Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Dear Readers, I’ve finally reached The Edge of CloudFront where the air is as thin as the documentation. But you can do some amazing things here.
 At The Edge of CloudFront, a lone developer looks for the help file.
At The Edge of CloudFront, a lone developer looks for the help file.
I first saw Lambda@Edge at re:Invent a couple of years back and wasn’t sure what to make of it. The demo showed how you could manipulate http headers in-flight but the audience was in a post-lunch sugar-crash full of ‘so what?’. It wasn’t the presenter’s fault —some next-level concepts just weren’t landing their punches with the crowd. I mean, who needs to interfere with the CDN, right?
Recently we started a CloudFront-heavy project that performs all sorts of optimization voodoo for webpages. That’s when I remembered back to the Lambda@Edge presentation and a few lightbulbs started to flicker. To test this, we quickly moved some code into functions at The Edge and saw some blistering performance gains. While there was nothing particularly amazing about the code we wrote, getting it working has been a trial like never before. Let’s cover the gotchas before the gold.

Documentation is a rare find.
Tracking down examples for some AWS services is like the technical equivalent of birding. As much as I love AWS, we all know their tendency to be, ahem, a little light on explaining how things work. L@E takes this to a whole new level to the point where it’s like finding Easter eggs in the cloud.
Seriously, I unearthed only a dozen useful webpages on The Edge, and kudos to those people for fighting through the mess before I arrived. There’s the obligatory Slideshare covering use cases, some very basic examples, a mysterious workshop, and a promising tutorial that falls apart when it uses Sharp inside Docker instead of the native ImageMagick (complexity, people!). It’s actually weird how little has been written.
There’s also some old code floating around. A quick PSA — there are a few good examples from when L@E was in technical preview and they either don’t work now or the early discoverers on the frontier found bugs that have since been fixed. It would be wonderful if these were updated but in any case we lost time following some phantom issues.
I found it was useful to brush up on how CloudFront actually works with the plentiful official documentation — whitelisting headers, how it decides what to cache and when, and all the minutiae you can generally avoid if just treating it as a vanilla CDN. It’s fairly enlightening and a good place to start before diving into how Lambda gets involved, and at least gives you something of a clue when everything hits the fan.
Living on The Edge.
Essentially you can attach your functions to four events in the basic CloudFront life-cycle. CloudFront lives between viewers (users) and origins (the actual servers with the content):
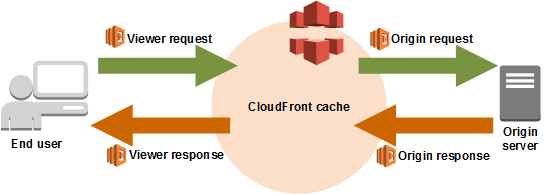
- Viewer request: this happens when a request arrives from a user. CloudFront hasn’t checked to see if the content is cached yet but here you can make modifications to the incoming request.
- Origin request: this only occurs on a cache miss (i.e. CloudFront didn’t have the content). It happens before the fetch but doesn’t happen at all if there’s a cache hit.
- Origin response: this is fired after the content is provided by the origin.
- Viewer response: finally, this occurs before the response is forwarded.
