Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.

Marcelo is a Senior Software Engineer in one of the biggest companies in South Florida. Marcelo is in charge of building the analytics engine his company needs.
In a conversation with Marcelo, he explains what his company needs and some of the available technologies that his team could use. Let’s hear him out.
They need to capture every click on the company’s website in order to track what is the most important content.
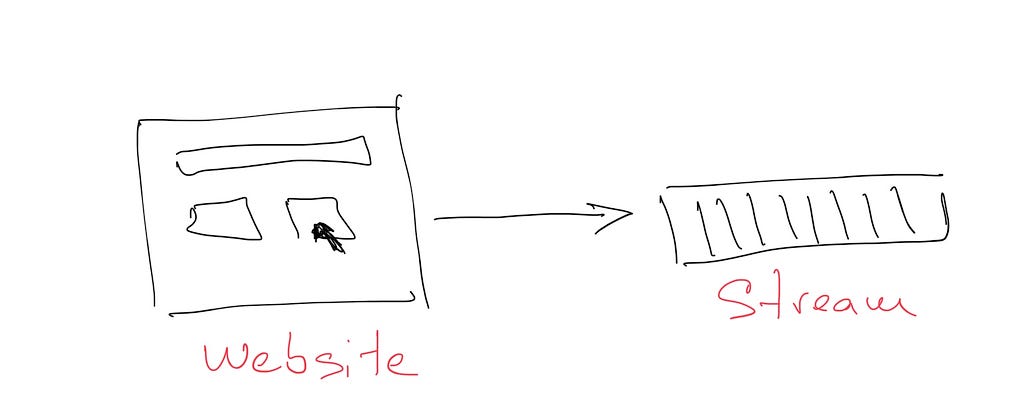
Marcelo says that his team is very convinced that they will use some kind of stream platform, and Apache Kafka seems the right choice. However, they don’t have any experience managing a Kafka cluster. The Kafka API is simple enough and the performance quite good, so they are seriously considering its use.
The second step it to aggregate the events on the stream and save the aggregates on some kind of database so that they can query using the BI tools the company uses, Marcelo explains. MongoDB looks good for this task because its simple API, distribution and ability to scale. Yet, introducing a new technology stack is something the team really wants to avoid.
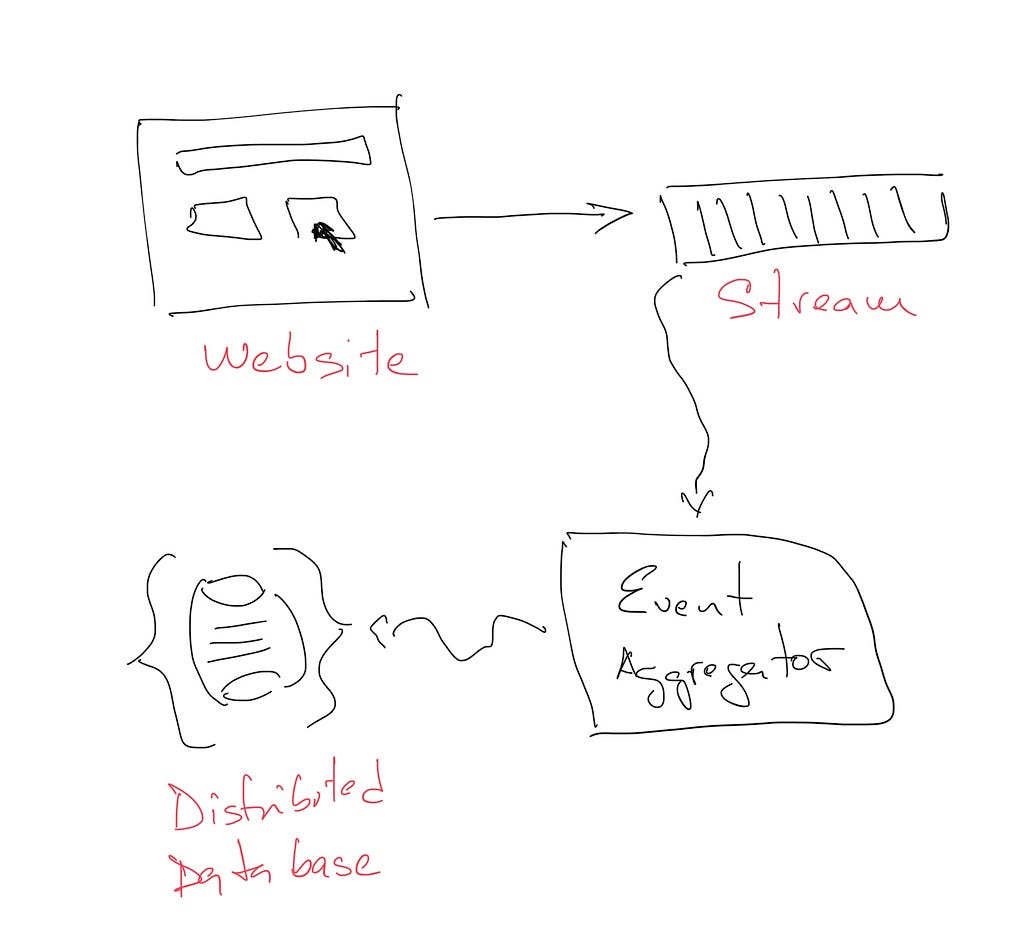
Also, they want to save the raw events, so in the future they can replay them as they originally came with a new aggregator in order to extract new information. Given the high volume of messages and the importance of them for Marcelo’s company, they want a globally distributed file system that can scale along side the company volume of data. Along with the Event Aggregator, they want a Sink application that reads from the stream and write to the file system in the following way.
