Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.

The next article in our series of publications on AI development examines the latest Dbrain use case for “Dodo Pizza”, the biggest Russian pizza chain. Arthur Kuzin, our Lead Data Scientist, explains how the developed AI runs pizza quality control through a Telegram messenger by assigning pizza dough a score from 1 to 10. Dive in and find out how to teach AI to evaluate your pizza!.
I’ll focus here on the following: i) getting the markup for the full dataset from only a few labeled samples; and ii) stretching bboxes to segmentation masks of the object (applying the square mask of bboxes to any shape).
Main idea
So here is the deal. Dodo pizza has a number of active customers, which agreed to share their opinion about the quality of pizza they get. To simplify the feedback loop and its processing, Dbrain developed an AI-driven application to examine pizza quality. This application is realized as a chatbot in Telegram, where customers upload a photo and get the result on a scale from one to ten.
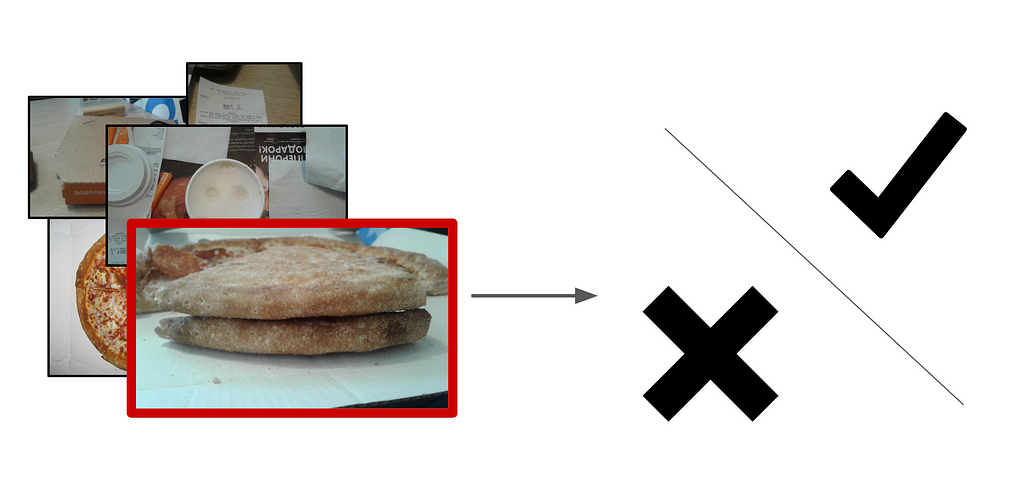
Problem statement
As we got the request, I proceeded to develop an algorithm that could visually determine the dough quality. The problem was to identify when the pizza baking process was disrupted. It appears that white bubbles on the crust correlate with the spoiled product.
Data mining
The dataset comprised the photos of pizza baking and also included irrelevant images. In case the recipe was incorrect white bubbles appeared on the crust. Also, there was a binary marking of the dough quality performed by specialists. So the development of the algorithm was only a matter of time.
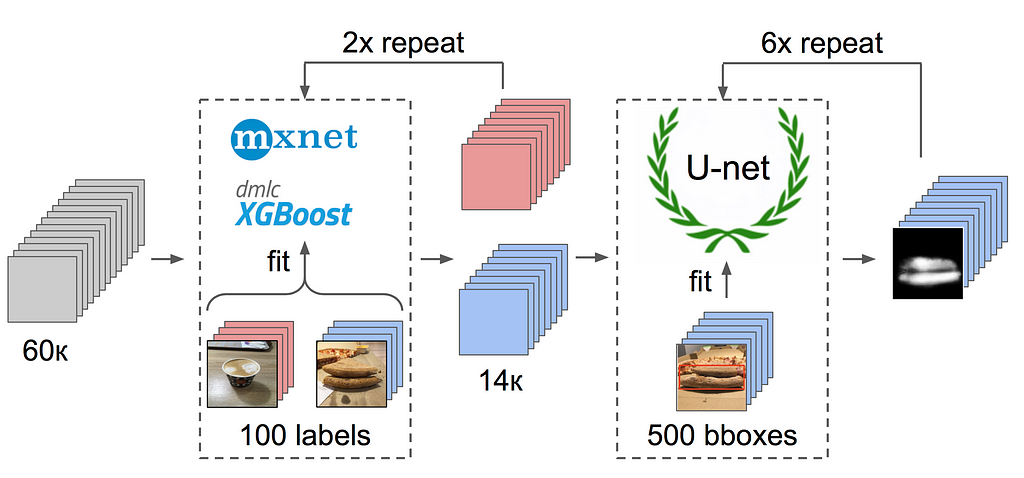
The photos were taken on different phones, under different light conditions, and from different angles. There were 17k of pizza specimens while the total number of pictures was 60k.
