Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Speaker Diarization — The Squad Way
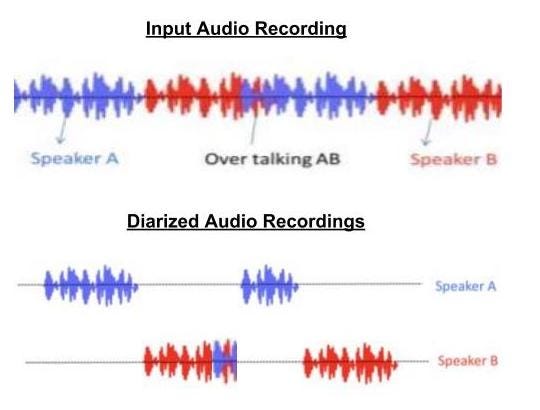
Speaker Diarization aims to solve the problem of “Who Spoke When” in a multi-party audio recording.
At Squad, ML team is building an automated quality assurance engine for SquadVoice. During the quality check phase, a calling representative’s performance is scored on various quality parameters, such as:
- Whether the representative was rushing on the call or not,
- Whether (s)he was rude to the lead at any time or not,
- Whether (s)he used the proper language, and many more.
Such quality checks for a call recording are guided by “what” was spoken by the calling representative and “how” the same content was spoken. Thus, we need to ensure that the call recording portions where the agent spoke are separated from the portions where the customer or lead spoke. This, was a challenging problem, as Squad’s cloud telephony partner for India, records calls only in monaural format. Monaural format stores both parties audio on a single channel as opposed to stereophonic format, where audio of caller would be stored on one channel and that of callee would be written on a different channel. Thus, as a prerequisite for the quality checks, a speaker diarization system was required. However, we had a more focused problem, since the number of speakers for our use case was fixed at two.
 How to solve Speaker Diarization?
How to solve Speaker Diarization?
The problem of speaker diarization is quite complex. To be honest, it is the toughest Machine Learning problem that I have worked on till date. This solution utilizes both supervised and unsupervised Machine Learning techniques. Also, it relies on a combination of both recent Deep Learning and conventional Agglomerative clustering models. So let’s get started.
Our speaker diarization solution is derived from the combination of One shot learning, speaker recognition architecture used by the work: “VoxCeleb: a large-scale speaker identification dataset”, and speaker change detection algorithm explained in this work: “TristouNet: Triplet loss for speaker turn embedding”.
Speaker differentiation pipeline
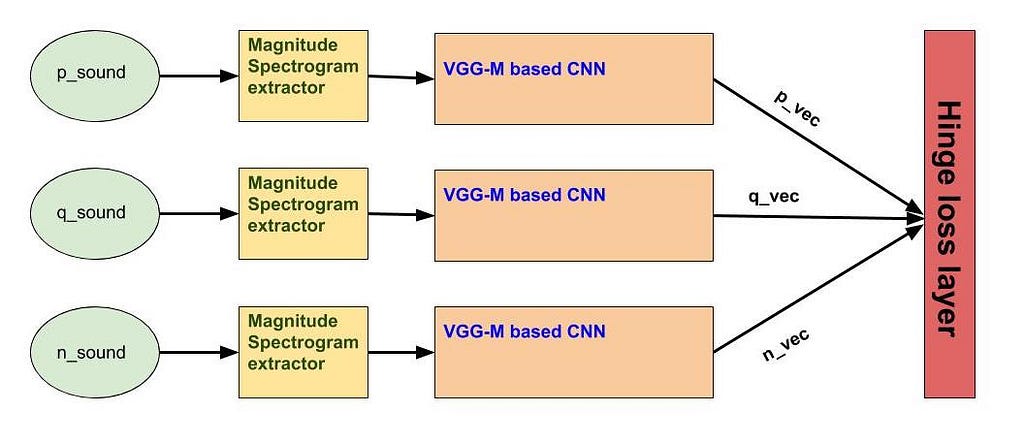
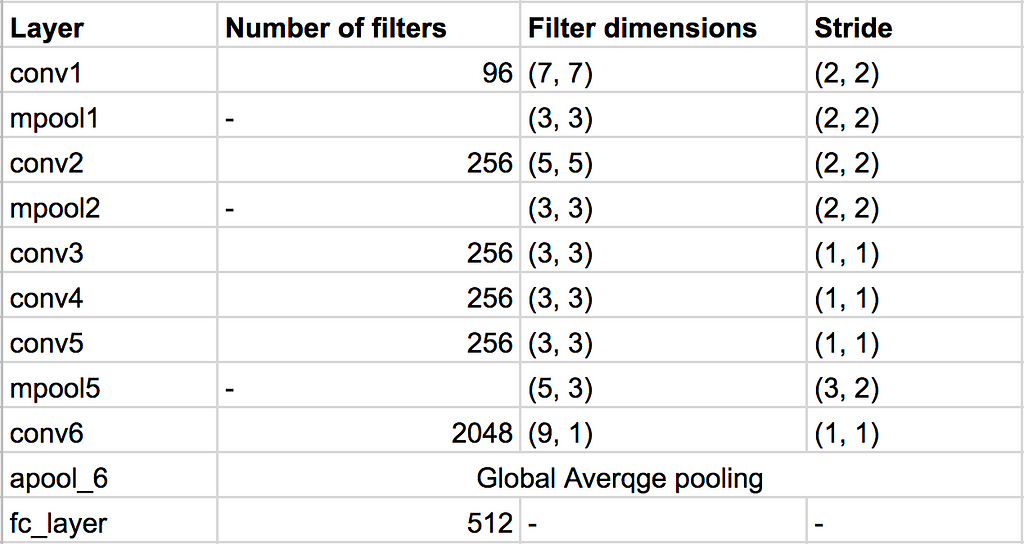
