Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
What is so unique about Flink, and what sets it apart from Storm and Spark?

Engineers at Alibaba’s food delivery app Ele.me(饿了吗) are finding themselves increasingly reliant on Apache Flink, an open source stream processing framework released in 2018.
What is so unique about Flink, and what sets it apart from Storm and Spark? This article investigates how Ele.me’s big data platform operates in terms of real-time computing and assesses Flink’s various strengths and weaknesses.
Ele.me’s Platform Today
The following image illustrates the current architecture of the Ele.me platform.
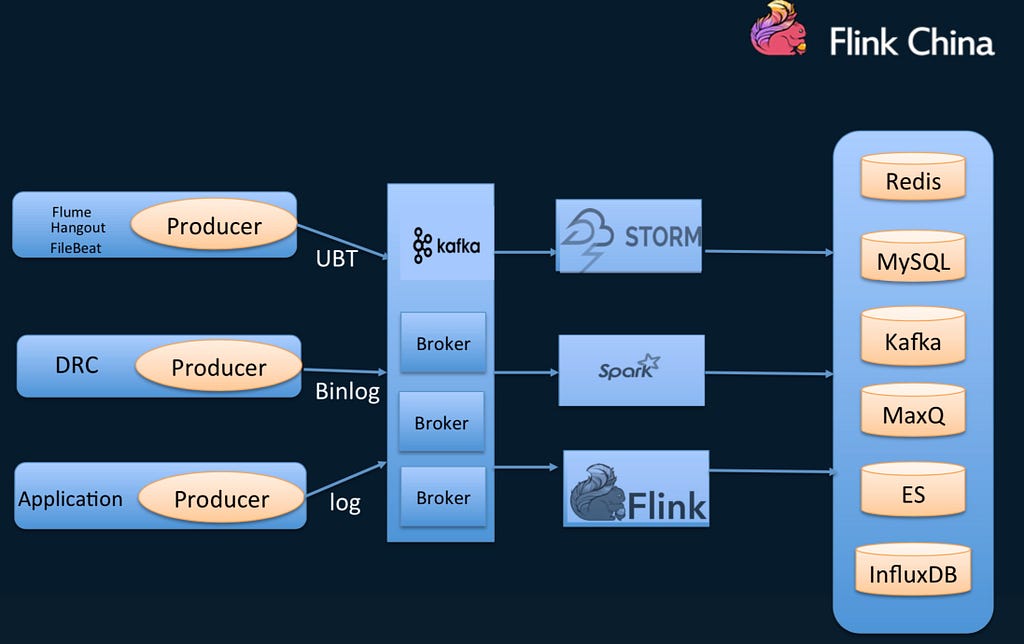 Current platform architecture
Current platform architecture
On Ele.me’s current platform, data from multiple sources is first written into Apache Kafka. The main computation frameworks used for this are Storm, Spark, and Flink. The data results from these frameworks are then deposited onto various types of storage.
There are currently over 100 tasks in Storm, roughly 50 in Spark, and a smaller number in Flink.
The current cluster scale stands at 60TB of data a day, one billion computations, and 400 nodes. One thing to note here is that both Spark and Flink are run on YARN. While Flink on YARN is used mainly as the JobManager isolation between tasks, Storm on YARN is in standalone mode.
This article will focus mainly on five areas — consistent semantics, Apache Storm, Apache Spark’s Spark Streaming and Structured Streaming, and Apache Flink.
Consistent Semantics
It is worth emphasizing here that maintaining the consistency of the following semantics is of paramount importance.
· At-most-once (or fire-and-forget): Typically, when Java applications are being written, the simple “at-most-once” semantic is used, disregarding the source’s offset management and the downstream idempotence. When data comes in, there is no ACK mechanism for it — no matter the intermediate state and the writing data state.
· At-least-once: A retransmission mechanism that retransmits data to ensure that each piece is processed at least once.
· Exactly-once: This is achieved by means of the coarse Checkpoint granularity control. Most exactly-once semantics refer to those in the computation framework, or in other words, whether the state inside the operator of each step can be replayed, and if the last job failed, whether it can recover from its previous state smoothly. This does not involve the idempotence that is output to sink.
· Idempotence + At-least-once = Exactly-once: If it can be guaranteed that the downstream has idempotent operations such as “ON DUPLICATE KEY UPDATE” based on MySQL, or if you use ES/Cassandra etc., you can use the primary key to achieve the “upset” semantics. If you add idempotence into the mix when ensuring at-least-once, the result is exactly-once.
Apache Storm
While Spark Streaming and Structured Streaming were not fully put into practice until 2017, Ele.me has been using Apache Storm since before 2016. Storm boasts the following features.
· Data is tuple-based
· Latency is at the millisecond level
· Java was supported to begin with, but now that Apache Beam is used, so too are Python and Go
· The SQL function is incomplete. Typhon has been encapsulated internally, and users only need to extend some of our interfaces to use the numerous major functions. Flux is also a good tool for Storm. With it, to describe a Storm task, you only need to write a YAML file. This satisfies requirements to an extent, but users still essentially need to be writing Java at the engineer level, meaning that data analysts often cannot use it.
