Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Featuring the Metropolitan Museum of Art and the Cloud Vision API
BigQuery is a data warehousing solution provided by Google Cloud. Organisations use data warehouses to gather several sources of data into a single entity, as well as to reshape them into SQL databases with business-oriented schemas.
This allows collaborators of an organization to gain access to multiple sources of analysis-ready data through a unique service, at a few SQL queries away.
Thus, cross-source data analysis is easily enabled.
This type of service comes in to be very useful for any data-driven company function, in particular Business Intelligence Analysts or Data Scientists.
BigQuery also comes with public datasets (eg. hackernews, stackoverflow or github_repos). What is best is that the list keeps being updated on a regular basis.
If you are new to BigQuery and would like to explore these open data, you can find valuable information here: try BigQuery for free.
In addition, are some pointers to interesting analysis of BigQuery public datasets from Felipe Hoffa:
- All the open source in Github now shared within BigQuery: Analyze all the code!
- These are the real Stack Overflow trends: Use the pageviews
- Who contributed the most to open source in 2017? Let’s analyze Github’s data and find out.
I have personally been working with BigQuery for almost a year as part of my work and here are some learnings I picked up along the way, which you may find useful. To support my statements, I will use public dataset bigquery-public-data.the_met.
The dataset
The the_met dataset gathers data from 200k art objects from the Metropolitan Museum of Art of New York. The data consists in object metadata as well as picture representation.

On top of that, all of the images have been annotated thanks to the Cloud Vision API: this API features several pre-trained computer vision models, providing rich visual information (among which image classification, face detection and localisation, Optical Character Recognition).
These annotations are made available in the dataset and contain a lot of nested fields, making of it a great playground to wrangle with data.
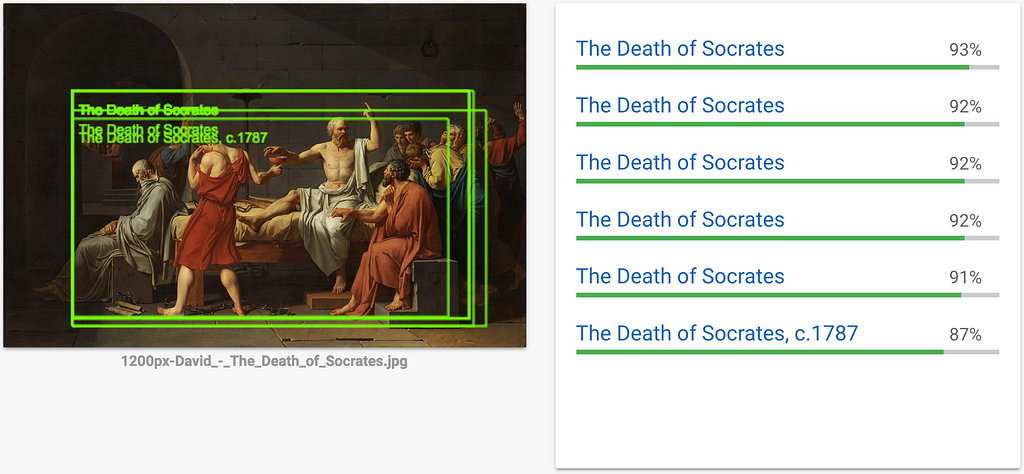 Logo Detection request to Cloud Vision with The Death of Socrates, David (1787)
Logo Detection request to Cloud Vision with The Death of Socrates, David (1787)
The dataset consists of 3 tables:
- the_met.images for image url
- the_met.objects for object metadata
- the_met.vision_api_data for vision api-generated annotations
The common key is the object_id.
More information about the_met is available in this post from Sara Robinson.
How about the tricks?
The tricks described here do not necessarily address complicated cases. They are rather intended to help you write shorter and more efficient queries, often times with overlooked commands.
The topics we will cover are as follows:
- Idempotently split table lines at random
- Shorten your queries with EXCEPT
- Modify arrays inline with ARRAY
- When SQL cannot handle it, just JS it
- Bonus part on BigQuery ML
Disclaimer: The following examples will be using Standard SQL, which, in general provides more features than BigQuery Legacy SQL. They assume you are already familiar with BigQuery, row aggregation, records, repeated fields and subqueries.