There are some subtleties in figuring out which events to hitch your code to. Eagle-eyed readers will immediately see that you want to avoid the Viewer Request event as much as possible, since it runs every single time and will add latency and charges to your monthly bill.
My normal approach to Lambda is to find a mock event and the shortest possible test code to see what works. I wanted to run four functions (one for each CloudFront event) that write something to the logs so I can get excited about it running successfully. And that took a whole day.
First, I couldn’t find any mock events. This is actually a problem since your function must return a response, and the response is invariably a modified form of the incoming event. CloudFront is going to hand you a long stretch of JSON which your code tweaks before handing it back. So I came up with this simple idea:
'use strict';
exports.handler = (event, context, callback) => { console.log('Welcome from the Edge!'); const response = event.Records[0].cf.response; console.log(JSON.stringify(response)); callback(null, response);};This is a cheap-and-cheerful way to log out what those incoming events look like before we write any real code. And it almost worked.
The Silence of the Lambdas.
Hardened cloud natives are familiar with the joy of managing regions but there’s a kink in The Edge process that has caught me out a few times. When your code runs at The Edge, the logging happens in the CloudWatch region of that edge server. The logs might not be where you think they will be.
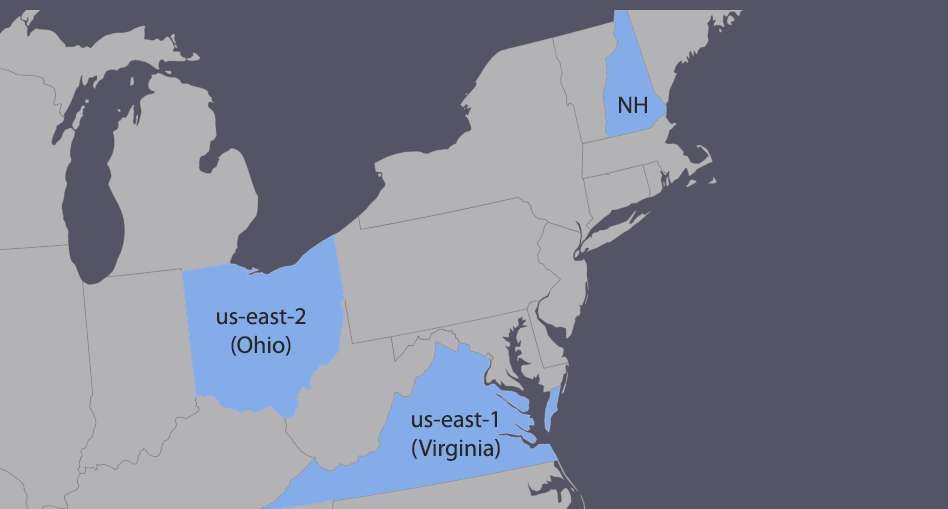
Case in point — I live in New Hampshire (aka the Greater Boston Area when talking to techies). I generally use us-east-1 and always presumed it was my nearest region, so when testing some functions imagine my surprise when the CloudWatch logs were empty in Virginia. I debugged my IAM permissions, my function code, and exhausted most of the expletives I know before realizing something — my nearest region is Ohio.
 Out in New Hampshire, we’re north of The Wall.
Out in New Hampshire, we’re north of The Wall.
Of course, this is either my sub-par geography or CloudFront measuring cable distance not actual distance. It took a couple of hours for me to venture into an AWS region that I have literally never before opened in the console. It seems somewhat alien to have logs generating in a region where you have no services running but now I know. Naturally, there is no indication at all this is happening.
I later tested a webpage on my phone connected to the same WiFi network as my laptop. And logging stopped again. After digging around, my phone tests were logging back in us-east-1 for reasons I don’t understand at all. Then, just when I was getting used to switching between Ohio and Virginia, logs totally disappeared. My functions were running, just not logging, and I was just about to reconsider Azure when I noticed something…
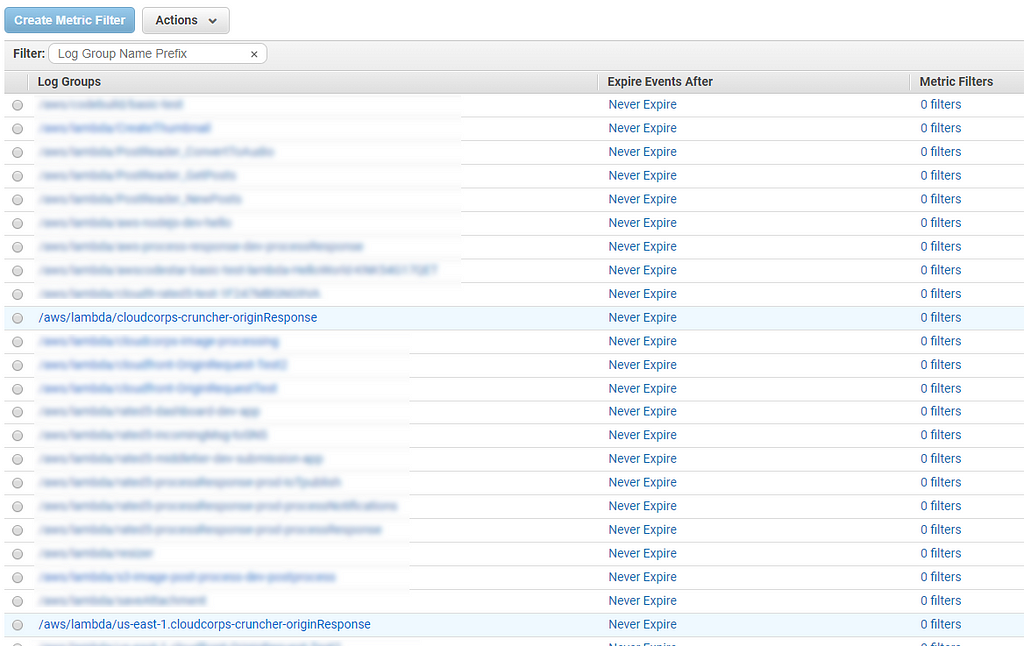
The log stream name changes depending on whether the function is running in your console or CloudFront, so I was searching for the wrong log stream name. Did you know your log stream name can change in Lambda? Since you can only search by prefix and not “contains”, I spent a good hour finding this second log group.
The good news is that many other people are completely bewildered by this on Stack Overflow and it wasn’t just me. One developer reported logs appearing across the world even though the distribution was limited to the US/North America zone. Go figure.