Summary
In summary, Storm has the following three main advantages.
· Ease of use: Because of the high threshold, its promotion is limited.
· State Backend: It requires more for external storage, including for key-value storage databases like Redis.
· Resource allocation: Workers and slots are preset. Throughput is quite low, as only a small number of optimizations has been performed.
Apache Spark: Spark Streaming
At one point, the Ele.me team was asked whether it could write an SQL that could publish a real-time computing task in a matter of minutes. To do so, the team started working with Apache Spark Streaming, the main concepts of which are as follows.
· Micro-batching: You have to preset a window and process data in that window.
· Latency is at the second level, typically around 500ms.
· Development languages include Java and Scala.
· Streaming SQL: The Ele.me tech team hopes to provide a platform for streaming SQL in the near future.
Key features
· Spark Ecosystem and SparkSQL This represents a major advantage of Spark. The technology stack is unified, and SQL, graphical computation, and machine learning packages are all interoperable. Unlike Flink, with Spark, batch processing is done first, meaning that its real-time and offline APIs are unified.
· Checkpoints on HDFS
· Running on YARN Spark belongs to the Hadoop ecosystem and is highly integrated with YARN.
· High throughput As it is a means of micro-batching, throughput is relatively high.
Below is an image of the operations page on the Ele.me platform displaying the steps required when users publish a real-time task.
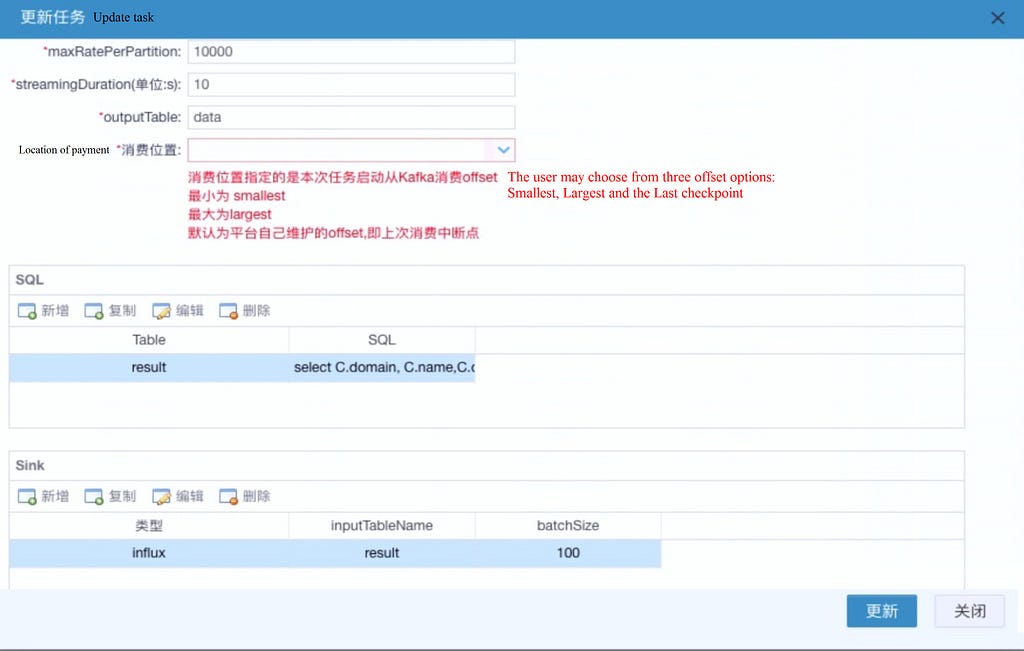
On the page, there are a number of necessary parameters that the user has to select. First, the user has to select the Kafka cluster and the maximum consumer rate for each partition. Back pressure is enabled by default. For the shopping location, the user has to specify this each time. It is possible for a user, the next time they rewrite a real-time task, to select an offset shopping point according to their requirements.
In the middle, the user can describe the pipeline. The SQL is multiple Kafka topics. When you select an output table, the SQL registers the Kafka DStream of the shopping as a table, and then writes a string of pipelines. Finally, some external sinks are encapsulated for the user. All storage types mentioned are supported. Storage is supported if it can implement upsert semantics.
