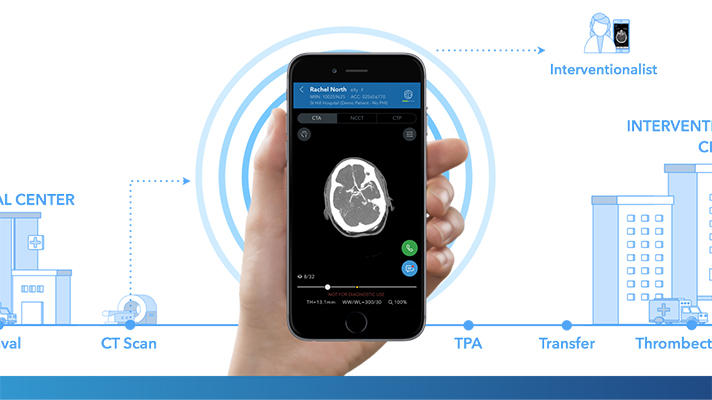 Viz.AI early stroke detection platform
Viz.AI early stroke detection platform
In February 2018 the FDA approved early stroke detection software platform Viz.AI. The platform analyzes CT scans of the brain and if it detects the presence of a stroke will send a text message to a neurovascular radiologist alerting them to look at the imaging study ASAP [45]. The idea is that by alerting providers there will be more timely care decreasing the time to clinical intervention. In the United States stroke is the 5th leading cause of death with an estimated 795,000 people dying per year [46]. It’s estimated that by using the Viz.AI platform the time from imaging to notification of a specialist has been reduced from 66 minutes to 6 minutes [47]. This time difference is critical since the standard treatment of care for ischemic stroke requires tPA to be given within a time window of 4.5 hours (48). Viz.ai received approval based on a retrospective study of 300 CT images in which they compared the effectiveness of the platform vs two human neuro-radiologists [49].
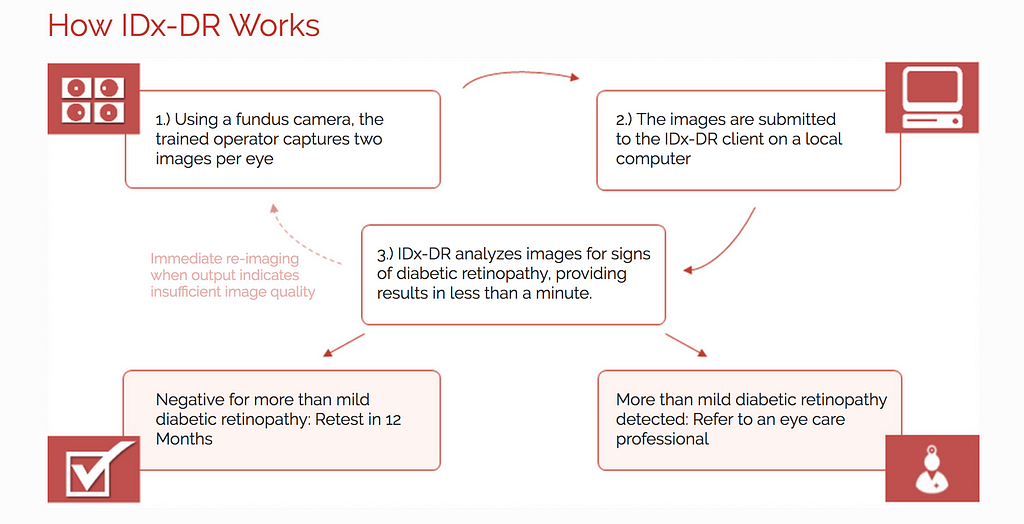 from eyediagnosis.net
from eyediagnosis.net
For the first time in history on April 11th 2018 the FDA approved an AI platform made by Iowa startup IDx that can make a diagnosis WITHOUT a doctor. Their IDx-DR platform diagnoses diabetic retinopathy by analyzing pictures of a patient’s retina which are uploaded to the system by a nurse or physician [50]. Diabetic retinopathy is the most common complication of diabetes and there are an estimated 200,000 cases per year. If left untreated the disease can progress to blindness so it is important for early detection and management [51]. IDx-DR is the first of its kind and represents a giant step for the future of medicine especially given the extreme shortage of doctors the US is facing. It’s estimated that a decade from now there will be a shortage of more than 40,000 doctors [52]. This platform allows family practice physicians who are able to obtain images of a patient’s retina to make a diagnosis without the need of an ophthalmologist. A clinical trial with 900 participants showed that IDx-DR correctly diagnosed diabetic retinopathy 87% of the time while it correctly identified patients that did NOT have the disease 90% of the time [53].