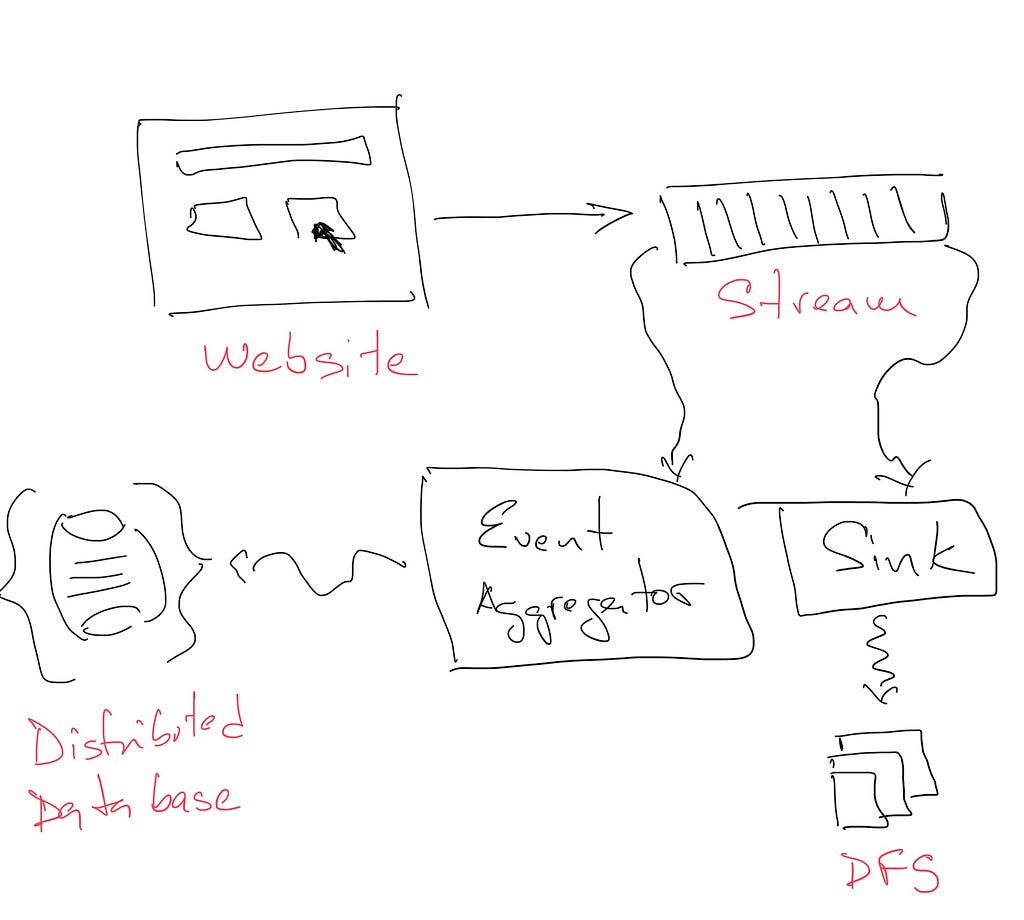
As we can appreciate, Marcelo’s requirements are starting to get complicated and all that on top of a serie of technologies that the team needs to master.
Now, they also need to create other applications to analyze and track the use of the company’s website. For example, they want to watch certain link of the site that they call hotlinks. Everytime one of these links is clicked, the marketing department should get notified.
At this point, Marcelo’s team has many other use cases for the information coming from the website, and building applications is not a problem for his high performance team. However, they still need to deal with a set of separated technologies they don’t exactly know how to manage.
They need experts to manage the Kafka cluster and having it running it all the time. They need MongoDb personnel to configure and distribute this document database. They need a distributed file system capable of scale to their needs. Finally, they required the right application framework that integrates all these technologies.
After Marcelo has explained his team needs, another friend of mine sends the following link to him. How MapR improves our productivity and simplify our design.
Why MapR?
The answer is simple, because it has all the components my team needs under the same platform, Marcelo explains.
When installing MapR in our cluster, we got everything we needed at once, under the same platform. The MapR file system scales easily along the company’s needs. Also, it provides different interfaces so all kind of applications can communicate with it. It doesn’t matter if we write a MapReduce job, a Spark Streaming application or a simple Java app running on a docker container. The file system POSIX capabilities along with the HDFS and NFS interfaces are perfect for all kind of access.