Multi-Stream joining
Some users may still be wondering how to perform multi-stream joining. For Spark 1.5, refer to Spark Streaming SQL. In this open-source project, DStream is registered as a table, and the join operation is done on the table. But this operation is only supported in versions prior to 1.5. After the introduction of Structured Streaming in Spark 2.0, the project was discarded. The method is tricky:
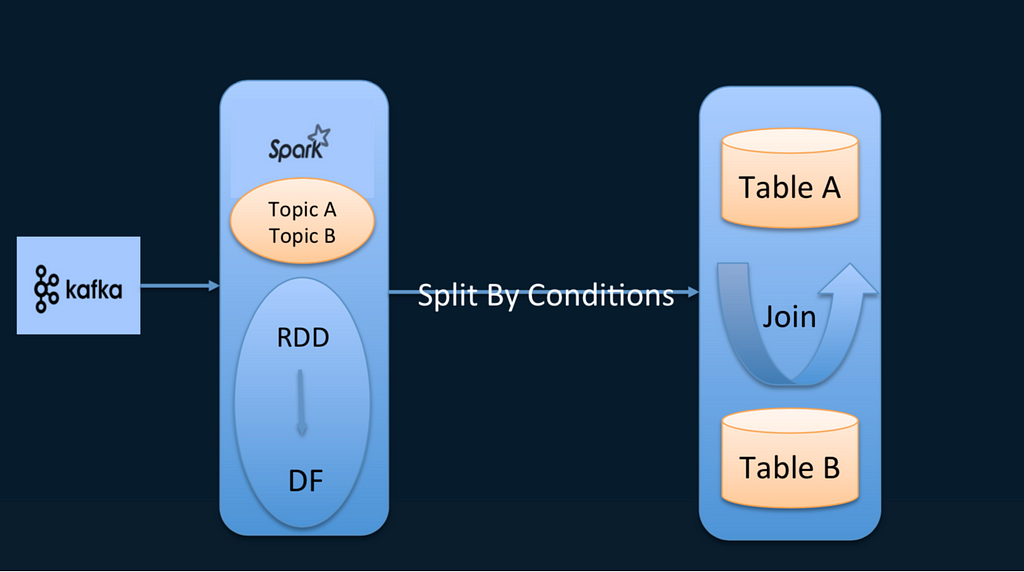 Unique method
Unique method
While allowing Spark Streaming to shop multiple topics, each batch of RDDs in the shopping DStream is converted into DataFrame so that DataFrame can be registered as a table. Then the table is divided in two so that a join can be made. This join is completely dependent on the data of this shopping, and the conditions of the join are uncontrollable. That is why this method is tricky.
Take the following case as an example. Two topics are shopped. The table is split in two under the filer condition. Then a join can be made on these two tables. However, it is essentially a stream.
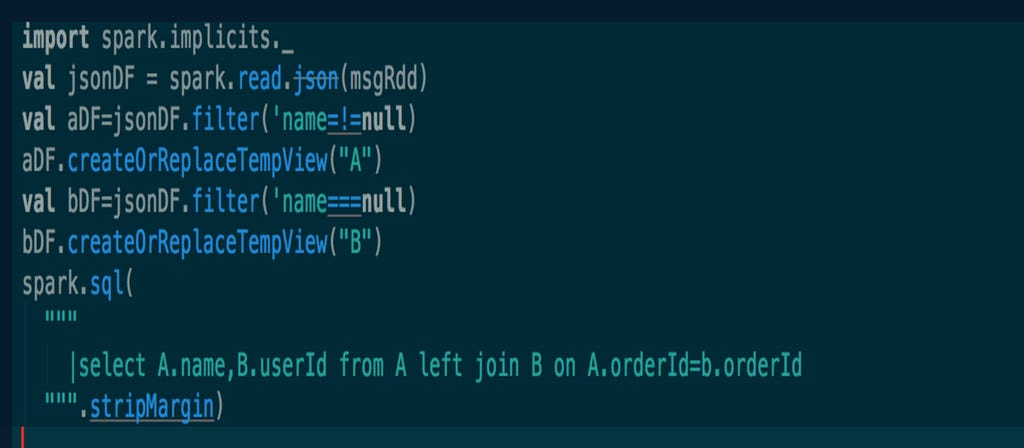 Exactly-once semantics
Exactly-once semantics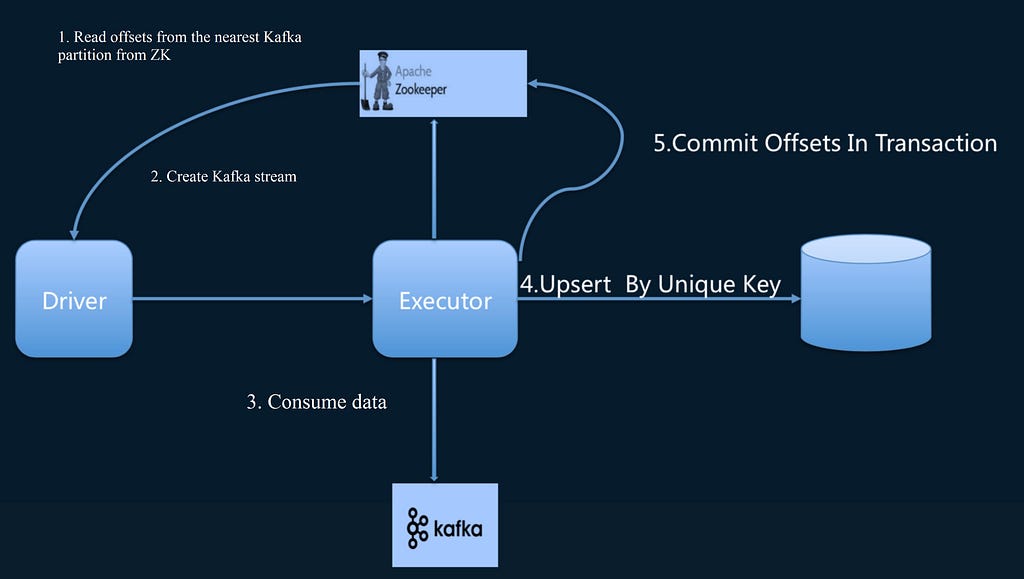
For exactly-once, it is important to note that data must be required to sink to external storage before offset commits. Whether the data sinks to ZK or MySQL, it is important to ensure that it is in a transaction. It is also necessary to output it to external storage before the source driver generates the Kafka RDD and the executor consumes the data. If these conditions are met, an end-to-end exactly-once semantic can be achieved. This is a major premise.