A new study took funduscopic images using a smartphone on 296 patients in India. The results were also extremely promising. The IDx-DR platform even with this smartphone-based approach had a specificity of 80.2% and a sensitivity of 95.8%. This is on par or better than ophthalmologists and retina specialists according to the study [54] As evident from the above examples FDA approval for these type of AI powered diagnostic tools is a very recent development. Given the FDA’s very new committee for these types of digital health and AI powered platforms it is very likely we will see many more approval announcements in the months to come.
The Old FDA and the Digital FDA
“If you’re trying to develop a new drug, that costs you a billion dollars to get through the FDA. If you want to start a software company, you can get started with maybe $100,000” — Peter Thiel [55]
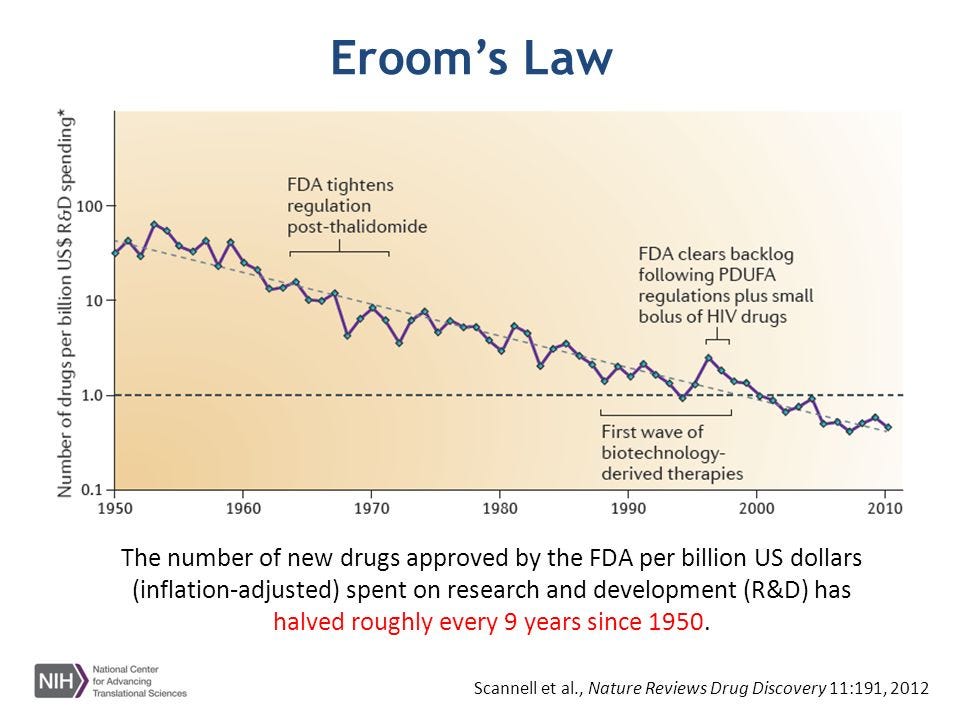
The FDA is the oldest consumer protection agency in the country and as most old things it can be incredibly slow. Established in 1848 as a small little division of the US Patent Office, over time the FDA has ballooned in size to become one of the largest and most stringent consumer protection groups in the entire world. The insidious growth in bureaucracy has had negative repercussions on innovation. New medical device approval can take upwards of 7 years and cost tens of millions of dollars. In fact, the average cost to get a medical device (hardware) approved from start to finish is currently pegged at $94 million [56]. But wait…it gets worse. New drug approval takes an average of 12 years and the average cost is more than $2.5 billion, a 145% increase in cost from 2003 [57]. This trend has been remarkably consistent over time leading to what experts call Eroom’s Law, which states that the cost of approving a new drug doubles roughly every 9 years.
Realizing the rapid pace of innovation that is taking place in software and AI, the FDA’s associate director for digital health Bakul Patel decided to streamline the approval process. He’s heading a digital division of the FDA consisting of 13 software engineers and AI experts. Patel aims to create a pre-cert process in which companies who have passed inspection can continue to add software products to the market without regulators having to inspect every new platform or update [58]. Already several companies have signed up for the pre-cert process including Apple, Samsung, Verily (subsidiary of Google), Roche, and Johnson and Johnson. Apple and Google especially have huge amounts of cash that they have been piling into various digital healthcare initiatives such as diagnosing Parkinson’s, diabetes, and diabetic retinopathy [59].