1. Idempotently split table lines at random
When experimenting with Machine Learning and BigQuery data, it may sound useful to be able to randomly split tables, with a given fraction.
It is even better if the query is idempotent: whenever it is ran, no matter how many times, the result will remain the same.
The use case arises when splitting a dataset into Training and Development sets.
For instance, let us perform a 80–20 split of the_met.objects. The idea lies in hashing a column field present in all rows and unique for each of the rows, eg. with FARM_FINGERPRINT .
The arithmetic properties of the integer hashes can then be exploited to discriminate lines idempotently.
For 20% splits, the modulo 5 value can be used. Here, this field could be object_number.
The above query returned 80221 lines out of 401596 (ie. 19.97%). Yay!
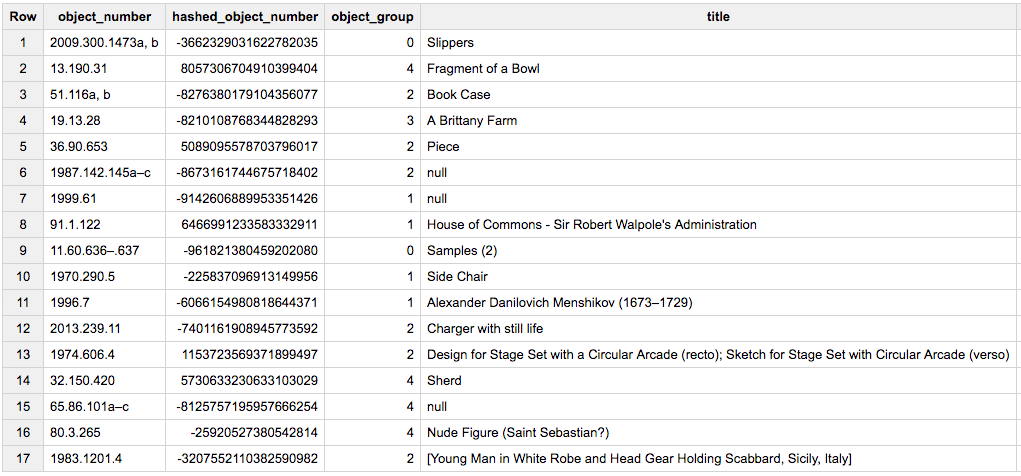 Samples of objects with their number, FARM_FINGERPRINT hash, corresponding group and title
Samples of objects with their number, FARM_FINGERPRINT hash, corresponding group and title
2. Shorten your queries with EXCEPT
An often overlooked keyword is EXCEPT. This allows you to query all columns except a subset of them.
It proves useful when the table schema is very furnished, like in the_met.objects .
For example:
Another example with the image annotations available in the_met.vision_api_data. Among the available annotations, there are the faceAnnotations:
 Schema for `face_annotations` in `the_met.vision_api_data`
Schema for `face_annotations` in `the_met.vision_api_data`
What if we were interested in all columns except faceAnnotations.surpriseLikelihood and faceAnnotations.sorrowLikelihood, would this query work?
In practice, this query is not allowed as it references a nested field in EXCEPT. faceAnnotations needs to be UNNESTed before referencing.
The above query works but faceAnnotations are now unnested.
The next section shows how to perform the task while preserving the nested structure, thanks to keyword ARRAY. In general, maintaining nested structures turns out to be more cost-effective in terms of storage and processing power, compared to fully flattened tables.