Summary
· Stateful processing SQL (<2.x mapWithState, updateStateByKey): If you want to implement cross-batch stateful computation with the 1.X version, do it through these two interfaces. You still need to save this state to HDFS or external storage. Therefore, implementation is a bit complicated.
· Real multi-stream joining: The true semantics of multi-stream joins are unachievable.
· End-to-end exactly-once semantics: These are difficult to implement. You have to sink them to external storage, and then manually submit the offset in the transaction.
Apache Spark: Structured Streaming
In versions later than Spark 2.X, incremental stateful computations are used. The following picture is from the official website.
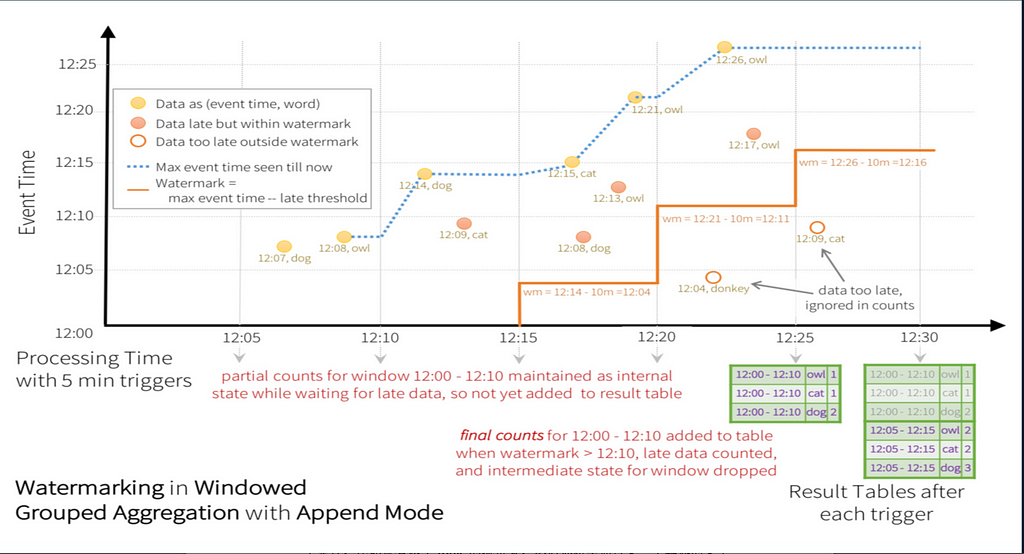
All stream computations here refer to Google’s data flow, which has one important concept — a gap between the time an event occurs and the time data is processed. There is a watermark in the field of StreamCompute, which can specify the range of time delay. Data outside the delay window can be discarded.
The following graph illustrates the architecture of Structured Streaming.
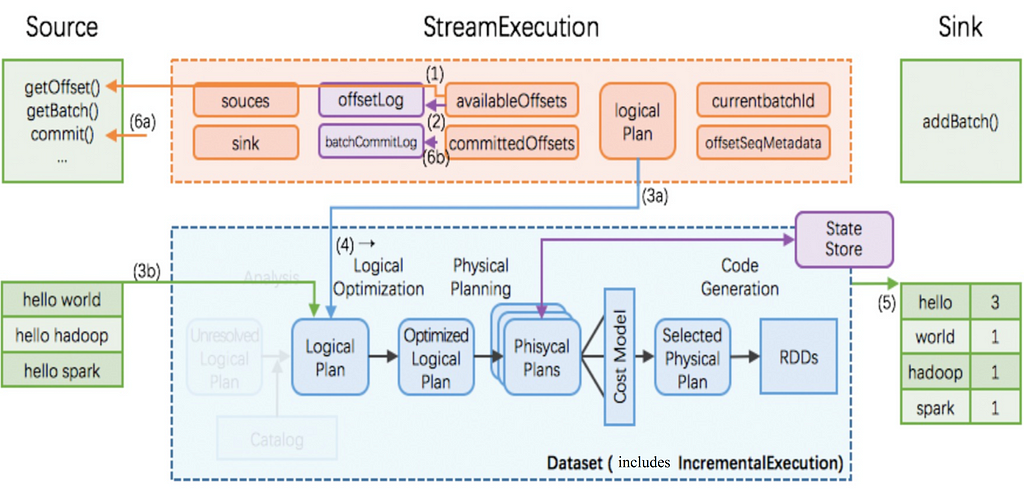
In the graph, steps 1, 2, and 3 of exactly-once semantics are implemented. In essence, the implementation uses the batch method. With this method, the offset maintains itself and HDFS is used for state storage. The external sink does not run a similar idempotent operation, nor does it commit offset after writing. The implementation achieves the exactly-once only of the internal engine, all the while guaranteeing fault tolerance.