Since the task was quite straightforward, it was a nice playground to check out different approaches to handling data. So, here’s what we needed to resolve the task:
1. Select photos where pizza crust is seen;
2. Distinguish the crust area in the selected photos from the background;
3. Train the neural network on selected areas.
Data filtering
I labeled a small part of photos by myself instead of explaining to other people what I really needed, because… you know, if you want a thing well done, do it yourself :) Here’s what I did:
1. Marked 50 photos with the crust and 50 without:

2. Extract features after global average pooling using the ResNet-152 pretrained on imagenet11k with places365 (click)
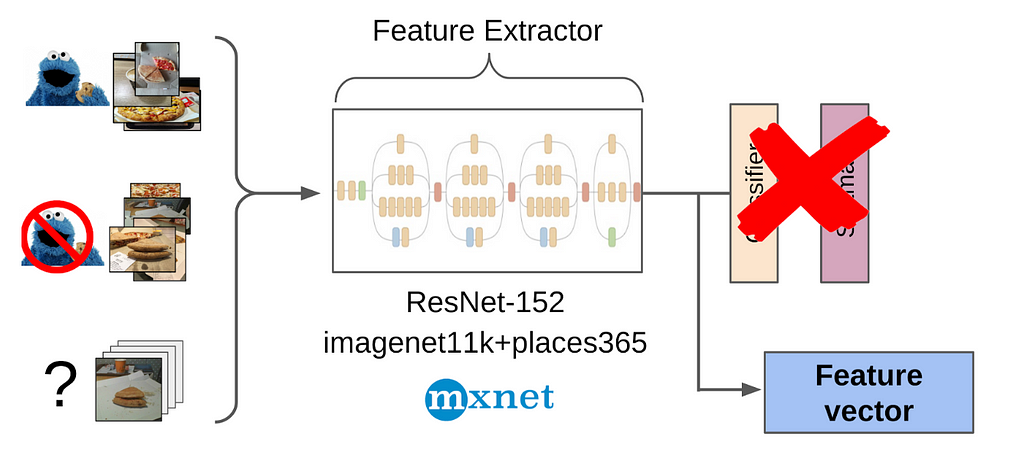
3. Took the average of the features for two classes as an anchor
4. Calculated the distance from this anchor to all of the features of the remaining 60k pictures
5. Determined the top 300 were relevant in proximity to the positive class, the top 500 of the most distant ones are the negative class
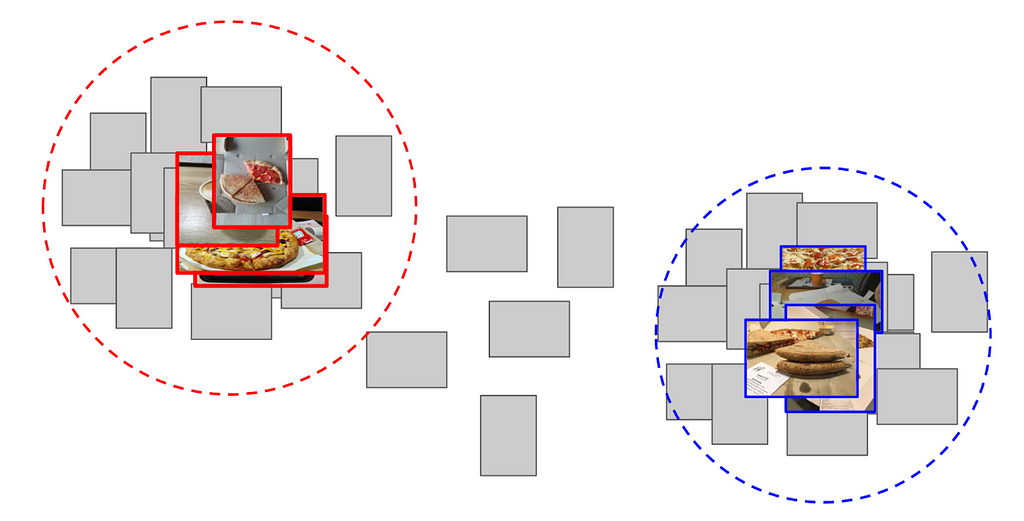
6. Trained LightGBM on the features based on these samples
7. Derived the markup on the whole dataset using this model
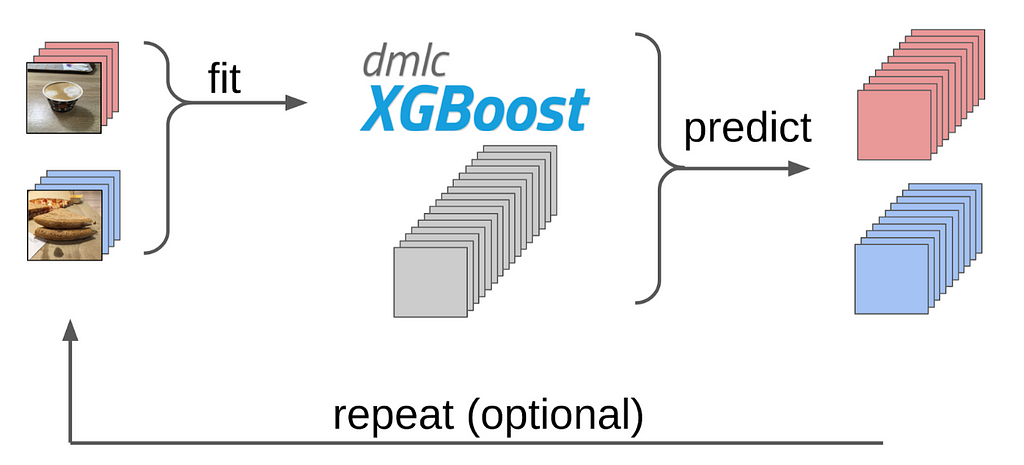
It is approximately the same approach that I used as a baseline in kaggle competitions.
Prequel
About a year ago I took part in the “Sea Lions” kaggle competition together with Evgeny Nizhibitsky. The task was to count fur seals on the images taken from the drone. The markup was given simply as coordinates of carcasses, but at some point, Vladimir Iglovikov marked them up with bboxes and shared it generously with the community.
I decided to solve this task through segmentation having only bboxes of the seals as a target at the first stage. After several training iterations it was easy to find some hard samples where everything is bad.

For this sample you could choose large areas without seals, set the masks manually to zeros, and also add to the training sets. And so iteratively, Evgeny and I trained a model that has learned to even segment fins of fur seals for large individuals.

Crust detection and extraction
Back to pizza again. In order to identify crust on the selected and filtered photos, the optimal option would be to give the task to the markers. Generally, some labelers work differently with the same sample, but at that time we had already applied the consensus algorithm for such cases and used it for bboxes. That’s why I just made a couple of examples and gave it to the labelers. In the end, I got 500 samples specifically with the area of crust highlighted.
To identify the crust on the selected filtered photos I made a couple of examples for the labelers to follow.
