Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
For this guide, we will be using https://github.com/SocketCluster/sc-crud-sample to go through various concepts of real-time CRUD. For part 2, we will only consider the back end of our sc-crud-sample application. For the front end guide, see Real-time CRUD guide: Front end (part 1).
As mentioned in part 1, to implement real-time CRUD on the back end, we need the following things:
- A database (in this case RethinkDB).
- A WebSocket server + client framework which supports pub/sub (SocketCluster).
- A back end module to process CRUD requests and publish change notifications (sc-crud-rethink).
The sc-crud-rethink module is a plugin for SocketCluster; it should be initialized with a custom crudOptions object as argument — this object contains a schema which defines the database entities that are supported by our application and the views through which they can be aggregated.
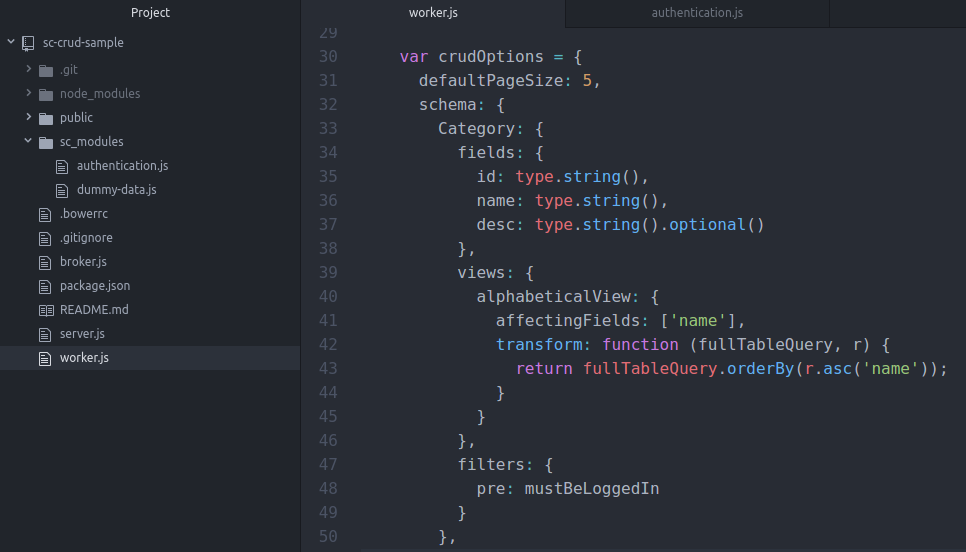
The crudOptions object is defined inside worker.js and is passed to the sc-crud-rethink plugin via the attach method. Our worker.js file looks like this:
^ The crudOptions object contains options that are needed to initialize the sc-crud-rethink plugin. It may have the following properties:
- schema: An object which declares all the entity types and the views that are used by our application.
- logger [optional]: An object to use to log errors and warnings; defaults to console.
- thinkyOptions [optional]: An object to pass to the RethinkDB thinky module when instantiating it.
- defaultPageSize [optional]: The default number of items per page for all views in the system; defaults to 10.
- cacheDisabled [optional]: A boolean which indicates whether or not to disable caching; defaults to false (cache enabled).
- cacheDuration [optional]: The number of milliseconds to cache resources for; defaults to 10000 (10 seconds). Note that although cache updates/invalidates in real-time, it’s a good idea to keep this value short in order to save memory.
- blockPreByDefault [optional]: This is a boolean value which relates to access control (pre middleware filter). It is false by default. If set to true, this option adds an extra layer of security by disabling all CRUD operations unless the relevant pre middleware explicitly allows them. (Access control filters will be explained in more detail later in this guide).
- blockPostByDefault [optional]: This boolean value has the same purpose as blockPreByDefault except that it applies to the post middleware filter instead of pre. It is false by default.
The most important part of the crudOptions object is the schema object; the top level properties of this object represent the different resource types that are supported throughout the system (I.e. Category, Product and User); the name of each resource type represents a table name in our RethinkDB database.
Each resource type definition contains a fields property which defines the fields that can be read from and modified on the underlying resource (along with type information for each field). The views object under each resource type defines all the different ways in which the underlying resource can be aggregated into lists/collections. The filters object allows us to define custom middleware functions to block CRUD operations initiated by various sockets; this is useful mostly for access control (authorization) purposes.
The fields object is declared directly under the relevant resource type. For the Product resource type, the fields definition looks like this:
fields: { id: type.string(), name: type.string(), qty: type.number().integer().optional(), price: type.number().optional(), desc: type.string().optional(), category: type.string()},^ This provides a definition of all the fields which can exist on the resource. The id field should always be provided and must be of type string. Note that some fields can be marked as optional. The sc-crud-rethink plugin uses Thinky for data modeling; so the schema definition under the fields property above corresponds exactly to the schema definition for a model in Thinky.