Key features
· Stateful processing SQL and DSL: This can satisfy the stateful FlowCompute.
· Real multi-stream joining: Multi-stream joins can be implemented through Spark 2.3. The method of implementation is similar to that for Flink. You have to define the conditions of two streams (this mainly involves defining time as a condition). For example, two topics stream in and you limit the data that needs a buffer through a field in a specific schema (usually the event time). By doing so, you join the two streams.
· It is easier to implement end-to-end exactly-once semantics. To support idempotent operations, you only need to extend the sink interface, which results in exactly-once semantics.
Structured Streaming differs from native streaming APIs most notably in that, when Structured Streaming creates a table’s DataFrame, the schema of the table must be specified. This means that you have to specify the schema in advance.
In addition, its watermark does not support SQL. At Ele.me, the tech team adds an extension to achieve the full SQL write and the conversion from left to right (as shown in the following graph). This is hopefully applicable not only to programmers, but also to data analysts who do not know how to program.
 Summary
Summary
· Trigger: Before version 2.3, Structured Streaming was mainly based on processing time. With this, the completion of each batch of data processing would trigger the computation of the next batch. Version 2.3 introduced the trigger function for continuous processing, record by record.
· Continuous processing: Currently, only map-like operations are supported, and support for SQL is also limited.
· Low end-to-end latency with exactly-once guarantees: The guarantee of end-to-end exactly-once semantics requires additional extensions. The Ele.me tech team found that Kafka version 0.11 provides transactional functions, based on which we can consider achieving end-to-end exactly-once semantics from the source to the engine and the sink.
· CEP (Drools): For users who require functions such as CEP to handle complex events, the Drools rule engine can be run on each executor.
With Apache Spark’s aforementioned shortcomings in Structured Streaming in mind, the engineers at Ele.me decided to start using Flink.
Apache Flink
Flink, an open source stream processing framework, is a leader in the streaming field. It boasts excellent graph computing and machine learning functions and its underlay supports YARN, Tez, among others.
Flink’s framework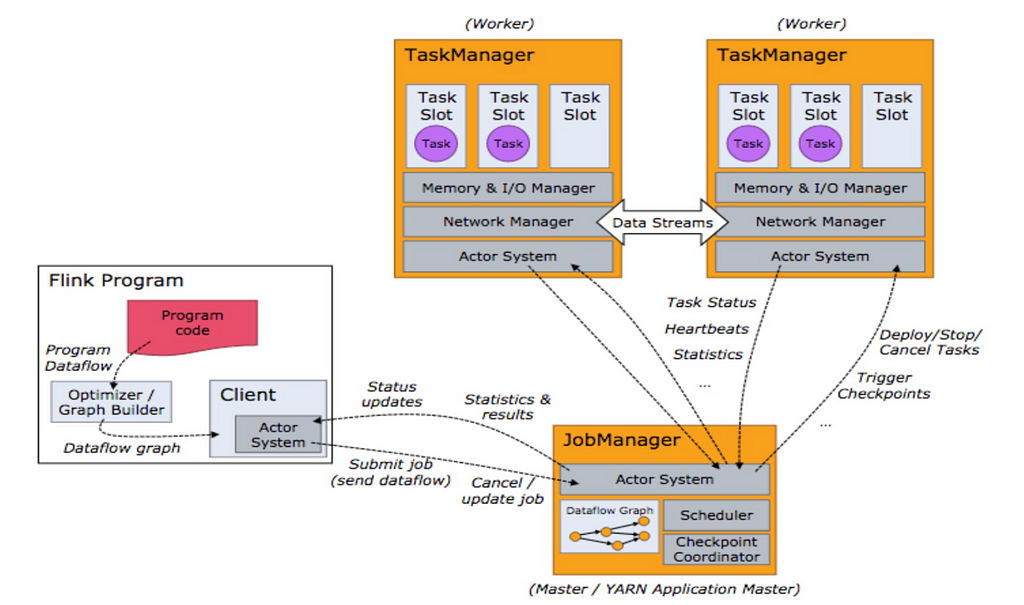
The JobManager in Flink is similar to the driver in Spark, the TaskManager is similar to the executor, and tasks in both are the same. However, the RPC used by Flink is Akka, and the Flink core customizes the memory’s serialization framework. Moreover, tasks in Flink do not need to wait for each other, as tasks at each stage of Spark do, instead sending data to the downstream after processing.