Lesson: if you can’t find your logs and there are no 502/503 errors, The Edge is almost certainly logging in another region. It’s definitely logging somewhere.
The workflow is clunky.
Deploying your functions is an error-prone, messy process. If you’re using the GUI, you must remember that function versions are first-class citizens of The Edge. Many, many bugs we had were due to the wrong version running on a given distribution, since you can’t just link a distribution to the latest version of function.
This doesn’t seem too bad when you have a couple of CloudFront distros running a handful of functions. It becomes a real task when you are trying to script CloudFormation into doing all this and then you want to roll out new versions of functions to The Edge.
Once again, our good friends at Serverless have got to this before us and smoothed out some of the rough edges with the L@E plugin. If you are a Serverless user, this will make your life seem more like that of a developer and it helps orchestrate this versioning issue. Just make sure you aren’t deleting old versions in the YAML (yeah, that was fun) and don’t expect it to be completely flawless.
Generally, we found it a little rough managing the Edge code, especially if multiple developers were in the same space. When combined with the 20-minute deploy time of CloudFront (and yes, that impacts your Lambdas too), it can get a little weird not knowing who is doing what and which code is running.
We also found that deploying Lambda updates to production distributions is an absolutely terrifyingly binary affair, with a 100% success or failure rate. Pushing out your new version to us-east-1 always replicates globally and rolling back can take a while. If you have customers running on your Edge code, it seems the only sane way to deploy updates is to create new CloudFront distributions and migrate users across. And that’s not particularly easy if customers have their DNS pointing at your CloudFront distro.
 It has a happy ending, don’t worry.
It has a happy ending, don’t worry.
But wait… there’s more!
It’s not regular Lambda at The Edge. First, there are many limitations peppered throughout the AWS blurb. You can only create 25 Lambda@Edge functions per AWS account, 25 triggers per distribution, and you cannot cheat by associating Lambdas with CloudFront in others accounts. The hard 25-distribution limit is a showshopper for any broad-scale, SaaS-style implementation.
All your functions must reside in us-east-1 and your IAM permissions must have the right trust permissions in place to allow the replication. You have just 30 seconds to get the job done (5 minutes is for land-loving Lambdas not at the Edge) and you can’t use VPCs. Your responses are limited to 1MB (which is bad news for anyone with dreams of handling images on the fly) and your function package can’t exceed 1 MB. Phew, is that it? Not at all!

The view from The Edge is amazing.
Not for the first time, I’ve persisted through the quirks and annoyances of an AWS product and found the challenge has paid off. The Edge is a different place to regular Lambda, which is a vastly different place to EC2, which is very different to on-premise. We’re on the moon out here, basically.
CloudFront is a pretty slick piece of engineering you can now hook into. The challenge is to do very little and be extremely fast to avoid adding latency. Our initial dreams of jamming everything into a Lambda function at The Edge were quickly squashed when we realized the latency limitations and the fact that CloudFront doesn’t return anything to the user until your code is finished. This blocking behavior must influence your design from the start.
Originally, I thought I could check DynamoDB, save some files in S3, and reprocess the HTML all during the a single call to CloudFront. In practice, we found a better way — identify what could be done asynchronously, and get CloudFront to send messages to SQS to decouple the process. This allowed us to make minimal changes to the Edge functions, keep latency low, but use this ‘hook’ in all sorts of inventive and clever ways we hadn’t imagined previously.

If you run static sites of any kind — flat HTML or SPAs for example, the Edge is now your .htaccess file. It’s surprisingly easy to do URL rewrites, redirects or custom handling within a brief Lambda function. It’s highly scalable, serverless and cheap — and did I mention the performance is blazing?
If you want to add personalization to static sites, handle forms or user posts or pre-process other data before returning to an application, the Edge is the place to be. You can also manage auth here with JWTs, run simple A/B testing and use the WAF to block attacks instantly. And though we’re early in our Edge usage, it doesn’t look like there are any significant coldstart issues beyond when an edge function scales outs.
Strangely enough, the one cliched use-case that’s always mentioned in the same breath as Lambda — namely, image optimization — looks like an anti-pattern that probably isn’t such a great idea. Pulling an image from S3 and resizing or optimizing on the fly can run into the limits mentioned earlier, and generally provide a sluggish user experience. There are also better ways to do it using regular Plain Ol’ Lambda.
My adventures with Lambda@Edge have been really interesting despite some incredibly annoying hours in the first few days. This is a useful new gadget in my cloud toolbox that I wouldn’t use in every application but it has no alternative when it’s genuinely needed. Just as Lambda changed the way I look at piecing together solutions, I now find The Edge creeping into my designs and I’m excited to find what I can do with it next.

Postcards from Lambda @ the Edge. was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.