The views object is declared directly under the relevant resource type. For the Product resource type, the views definition looks like this:
views: { categoryView: { // Declare the fields from the Product model which // are required by the transform function. paramFields: ['category'], affectingFields: ['name'], transform: function(fullTableQuery, r, productFields) { // Because we declared the category field above, it is // available in here. This allows us to tranform/filter // the Product collection based on a specific category // ID provided by the frontend. return fullTableQuery .filter( r.row('category').eq(productFields.category) ) .orderBy(r.asc('name')); } }, lowStockView: { // Declare the fields from the Product model which are required // by the transform function. paramFields: ['category', 'qty'], primaryKeys: ['category'], transform: function(fullTableQuery, r, productFields) { // Because we declared the category field above, it is // available in here. // This allows us to tranform/filter the Product collection // based on a specific category ID provided by the frontend. return fullTableQuery .filter( r.row('category').eq(productFields.category) ) .filter(r.row('qty').le(productFields.qty)) .orderBy(r.asc('qty')); } }}^ Here there are two views — a categoryView and a lowStockView; the purpose of a view is to transform an entire collection of resources from the database into a useful subset which can be consumed by SCCollection components on the front end (and which can be updated in real-time).
The most important aspect of each view is the transform function; the purpose of this function is to construct a RethinkDB ReQL query which will be used by the sc-crud-rethink plugin to generate the view on demand. In the case of the Product resource type, the transform function’s fullTableQuery argument is a ReQL query which, if executed directly, would produce a list of all items in the Product table. For the categoryView, the goal of the transform function is to transform the full table of Product resources into a smaller subset which only contains Product resources that belong to a specific category id — the exact category id to use depends on the productFields.category argument (provided by a front end SCCollection). The r argument which is passed to the transform function can be used to construct ReQL sub-queries and predicates.
Each view declaration can have a paramFields property; this is an array of field names which will affect the view’s transformation depending on values provided by front end SCCollection components (provided through a viewParams object). Using paramFields, a single view definition such as categoryView can be used to represent an infinite number of parameterized views in the form categoryView({category: x}); where x can be replaced with any valid category id — front end SCCollection components will decide what x should be in each case.
The affectingFields property is similar to paramFields in that it is also an array of field names which affect the view’s transformation; the main difference is that fields listed under affectingFields cannot be passed as parameters to the view by front end SCCollection components. If we consider the transform function for the categoryView, we can see that the name field affects the ordering of resources within the view but (unlike with the category field) the name field is only being used in a generic way:
fullTableQuery.filter( r.row('category').eq(productFields.category)).orderBy(r.asc('name'));Under the lowStockView definition, we defined a primaryKeys array — this is necessary because one of our paramFields values (productFields.qty) is used as part of an inequality predicate in our ReQL query: r.row('qty').le(productFields.qty). As mentioned in part 1 of this guide, fields which are used for inequalities cannot be used as identifiers for the view. So in this case we have to be explicit about what the view’s primary keys are to make sure that they do not include the qty field.
Important note: If a view declares a list of primaryKeys explicitly on the back end, then SCCollection components on the front end will need to provide a matching list of field names as viewPrimaryKeys when binding to that view. If a collection doesn’t update in real-time as expected when data changes, it could be because primary key declarations are missing on the front end SCCollection and/or on the back end view schema.
As mentioned earlier, each resource type in the schema definition can have a filters object which can be used to perform access control related to individual CRUD operations (initiated by logic on the front end). The filters object can have a pre and/or a post property — in both cases, these properties should hold middleware functions in the form function (req, next); the req object is an object with the following properties:
- r (RethinkDB r object which can be used to execute database queries)
- socket (SocketCluster socket which initiated the CRUD operation)
- action (‘create’, ‘read’, ‘update’ or ‘delete’)
- query (a valid CRUD query should always have a type property, it may also have various combinations of id, field, view or viewParams properties depending on the specific kind of CRUD operation that is being performed — this is because some operations relate to an individual resource or an individual field within a resource while others relate to a view/collection).
The next argument passed to the middleware function is a callback; we can invoke this callback with an error object (to block the CRUD operation) or without arguments (to allow the CRUD operation to proceed).
The difference between pre and post filters is that pre filters do not need to query the underlying resource on the database before they run; on the other hand, post filters will fetch the underlying resource from the database before they run (which adds extra overhead). Note that in the case of the post filter function, the req object has an additional resource property which holds the underlying resource from the database.
In the schema, under the Product resource type, both a pre and a post filter are specified:
filters: { pre: mustBeLoggedIn, post: postFilter}The mustBeLoggedIn filter function looks like this:
function mustBeLoggedIn(req, next) { if (req.socket.authToken) { next(); } else { next(true); req.socket.emit('logout'); }}^ It checks if the socket has a valid JWT socket.authToken; if so, it will allow the CRUD action to proceed, otherwise it will block the CRUD action and will trigger a logout event on the client socket (to remove any stale tokens and to prompt the user to login).
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.