Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.

Automation of routine tasks paves the way to creating truly self-managed environments, where the system itself handles the configuration. Today we discuss how to create self-healing IT infrastructure.
There always is some transition from here to there, some evolutionary process. For example, the next big thing in the automotive industry is the worldwide acceptance of self-driving cars. Despite certain fatal failures from Elon Musk’s Tesla autopilot, Ford plans to produce self-driving cars and Daimler-Benz is already testing self-driving trucks. These manufacturers act according to a 5-step plan to achieve driverless cars.
The hard part of the transition is the attitude shift — the drivers must accept the role of passengers, not the masters of the road. The benefits are supreme, though — fully-automated delivery system working 24/7 and ensuring fewer car crashes and human casualties on the roads. The road to this utopia might seem long, yet the automotive giants cover it with seven-league steps.
5 steps to a self-healing IT infrastructure
What about the IT industry though? The obvious direction of evolvement there is automation. When more and more routine tasks is automated, work hours and resources can be allocated to improving the infrastructure and increasing its performance, not to manually solving numerous tedious tasks. Building the self-healing IT infrastructure capable of performing the routine tasks automatically would simplify the DevOps workflows greatly. The bad thing is, there is no industry-defined roadmap to achieve this state of software delivery. Today we explain our vision on how to create self-healing IT infrastructure.
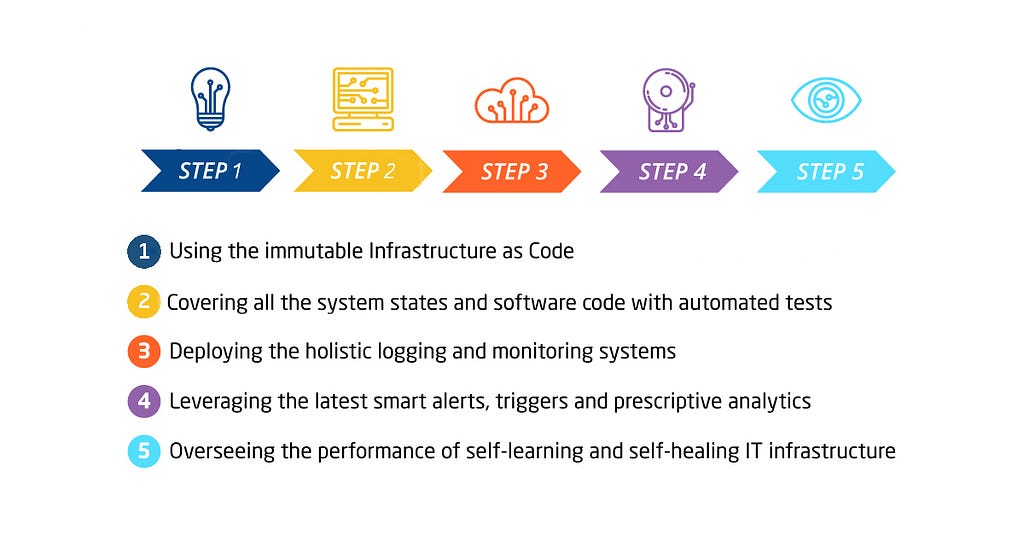
This is the short roadmap of a long process that is most likely going to take around 5–10 years:
- Using the immutable Infrastructure as Code
- Covering all the system states and software code with automated tests
- Deploying the holistic logging and monitoring systems
- Leveraging the latest smart alerts, triggers, and prescriptive analytics
- Overseeing the performance of self-learning and self-healing IT infrastructure
Below we cover these steps in more details.
Immutable IaC as the basis of a self-healing IT infrastructure

One of the most laborious and routine tasks a modern IT engineer has to face is provisioning the servers. It is a time-consuming and highly error-prone process when done manually. Even if the modern-day DevOps teams don’t have to install the physical servers into the racks, they do have to configure them in multiple dashboards before providing the ready development, testing, staging or production environments. Treating the immutable Infrastructure as Code replaces this process with working according to simple, understandable and easily adjustable manifests. Using Kubernetes to manage the Docker containers with applications and Terraform to programmatically deploy and configure the needed servers helps turn a long and error-prone process into a streamlined software delivery pipeline.
Automated testing as the key to keeping the codebase efficient

The shift to the left is one of the hottest DevOps trends of 2018. Instead of leaving the testing and bug fixing close to the end of the software delivery lifecycle, the developers shift all the testing — integration, security, completeness, etc. — to the left across the software creation pipeline. Automated unit tests for the product are written before the development of the product itself begins, and are always updated in parallel with the main development process. Thus said, over time the team has all the product codebase covered by the tests that run automatically, instead of running them manually on the daily basis. Integration testing ensures the system components are stable at all times and new releases will not cause the system failure after being pushed to production.
Logging and monitoring are the keys to self-healing infrastructure

Logging and monitoring tools should be picked on the stage of the system architecture design and integrated with the solution components in order to efficiently collect all the essential details of the DevOps system performance. Detailed logs greatly simplify finding the roots of the issues and building the response manuals. Once a DevOps engineer produces a solution for a specific issue, any system administrator (or even the developer) is able to follow the checklist in the future, lowering the workload of a qualified DevOps specialist. In addition, once the sufficiently large log database is gathered, Machine Learning algorithms can be applied to it to train the system to deal with routine issues automatically.
Smart alerts, triggers, and prescriptive analytics

As the logging and monitoring tools become more sophisticated, they are able to include much more information in error reports. Instead of simply showing if the system component is up or down, modern monitoring tools generate smart alerts with much more detailed information, allowing to cut the problem-solving time by 90%. Once such errors are solved, appropriate triggers can be created along with the prescribed responses for each situation. Due to this approach, multiple repetitive problems can be described and efficiently solved without even requiring the attention of the DevOps team. Most importantly, such triggers can be set for the roots of the issues. This allows preventing the problem instead of dealing with the consequences.
Overseeing the performance of a self-healing IT-infrastructure

The last step of the way to a self-healing IT infrastructure is the process of constantly training the deployed Machine Learning algorithms against the ever-growing base of logs. In a utopian world of 2025+, the DevOps engineers will receive the notifications of the potential issues and approve the solutions offered by the self-healing IT infrastructures. To say even more, this process will also be subject to the machine learning, so with time, there will be less and fewer errors requiring human attention, ensuring stable infrastructure performance and allowing the DevOps teams to concentrate their effort on improving the overall system architectures, not firefighting small issues daily.
Final thoughts of the steps to create self-healing IT infrastructure
Despite this utopian picture, it is least likely the layman DevOps teams will lay their hands on such systems any time soon. The human and financial resources needed to develop a system required to implement this approach is far beyond the reach of an average business. Thus said, as always we have to wait and hope that the industry giants like AWS or GCP will create the platforms similar to AWS Lambda or Kubernetes and open-source them. Only when — and if — it is done, the DevOps talents worldwide will be able to benefit from using the self-healing IT infrastructure.
What do you think on the aforementioned evolutionary process? On what stage of this path does your company or organization currently seems to be? Do you plan to move to the next stage soon? Please share your thoughts and opinions in the comments section below!
Originally published at itsvit.com on September 24, 2018.

How to create a self-healing IT infrastructure was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.