Flink’s binary data processing operator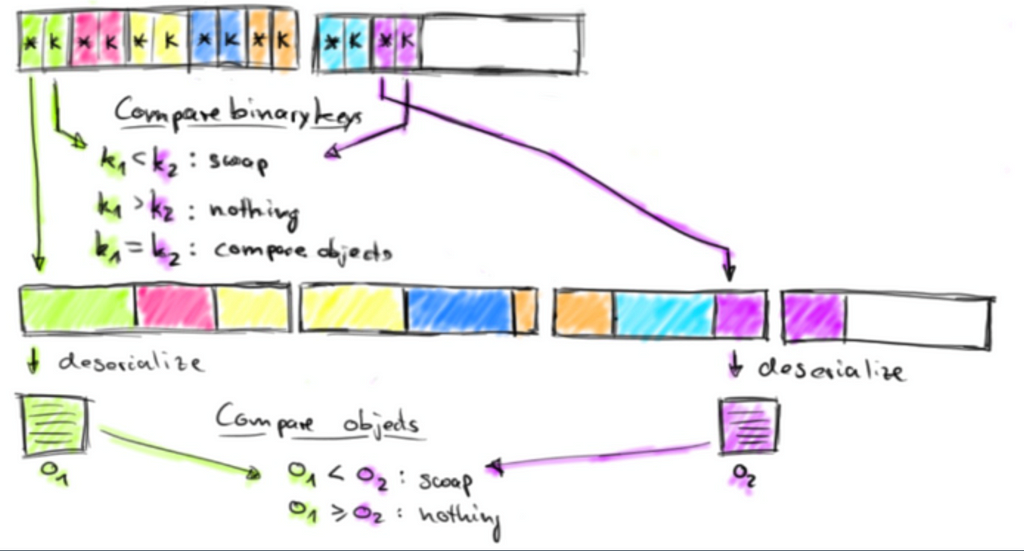
For serialization in Spark, users typically use the default Kryo or Java serialization. Project Tungsten has also optimized a JVM layer and code generation for Spark programs. Flink, meanwhile, implements a memory-based serialization framework that maintains the concepts of key and pointer. Its key is continuous storage, and is optimized at the CPU level. The probability of cache miss is extremely low. When comparing and sorting data, you do not compare the real data — you first compare the key. Only when the result is equal will the data be deserialized from the memory. At this point, you can compare the specific data. This represents a reliable performance optimization.
Flink’s task chain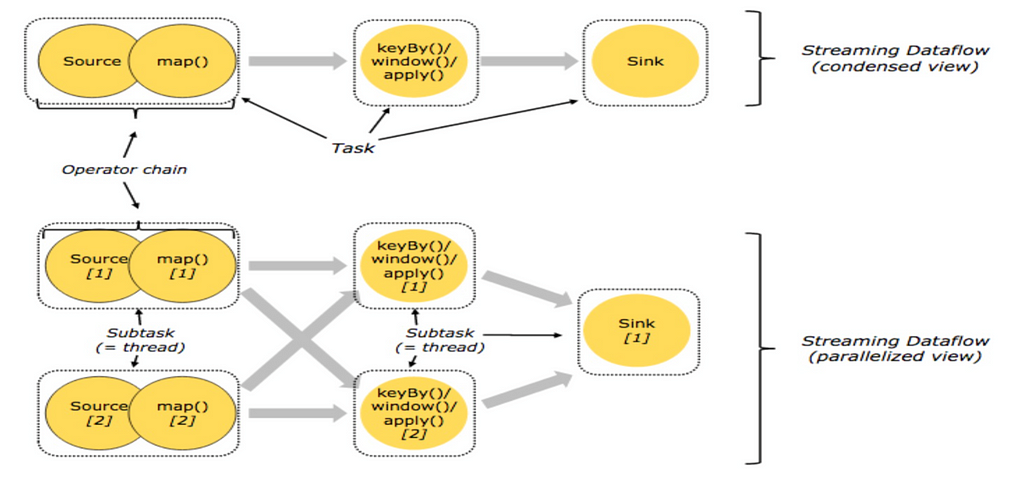
With OperatorChain, if the upstream and downstream data distribution does not need to be shuffled again, the map followed is just a simple data filter. If we put it in a thread, the cost of thread context switching can be reduced.