3. Modify arrays inline with ARRAY
In BigQuery, ARRAY fields (aka. REPEATED fields) refer to columns for which one line can have several corresponding values. For instance, in vision_api_data , one object can correspond to several faceAnnotations :
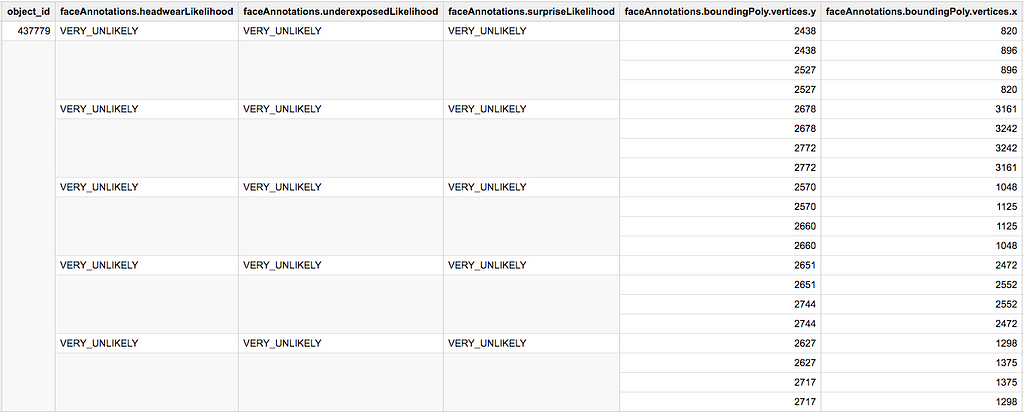 To one line (=one `object_id`) can correspond several `faceAnnotations`
To one line (=one `object_id`) can correspond several `faceAnnotations`
You may know about ARRAY_AGG or ARRAY_LENGTH, but have you heard of often overlooked ARRAY?
According to the documentation, ARRAY(subquery) returns an ARRAY with one element for each row in a subquery. Let us look at several use cases.
3.1 Filter out a nested field, while keeping the nested structure
Let us tackle the previous example once again, but with a more elegant approach this time.
Notice that SELECT AS STRUCT is necessary when querying multiple columns within an ARRAY clause.
3.2 Filter lines in an ARRAY field
This time, instead of filtering out columns, we will filter out lines within an ARRAY, based on a condition on a nested column.
Assume we are not interested in faces which are very likely to be under-exposed (ie. underExposedLikelihood='VERY_LIKELY').
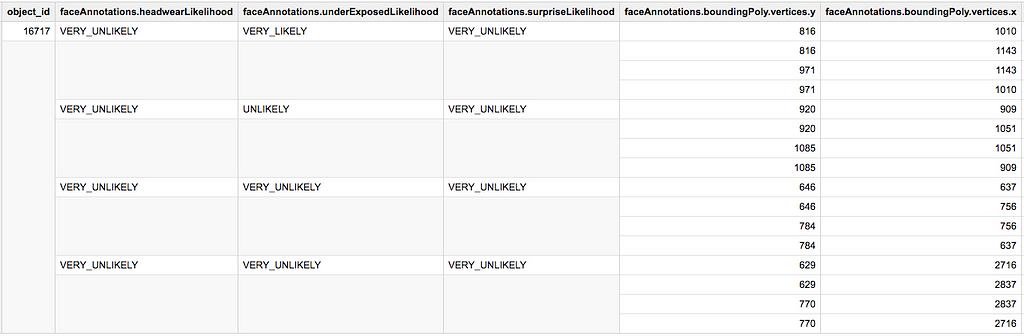 Above: `faceAnnotations` before `WHERE` filtering
Above: `faceAnnotations` before `WHERE` filtering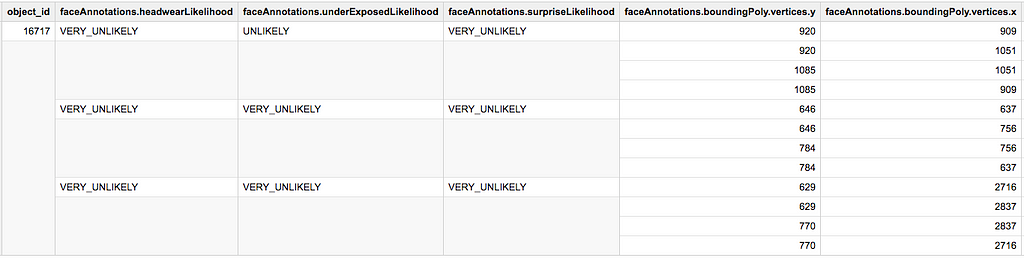 Above: `faceAnnotations` after `WHERE` filtering3.3 Enrich an ARRAY with a JOIN ON a nested field
Above: `faceAnnotations` after `WHERE` filtering3.3 Enrich an ARRAY with a JOIN ON a nested field
On the top of the face annotations, the Cloud Vision API provides with web detection features, similar to Google Image reverse search.