It seems that ever since the 21st Century Cures Act, which was passed in December of 2016, the FDA has been racing to keep up with the times. This landmark act changed the definition of what the FDA considers as a medical device to exclude certain types of software making it less difficult to obtain approval for certain types of digital health companies [60]. The newly appointed FDA commissioner, Dr. Scott Gottlieb also announced that the FDA would be creating a data science incubator cleverly called INFORMED (or the Information Exchange and Data Transformation) that would study how data analysis using AI/ML plays into the FDA approval process. Dr. Gottlieb states that “The initial focus of this new tech incubator will be, among other things, the conduct of regulatory science research in areas related to health technology and advanced analytics related to cancer. Our goal will be to help modernize our framework for advancing promising digital health tools.” [61] Clearly the new digital FDA has its eyes on the future. Hopefully with these new internal incubators and small teams the approval for innovative new AI technologies can come to providers faster.
Dermatology, Radiology, and Pathology
“Radiologists and pathologists need not fear artificial intelligence but rather must adapt incrementally to artificial intelligence, retaining their own services for cognitively challenging tasks” — Dr. Eric Topol and Saurabh Jha [62]
The FDA’s digital health and AI approval bodies are going to be very very busy for the next couple of years as a ton of startups, large tech companies, and universities are working on automating diagnosis in dermatology, radiology, and pathology.
Researchers at Stanford have used convolutional neural nets (a form of deep learning) to diagnose skin cancer and melanoma. The algorithms were trained on a data set of 130,000 skin lesion images and 2,000 different skin diseases [63]. This application is incredibly important considering that there are more than 5 million new skin cancer diagnoses each year. Early detection is critical as there is an associated 97% survival rate, however this drops with late detection and is as low as 15% if caught at stage IV [64]. Stanford’s deep learning algorithm was tested against 21 dermatologists and performed just as well as them in making clinical assessments [65].
 A whole bunch of AI startups in medical imaging and healthcare. Image from CBINSIGHTS
A whole bunch of AI startups in medical imaging and healthcare. Image from CBINSIGHTS
In terms of radiology there are way too many AI startups too count, not to mention the large conglomerates such as GE and Siemens that are working on building a presence in the space. The field is more crowded than a Cro-Mags most pit, but with all these players there will certainly be more platforms receiving approval and hitting hospitals soon. Perhaps the most impressive player in the field is a pioneering Israeli startup named Zebra Medical Vision that offers a cloud-based platform that charges just $1 per imaging study. They have 5 FDA cleared algorithms and have performed more than a million scans [66]. They will likely receive approval for the other products in their platform such as breast imaging study analysis automation.
In 2016 a team at Harvard and Beth Israel Deacon won an international imaging competition by detecting metastatic breast cancer that had spread to lymph nodes on pathology slides by using neural nets [67]. The success lead some of the researchers to create a startup named PathAI which as you probably guessed uses AI to automate diagnoses based on slide images.
Although 80% of patient care is associated with the examination of pathology slides, there had been no digital disruption of pathology until April 2017 when the FDA granted permission to make diagnoses based on digital pathology images for the first time [68]. It’s not just these pioneering startups though, IBM’s Watson has collected more than 30 billion digital images in the fields of radiology, dermatology, and pathology. Dr. Eric Topol told VentureBeat that, “Most doctors in these fields are overtrained to do things like screen images for lung and breast cancers. Those tasks are ideal for delegation to artificial intelligence.” [69]. Although it is inevitable that AI will disrupt the traditional role of doctors in these three specialties, the transformation will not take place overnight. There are of course sizeable obstacles that will need to be overcome.
The Challenges That Lay Ahead
“There are no big problems, there are just a lot of little problems” — Henry Ford [70]
 Image from the Economist
Image from the Economist
The path towards full blown AI in healthcare seems inevitable but first there are some serious hurdles such as data acquisition, not enough people working on the problems, hype with limited follow through, not understanding how the algorithms make decisions, integrating into physician workflow, and systemic malfunctions.
In a recent survey of 16,700 data scientists on what were the biggest challenges in the field of machine learning the number one answer was data quality followed by lack of talent [71]. Acquiring large data sets especially of patient sensitive information is perhaps the single greatest challenge. Not to mention that the data sets need to be properly labeled and annotated. If researchers use poor data they will be subject to the GIGO phenomena — garbage in equals garbage out. The founder of data science startup Kaggle recently summarized it well by saying,
“There’s the joke that 80 percent of data science is cleaning the data and 20 percent is complaining about cleaning the data. In reality, it really varies. But data cleaning is a much higher proportion of data science than an outsider would expect. Actually training models is typically a relatively small proportion (less than 10 percent) of what a machine learner or data scientist does.” [72].