We utilized three VGG-M based CNN architectures [with shared weights] to be trained using triplet loss optimization paradigm in order to learn (dis)similarity between audio recordings of same/ (different) speakers. We call this speaker differentiation pipeline.
To train a speaker differentiation pipeline, on each iteration of model training, a triplet of audio recordings is generated, represented by <q_sound, p_sound, n_sound>. Here q_sound represents anchor audio snippet, p_sound represents some other audio snippet of the same speaker and n_sound represents an audio snippet of a different speaker. Then, magnitude spectrogram for each audio in the triplet is computed and pushed to VGG-M based model described above. All three CNNs share the same weights throughout the optimization process. Lastly, embeddings from the last layer of the network represented by <q_vec, p_vec, n_vec>are pushed to the hinge loss layer defined as:
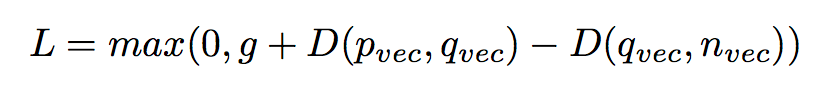 Loss function optimized for speaker differentiation
Loss function optimized for speaker differentiation
In above equation D(x, y) represents the Euclidean distance between two embedding vectors and “g” margin constant in the hinge loss function, is kept equal to 1.
 Speaker differentiation pipeline visualization
Speaker differentiation pipeline visualization
Few gotchas to be careful of in this step:
- Ensure the input magnitude spectrograms are mean and variance normalized along the time axis. Intuitively, each human would have few frequencies which would be more prominent in their voice, which contributes to the unique identity of sound produced by their vocal chords.
- This would ensure that energies corresponding to a frequency bin for different phonemes pronounced over a short time frame are smoothened.
- Use softplus activation function in the last fully connected layer, instead of Relu, if you use Euclidean distance as the distance metric, this is because square root (x) is non-differentiable at 0. Or optimize squared Euclidean distance if you wish to use Relu.
 Base CNN model trained for speaker differentiation
Base CNN model trained for speaker differentiation
One of the key benefits of using this model is that, it will give the same dimension embedding vectors for any length of audio input to the model. However, since the model was trained using batch gradient descent hence during training phase we fixed the audio recordings length at 3s.
