Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
This article proposes an easy and free solution to train a Tensorflow model for instance segmentation in Google Colab notebook, with a custom dataset.
Previous article was about Object Detection in Google Colab with Custom Dataset, where I trained a model to infer bounding box of my dog in pictures. The protagonist of my article is again my dog: in this case we take a step forward, we identify not only the bounding box, we make even pixel wise classification.
 Instance segmentation with my dog
Instance segmentation with my dog
Compared to previous article, we hold the same characteristics:
- Only requirement is the dataset, created with annotation tool
- A single Google Colab notebook contains all the steps: it starts from the dataset, executes the model’s training and shows inference
- It runs in Google Colab (GPU enabled environment) and Google Drive storage, so it’s based exclusively on free cloud resources
These features allow anybody following this tutorial to create an instance segmentation model, and test it in Google Colab or export the model to run in a local machine.
Source code of this article, including the sample dataset, is available in my Github repo.
Choosing Framework
There are various open source frameworks to implement instance segmentation, you can find an overview in this presentation of Stanford University.
We discard solutions that are not based on Tensorflow, such as Facebook Detectron based on Caffe2, because we decided to train the model in Google Colab, that is already integrated with Tensorflow.
One of the most popular frameworks, easy to use and well documented, is Matterport Mask R-CNN. From my tests it’s one of the simplest and most robust implementations available.
In addition, a big effort I faced with other implementations is to convert the annotations output file to framework input format. To be clear, once you create the pixel annotations of dataset with a graphical tool, you should convert it to input format defined by training framework.
Matterport developed this task in a clear article, demonstrating how to transform annotations file to Matterport Mask R-CNN format.
Making Dataset
In previous article we created bounding box annotations to obtain object detection model, now we are going to train instance segmentation model, therefore we create pixel level mask annotations to define the boundaries of the objects in dataset. Among various available tools, I chose an intuitive and well done tool: VGG Image Annotator (VIA) by University of Oxford, you can see documentation in the official page of the project. Furthermore, it’s easy to integrate VIA with Matterport framework.
This tool doesn’t need any installation, you just download the package and open the via.htmlfile with a modern browser.
It’s important to create a good dataset to achieve a well performing trained model. Taking pictures of objects with different lighting conditions, from various angles and in different contexts, are good principles to obtain a well generalized model, and avoid overfitting.
 Dataset of dog
Dataset of dog
At the end of the annotation process, I created “images.zip” file with the following structure:
images.zip|- "train" directory |- jpg image files of training data |- "via_region_data.json" annotations file of training data|- "val" directory |- jpg image files of validation data |- "via_region_data.json" annotations file of validation data
Lastly I uploaded zip file into Google Drive, to use it during the training and test process. I included the dataset file in my Gitub repo, having pixel wise annotations of dog images.
Training Model
All the steps are in Google Colab notebook included in my repo. In my example, training process last about half an hour for 5 epochs, to get a more accurate model you can increase the number of epochs and the dataset size.
I selected Python3 GPU enabled environment, to use up to 12 hours of Tesla K80 GPU offered in Google Colab. Next steps in notebook are:
Install required packages: install packages, repositories and environment variables for Matterport instance segmentation with Tensorflow.
Download and extract dataset: download images.zip dataset in Google Colab filesystem, previously uploaded in Google Drive. Update fileId variable with Google Drive id of your image.zip dataset.
Edit settings file: code in my repo is inspired by Matterport Splash of Color sample, to run with a different dataset you should replace occurrences of “balloon” and “Balloon” with the name of object.
Train model: use pretrained weights to apply transfer learning in training process. Options are COCO and ImageNet.
Training process outputs the structure of neural network and various parameters, like the network architecture (Resnet50 or Resnet101).
Using TensorFlow backend. Weights: coco Dataset: dataset/ Logs: /logs
Configurations: BACKBONE resnet101 BACKBONE_STRIDES [4, 8, 16, 32, 64] BATCH_SIZE 2...GPU_COUNT 1 GRADIENT_CLIP_NORM 5.0 IMAGES_PER_GPU 2...Selecting layers to train fpn_c5p5 (Conv2D) fpn_c4p4 (Conv2D) fpn_c3p3 (Conv2D) fpn_c2p2 (Conv2D) ...
Below the Tensorboard charts of training process:
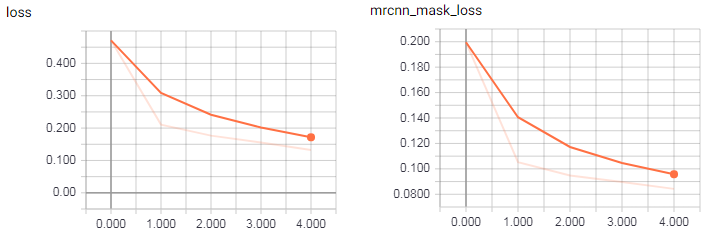 Tensorboard charts
Tensorboard charts
Inference
Finally we can run test dataset inference with trained model.
Output includes inference data (image resolution, anchors shapes, …), and test images with bounding box, segmentation mask and confidence score.

Conclusions
If you want to run instance segmentation on a single object class, you can make a few minor changes to my Github code and adapt it to your dataset.
I hope you liked this article, in case leave some claps, it will encourage me to write other practical articles about machine learning for computer vision :)

Instance Segmentation in Google Colab with Custom Dataset was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.