On the other hand, MapR Streams expose the same API the team is familiar with, the Kafka API. At the same time, MapR Streams are implemented on top of the MapR file system, so streams also scale as the file system does adding new capabilities over what Apache Kafka can do. Also, no need for an extra cluster just for streams is needed since they are already integrated in the MapR cluster. The MapR Control System provides ways to manage the streams directly on the GUI, which is a lacking feature of Kafka out of the box.
Marcelo also explains how MapR-DB, part of the MapR cluster, is used to store their aggregates. MapR-DB is able to process JSON naturally and also exposes a nice API so JVM applications can communicate nicely. MapR-DB is also built on top of the MapR file system, sharing with it much of the scale capabilities and security features.
Marcelo ends saying that they are glad to explore MapR and it capabilities. That it is nice to have so powerful and simple tools under a single data platform built for today and future applications.
Finally, this is an sketch of some of the current systems.
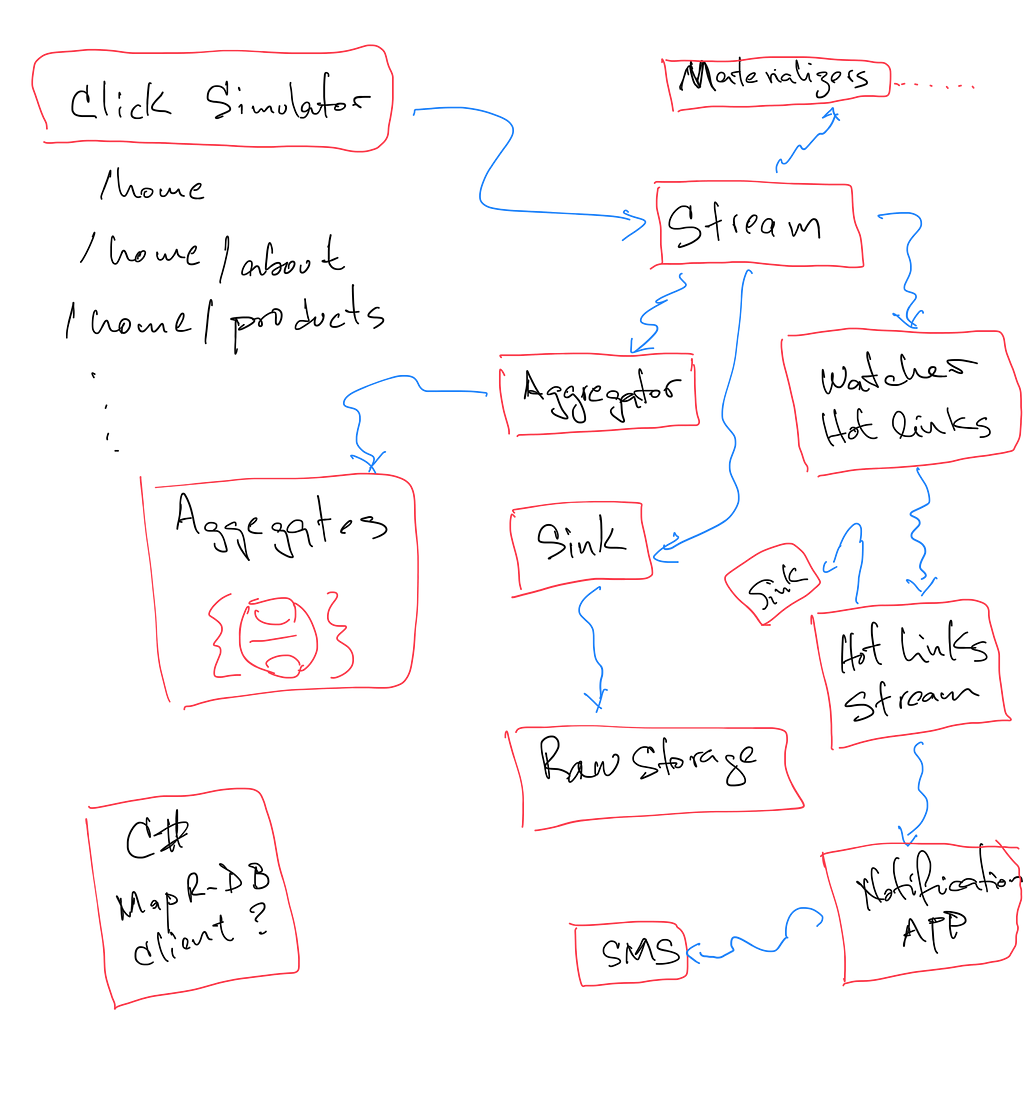
In our next post we will be showing some of the implementation details of some of these parts, stay tuned.
Thanks to Marcelo for being part of this story that shows how MapR Technologies is the future.

Why did Marcelo choose MapR? was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.