What can make data collection so difficult in this setting is that a lot of the data contained in the EHR systems is in free-text form and can be difficult to sort through not to mention time consuming. In addition, EHR systems usually are not compatible with one another making data acquisitions across multiple institutions more difficult. Thankfully there are open access databases of medical information such as x-rays on the internet that can be used to train models provided by reputable organizations such as the NIH. In addition to actually acquiring the data, there are problems associated with acquiring humans. Human talent in AI that is. According to LinkedIn it’s estimated that there are only approximately 35,000 Americans that have data science skills and only a fraction of them can actually apply and develop machine learning models [73]. Meaning that in the US there is a shortage of these specialists. Because there is a huge shortage the financial incentives for these people are insane and big tech companies such as Google are willing to pay >$300,000k/year salaries for their skills. Hopefully some of these people will be motivated to work on medicine vs. trying to tell the difference between a hot dog vs. not a hot dog.
 Silicon Valley on HBO. Jian Yang.
Silicon Valley on HBO. Jian Yang.
Which brings us to the third problem which is hype with limited results which results in disillusionment. Nowhere can this be illustrated better than with IBM’s Watson. Several upper level executives have spoken out that IBM used deceptive marketing tactics to sell its AI services to hospitals and providers. StatNews also reported last year that despite relentless marketing and advertising, IBM’s Watson for cancer clinical decision support had only been adopted by 12 hospitals and was still struggling to learn the differences between even the most basic types of cancer. This difficulty lead MD Anderson to cancel their partnership with IBM after 3 years and spending millions trying use the machine [74]. And IBM is surely not the only one to fault here, there are of course much smaller startups that are high on hype and short on product.
In a recent stunningly well written NYT article Stanford professor Vijay Pande described the “black box” problem of AI. Basically the problem is that these neural nets are fed input data and then produce output data while the steps in between are opaque and researchers sometimes don’t know how the algorithms came to the conclusions that they did. This will pose a problem to doctors who insist that they have reasons behind their diagnosis. Simply having an algorithm that tells you the answer without knowing why will probably not convince doctors to use it. Pande writes, “Doctors will no longer “drive” the primary diagnosis; instead, they’ll ensure that the diagnosis is relevant and meaningful for a patient and oversee when and how to offer more clarification and more narrative explanation” [75]. He is right but first doctors are also going to need to be trained on how AI and machine learning work which will also slow down the adoption. Given the current abysmal state of medical training/education this may take longer than most non-medical professionals think. Doctors are very busy people and they often do not have the time to learn new things or try out new technologies. Convincing them to use AI platforms even if they are better and safer is going to take a lot of work, time, and persistence. Legacy platforms and technology in hospitals have a tendency to stick around even decades after they have become obsolete in other industries. Two well-known examples that even in the year 2018 still exist are fax machines and pagers.
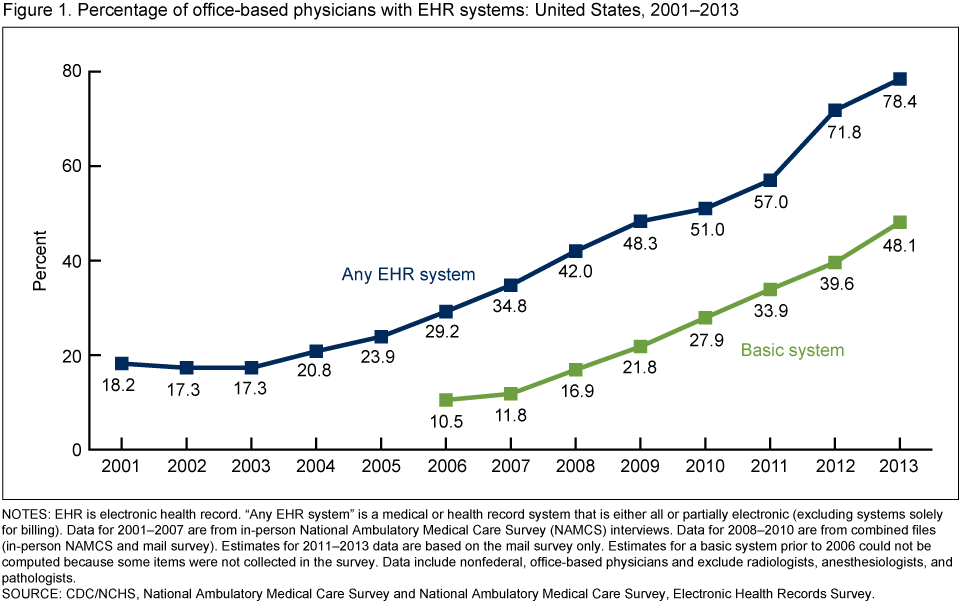
Fax machines are still routinely used to transmit medical charts from hospital to hospital. And don’t even get me started on pagers (yup those are also still the industry standard to communicate). In order for AI to go mainstream at most hospitals it will likely take government mandates. To give you an example the first EHR systems were used in the early 1960’s. In 1991 the Institute of Medicine declared that all physicians needed to use EHR’s by 2001 to improve healthcare, but there was no actual law/mandate passed. By 2001 only 18% of doctors were using an EHR system. Meaningful adoption of EHR did not become significant until after the federal government mandated the adoption by passing the HITECH act and paying out $21 billion to acute care hospitals to adopt the technology [76].