Then I applied my code from the Kaggle Sea Lions competition more formally to the current procedure. After the first iteration of training it was still clear where the model was wrong. The confidence of the predictions was defined as follows:
1 — (area of the gray zone) / (area of the mask)
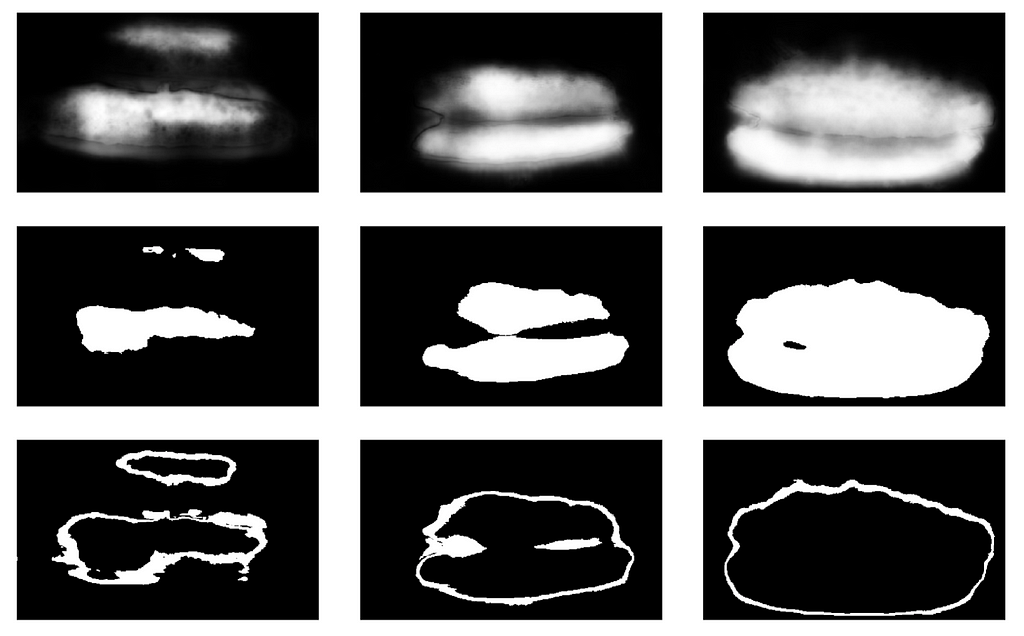
Next, to do the next iteration of approaching the boxes to the mask, a small ensemble predicted the masks with TTA. This could be considered as WAAAAGH-style knowledge distillation to some extent, but it would be more correct to call it Pseudo Labeling.
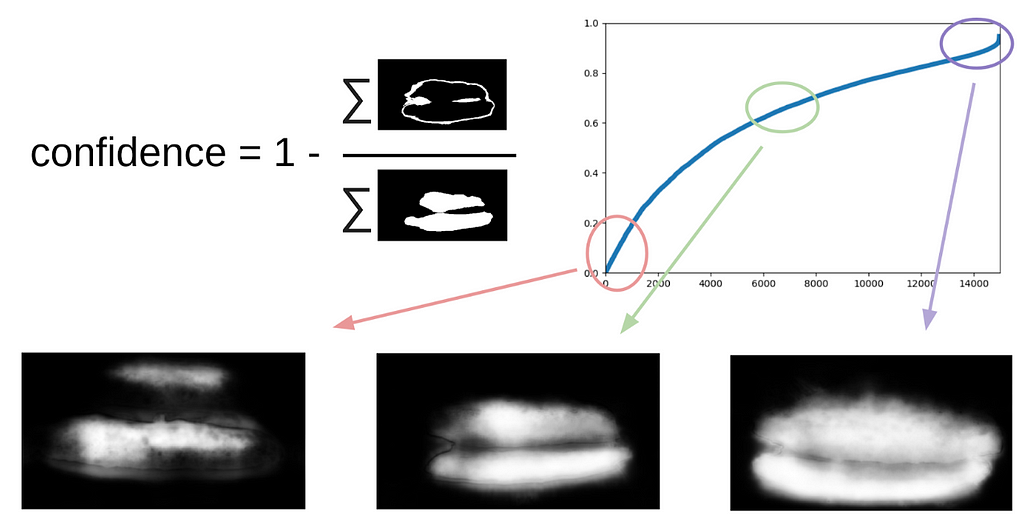
I had then to identify by hand a certain threshold for the confidence which we would use to form a new training set. It was also optional to mark out the most complicated samples with which the ensemble failed. I decided that would be useful and marked about 20 pictures myself while digesting lunch.