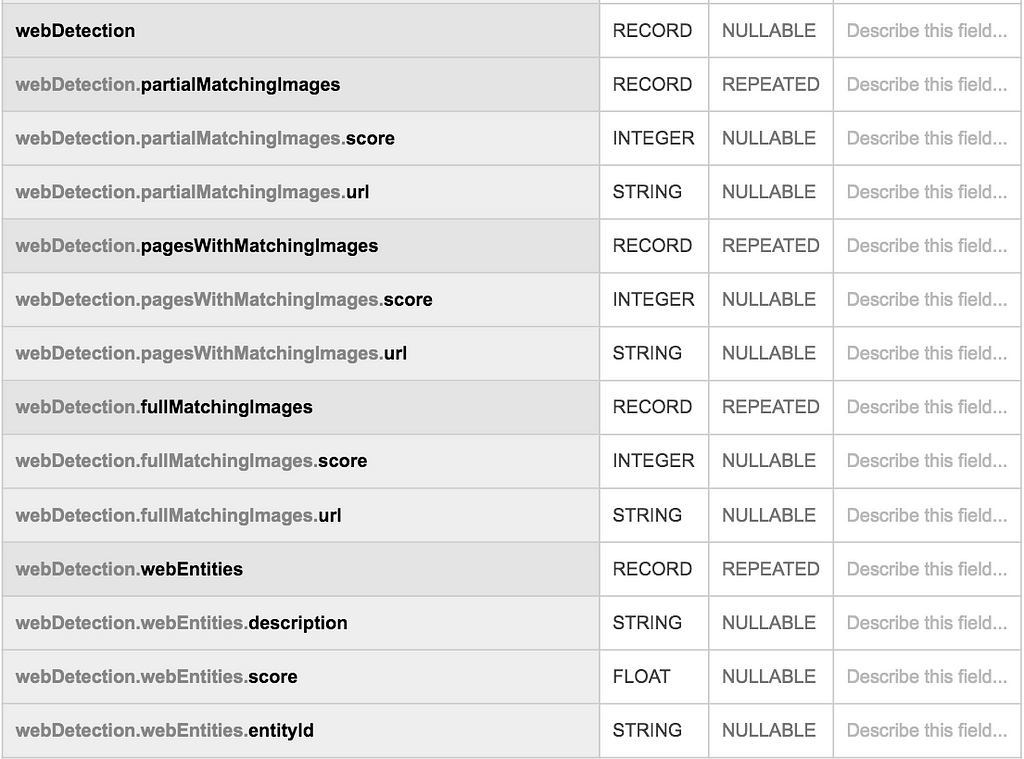 `webDetection` schema
`webDetection` schema
Let us enrich this schema with matching object_id from the_met.images (image urls of the museum objects). This is target schema:
 Target enriched `webDetection` schema
Target enriched `webDetection` schema
The corresponding query
and the result
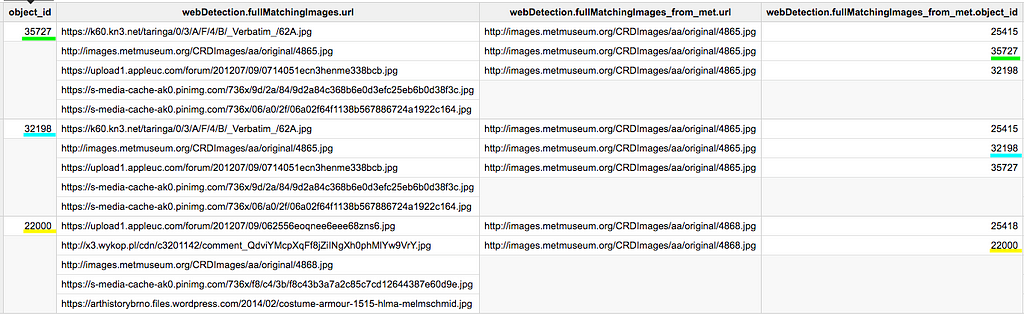 Samples of the `webDetection` schema enrichment. The output schema has been simplified for readability.
Samples of the `webDetection` schema enrichment. The output schema has been simplified for readability.
From there you could, for instance, evaluate image retrieval performance of Google’s reverse image search.
4. When SQL cannot handle it, just JS it
BigQuery allows you to write your own User-Defined Functions (UDFs) in JavaScript, which can prove useful when StandardSQL does not support what you are trying to achieve.