Concept of parallelism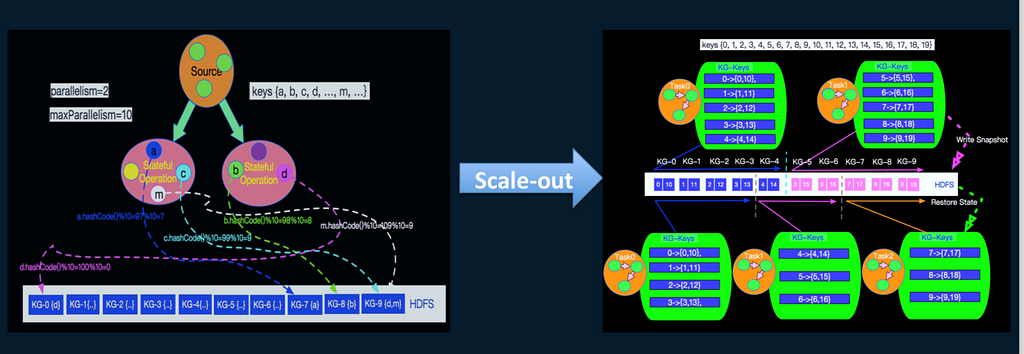
To illustrate this concept, imagine that five tasks need a number of concurrent threads to run for them. If the tasks are chained, they can be run in one thread, which improves the data transmission performance. With Spark, operators cannot set their degree of concurrency, whereas with Flink they can, making Flink more flexible, and resource utilization more efficient.
Spark generally adjusts the degree of parallelism through Spark.default.parallelism. During a shuffle operation, parallelism is generally adjusted by the Spark.sql.shuffle.partitions parameter. In real-time computation, this parameter should be set to a smaller value. For example, in production, Kafka and partition parameters are set at almost the same, while the batch is adjusted to a slightly larger value. In the left graph, the Ele.me engineers have set the concurrency to 2 (up to 10). They then ran two concurrent batches, and made a group (up to 10) according to the key. This way, data can be dispersed as much as possible.
States & checkpoints
Flink processes data piece by piece, and after each piece has been processed, it is immediately sent to the downstream. In contrast, data in Spark has to wait until all the tasks in the stage that the operator is located in are completed.
Flink has a coarse-grained checkpoint mechanism, which gives each element a snapshot at a low cost. Only when all the data belonging to this snapshot comes in will the computation be triggered. After the computation, the buffer data is sent to the downstream. Currently, Flink SQL does not provide an interface to control the buffer timeout — in other words, how long it takes for the data to be buffered. When you construct a Flink context, you can specify the buffer timeout as 0, so that data will be sent immediately after it is processed. You do not need to wait until a certain threshold is reached before sending it down.
By default, the backend is maintained in the JobManager memory. Each operator’s state is written to RocksDB, and the asynchronous cycle is synchronized to external storage incrementally.
Error tolerance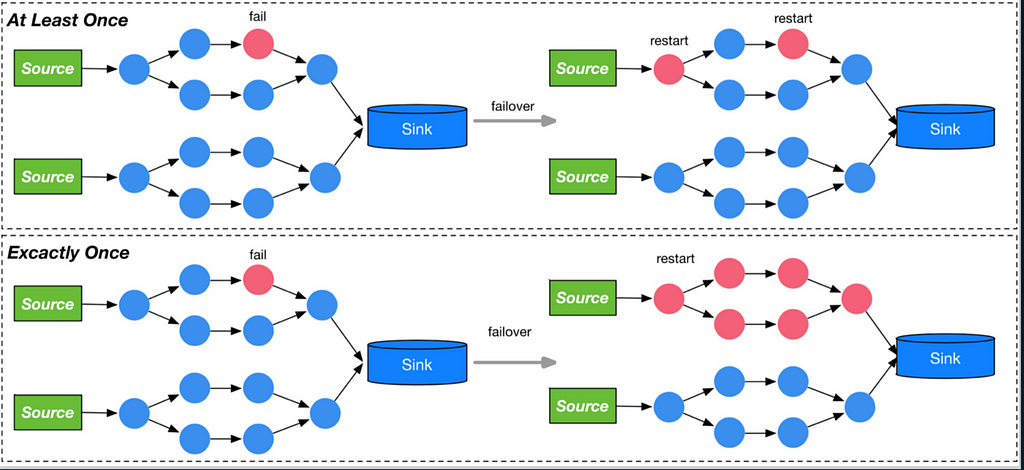
The red node on the left side of the graph has a failover. If it is at-least-once, then retransmitting the data at the furthest upstream can correct an error. However, if it is exact-once, each compute node has to be played back from the time of the last error.