The dataset for Training Speaker Differentiation Pipeline:
To train the pipeline, we utilized audio recordings from IVR mission calls that were placed through SquadVoice. We took call recordings of 100 speakers with 12.06 mins of audio per speaker on average, while each IVR recording being 2.41 mins on average.
Additionally, we performed preprocessing on these IVR recordings, like the removal of IVR voice and trimming silence from the end of call recording using sox.
Next, we computed random non-overlapping audio snippets of length between (4.5,s 12.5s), from each audio recording. Thus, generating a total dataset of 8586 audio snippets,
Lastly, we took random 3s crop of audio recordings while passing them as input to the neural net on each iteration and ensured that both train and validation set audio snippets had non-overlapping speaker distribution. That is, there is no speaker whose audio snippet belonged to both train and validation split.
Speaker Change Detection
We applied the learnings from TristouNet work to find speaker change points using the model trained above. We maintained 2 sliding window pairs of left and right sliding windows having duration 3s and moved them at a very small stride of 0.1s. Then, for each left and right window pair, obtained their corresponding magnitude spectrograms and ran them through the CNN trained in step (1) to obtain embeddings for each left and right window pair. Afterward, we computed the Euclidean distance between both left and right embeddings, if the distance exceeds a particular threshold then that would represent a speaker change point. Example, for a 30s audio recording, we would have the following workflow:
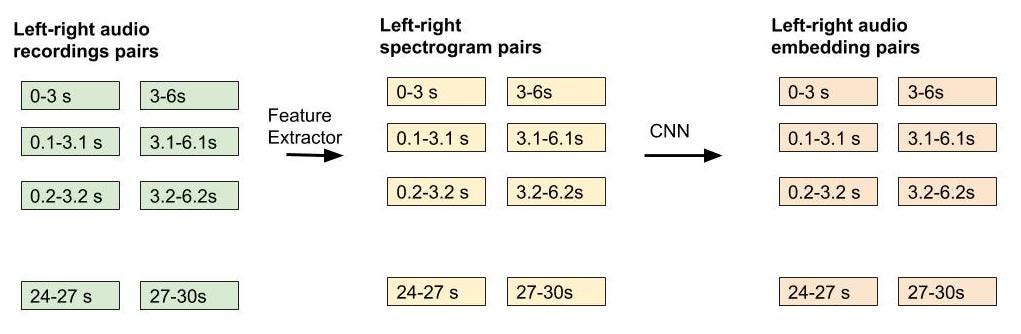 Workflow for speaker change detectionAgglomerative clustering for grouping the audio snippets
Workflow for speaker change detectionAgglomerative clustering for grouping the audio snippets
We broke down the audio as per speaker change points. I.e. if there were 5 speaker change points detected then we split the audio into 6 audio recordings, calculated magnitude spectrograms for the obtained snippets and then computed speaker embeddings using the CNN trained earlier. Later ran Agglomerative clustering on top of these embeddings to group together audio snippets by their speaker.
Experiment Results and Evaluation
This way the complete diarization pipeline was built. When tested on the dataset of 100 call recordings. It had an average diarization error rate [confusion part] of 12.23%, which is quite great as per industry standards. Additionally, the pipeline also performs well in presence of background noise. As examples, have added few sample diarized audio calls with their original versions. The attached recordings are mock calls following actual customer flow.
+---------------+-------------+-------------+---------------+| original call | Calling Rep | Lead | Confusion DER |+---------------+-------------+-------------+---------------+| call_1 | call_1_rep | call_1_lead | 5.5% || call_2 | call_2_rep | call_2_lead | 6.44% || call_3 | call_3_rep | call_3_lead | 6.26% |+---------------+-------------+-------------+---------------+
Acknowledgment
I would like to thank Sanchit Aggarwal, for discussions and reviews of the pipeline design and results of speaker diarization, along with Pragya Jaiswal and Ved Vasu Sharma for design discussions and PR reviews while moving this pipeline to SquadAI codebase. Also would like to thank Squad Voice Operations team for their vital inputs.

Speaker Diarization — The Squad Way was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.