The final problem that needs to be sorted out is potential software errors leading to adverse outcomes. Case in point the recent NHS mammography scandal in which a faulty algorithm caused 450,000 women to miss their breast cancer screening [77]. To prevent debacles like this it is necessary for software companies to continually check their code so as to avoid bugs. If these companies want faster adoption they are going to have to safeguard against these kinds of errors. Despite all these possible obstacles, it is certain that AI will find its way into healthcare. It may take longer than other more rational industries but slowly it will.

The Future
“Future medicine will be the medicine of frequencies” — Albert Einstein [78]
In the future AI will make every single diagnosis. Most algorithms will be just as good or better than the very best board-certified MDs. Instead of physicians relying on their “intuition”, what they learned in medical school, or what they read on UpToDate right before they saw the patient they will rely on an automated AI generated report. We are still far away from this future. Even in 2017 nearly 100% of US healthcare was delivered with 0% AI involvement [79] But in the ensuing decades this will change. Today there are hundreds of venture-backed startups working on these types of solutions not to mention the multibillion dollar tech conglomerates.
Although we mostly covered radiology, dermatology, and pathology it is important to note that this is just the tip of the iceberg. There are also currently platforms being built that diagnose congenital disorders using machine vision, mental health conditions such as depression and mania, neurologic diseases such as parkinson’s, epilepsy, and alzheimer’s, respiratory diseases such as asthma, and not to mention cardiovascular disease based on ECG and heart rate data. The AI revolution in medicine will not happen overnight. It will take some time for these pioneering companies to receive FDA approval and even longer for doctors to become comfortable using these technologies on a daily basis. Likely after much consideration, a federal mandate will be passed that requires doctors to use the technology because it is better than the traditional old school method of relying on the human brain.
The history of AI is one that is based on booms and busts so it is likely that there will be another bust in the future which will slow some progress in the short term, but will lead to much stronger business strategies and discoveries in the long term. It’s true that as a field AI has been around for close to 60 years, but only in this past decade has there been any real significant progress in applying the technology to healthcare. And even more recently only in the last 5 years have we seen these application becoming robust enough to receive FDA approval for clinical use. There is still a ton of work to do and we are still obviously in the very early stages, but now more than ever we need better tools to help our doctors.
Healthcare in America is going through a crisis in which both the doctors and patients are suffering. Doctors have become so overburdened by paperwork and bureaucracy that they can no longer give their patients the attention they need. The system has resulted in our physicians dealing with large amounts of stress which can lead to depression, drug use, marital problems, burnout, and unfortunately suicide (which has become too common). These things result in patients getting bad care. According to a John Hopkins study, medical errors cause more than 250,000 deaths/year making it the third highest cause of death (after heart disease and cancer) [80]. Surely, we can do better than this.
 Image from Iatrogenics.com
Image from Iatrogenics.com
Using AI is not going to solve all these problems, but it can help. It’s just impossible for doctors to always perform at the top of their game because they are human — and like all of us they can occasionally screw up. Having an AI diagnostic assistant to objectively analyze the data and come to a conclusion based on the numbers and facts will lead to less misdiagnosis especially with respect to rare diseases. Algorithms don’t get divorces and have to pay child support. They are objective and have no emotion. They crunch numbers and sort through facts. Doctors can however do what machine learning algorithms can’t which is empathize.
 Picture that Changed the World. Time Magazine 1987.
Picture that Changed the World. Time Magazine 1987.
AI at its best will restore humanity and caring to medicine. If we ignore this technology we risk hurting our patients. For physicians that fear losing their job to AI remember that at the end of the day medicine is not just a science but also an art. The Hippocratic oath that all doctors swear on their first day of medical school states “I will remember that there is art to medicine as well as science, and that warmth, sympathy, and understanding may outweigh the surgeon’s knife or the chemist’s drug”. AI alone is no good. We still need the humans. And if we let it, maybe AI can help us bring the humanity back to medicine.
AI in Medicine: A Beginner’s Guide was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.