Final model training
At last — the final model training. To prepare the samples, I extracted the area of crust with the mask. Also I slightly inflated the mask by dilating it and applied it to the picture to remove the background, since it should not contain any information about the quality of the dough. Then I fine-tuned several models from Imagenet. In total, I collected about 14k of proper samples. Therefore, I did not train the entire neural network but only the last group of conv layers to prevent overfitting.
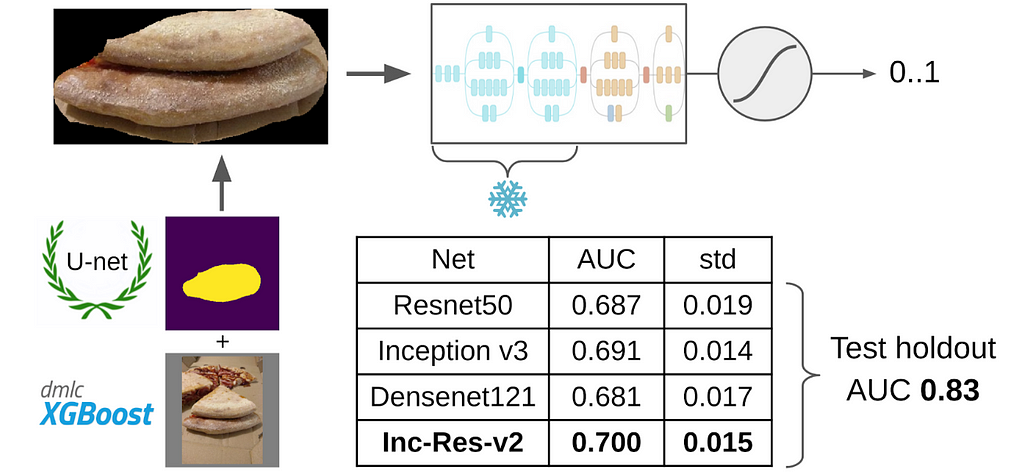
The best single model turned out to be Inception-Resnet-v2, and ROC-AUC for it on singlefold was 0.700. If you do not select anything and train net on raw photos without masks, then ROC-AUC would be 0.58.
Validation
While I was developing the solution, DODO pizza were back with the next batch of data, and it was possible to test the entire pipeline on an honest holdout. We tested the whole pipeline on it and got ROC-AUC 0.83.
But still, we couldn’t manage without mistakes. And taking into account the reasons of their appearing I trained the model once more and achieved the positive results. Let’s now look at the errors:

It can be seen here that they are associated with a crust marking error because there are clear signs of spoiled dough.
 Top False Negative
Top False Negative
Here errors were due to the failure of the first model to choose the right point of view, which led to difficulties defining the key features of quality dough.
Conclusion
My colleagues sometimes tease me for solving almost all tasks by segmentation using Unet. But I keep alive the hope they will love it because this is a rather powerful and convenient approach. It allows visualizing model errors and predicting them with confidence, which sometimes can really save the day. Plus, the entire pipeline looks very simple and now there is a bunch of repositories available for any framework.
That was it. It’s now time to grab a slice of pizza and chill out. Cheers!

Your Pizza is Good: How to Teach AI to Evaluate Food Quality was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.