Exactly-once two-phase commit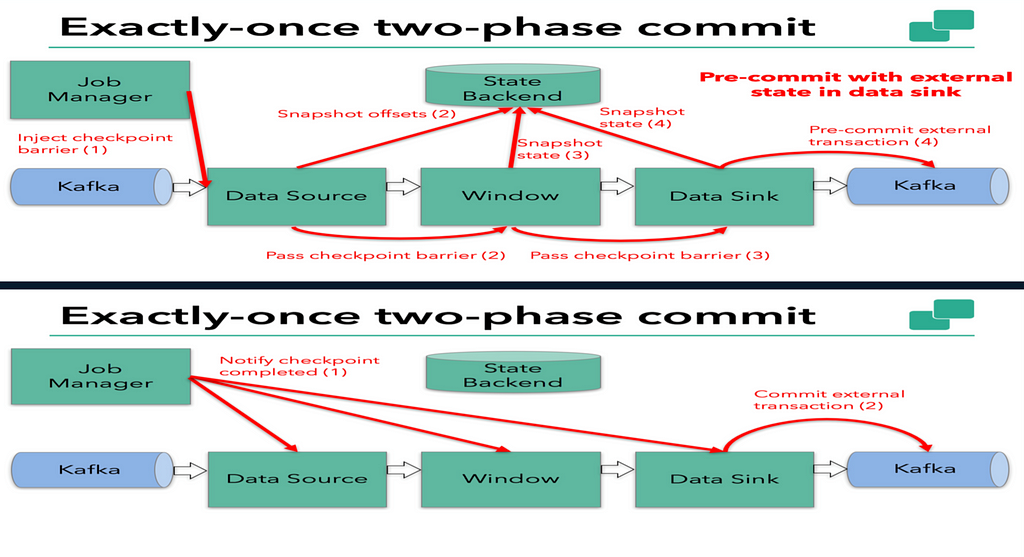
After Flink 1.4, a two-phase commit protocol was introduced to support exactly-once. After data is consumed from the upstream Kafka, a vote will be initiated at each step to record the state, and the mark is handled through the checkpoint barrier. The state is only written to Kafka at the end (this applies only to Kafka 0.11 or later). Only after final completion will the state of each step be notified to the coordinator in the JobManager and solidified, thereby achieving exactly-once.
Savepoints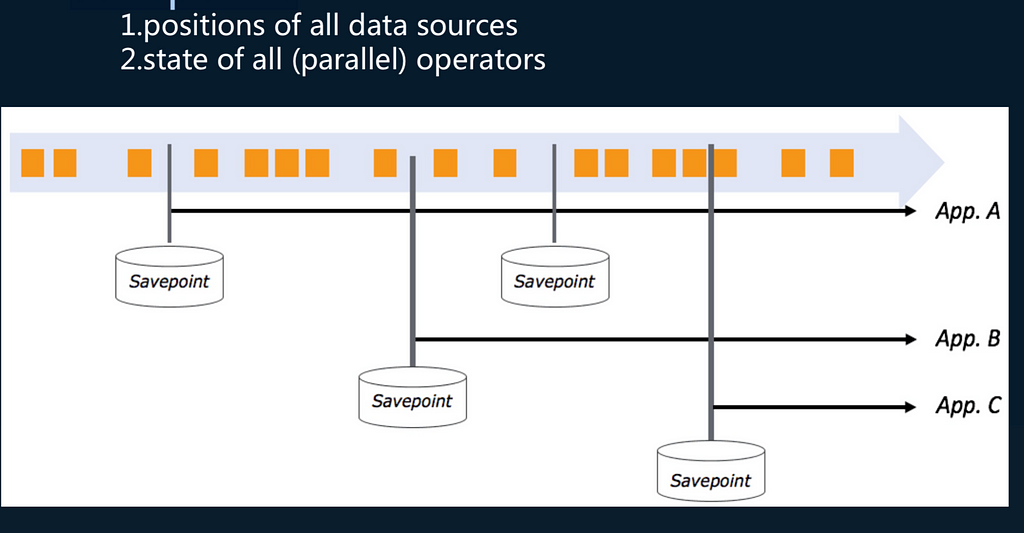
Another advantage of Flink is that the savepoint function can be achieved using Flink’s checkpoint. A savepoint is not just a means of data recovery, but also of recovering the computing state.
Final analysis: Flink benefits vs. drawbacks
Flink’s benefits can be summed up as the following key features:
· Trigger: In contrast to Spark, Flink supports richer streaming semantics, including processing time, event time, and ingestion time.
· Continuous processing & windows: Flink supports continuous processing, and performs better with windows than Spark does.
· Low end-to-end latency with exactly-once guarantees: With the two-phase commit protocol, users can choose to sacrifice throughput to adjust and ensure the end-to-end exactly-once semantics, according to their business needs.
· CEP
· Savepoints: Users can perform version control according to their business needs.
However, there are also some shortcomings in the following areas:
1. SQL: The SQL feature is incomplete. Most users are migrating from Hive, where Spark has a coverage of over 99%. Currently, SQL functions are not supported, and neither is the setting of parallelism for a single operator.
2. Machine learning, graph computing: Flink’s performance here is weaker than Spark’s, but the community is working to improve in these areas.
Alibaba Tech
First hand and in-depth information about Alibaba’s latest technology → Facebook: “Alibaba Tech”. Twitter: “AlibabaTech”.

Flink or Flunk? Why Ele.me Is Developing a Taste for Apache Flink was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.