For instance, we could be interested in extracting, from vision_api_data, the labelAnnotation with the second highest score, for each object_id. In StandardSQL, you can select top lines but not the second top line (at least not in a single query).
This can be achieved with
The result
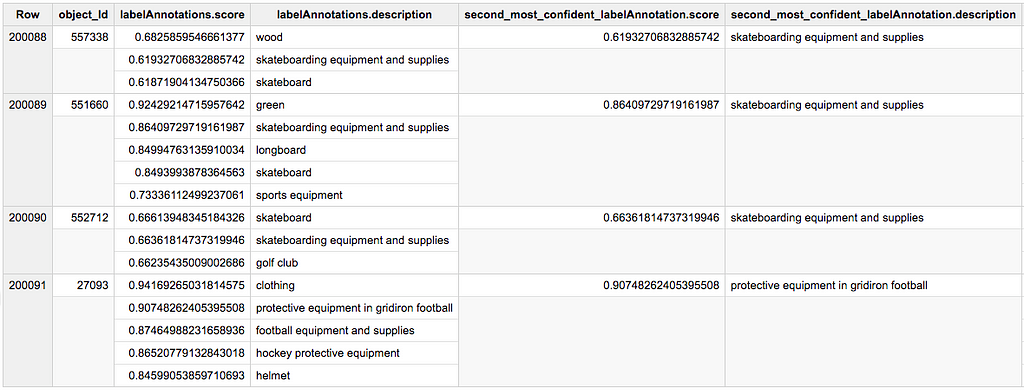 We prepended the table schema with the argument of the UDF for convenience.
We prepended the table schema with the argument of the UDF for convenience.
Note that UDFs, at the time this post was written, are not supported in BigQuery views.
5. Bonus part on BigQuery ML
BigQuery ML is one the newest features of BigQuery. It allows you to build, train, deploy Machine Learning models only with a few SQL commands. This can save you the time of building data pipelines and perhaps spinning up other services like Google AppEngine.
For the sake of the example, let us see if some of an object’s metadata can be good predictors of whether or not a face is represented on it.
 Logistic Regression task: predict whether or not an art piece has a face representation
Logistic Regression task: predict whether or not an art piece has a face representation
We will rely on the Cloud Vision API for ground-truth labelling of presence of a face:
IF( ARRAY_LENGTH(faceAnnotations)=0 OR faceAnnotations IS NULL , 0 , 1) AS label
We will use a linear logistic regression for this purpose.
Creating a model on BigQuery is as simple as pre-pending your training set query with a few commands.
Provided you have created a dataset named bqml (if not, create it), the syntax looks like the following:
Notice the mixture of types in the input features: STRING, BOOLEAN, INTEGER.
By default, BigQuery handles this diversity with no problem by one-hot encoding the non-numerical features. Also notice we have used the above-mentioned idempotent splitting trick to train the model on 80% of the data.
After training, let us evaluate the model on the development set (the other 20% of the data) with:
The evaluation query returns
[ { "precision": "0.6363636363636364", "recall": "4.160228218233686E-4", "accuracy": "0.8950143845832215", "f1_score": "8.315020490586209E-4", "log_loss": "0.3046493172393632", "roc_auc": "0.857339" }]As a side note, the prior distribution is the following:
[ { "pc_with_faces": "0.1050043372170668", "pc_no_faces": "0.8949956627829332" } ]Given the very low recall score and that the accuracy score barely exceeds the prior distribution, we cannot say the model has learnt from the input features 😊.
Nevertheless, this example can be used as an intro to BigQuery ML.
To improve model performance, we could have looked at string preprocessing and factoring for fields like culture and classification. Other unstructured description text fields could have been exploited but this goes beyond the current scope of BigQuery ML.
If you are keen to serve Machine Learning in the cloud, but find BigQuery ML to be limiting, you may find my previous article useful.
At the time this post was written, BigQuery ML was available as a beta release.
And that is a wrap! Thank you for reading this far. I really enjoyed sharing those learnings so I hope they will be useful to some.
At Sephora South-East Asia (Sephora SEA), we leverage BigQuery to enable easier data-backed decisions as well as to better understand our customers.
The Data Team at Sephora SEA takes care of internally democratising data as much as possible, in part through SQL trainings on BigQuery.
This article is dedicated to them, as well as to all of our trainees and past graduates.
And as my colleague Aurélien would proudly say:
SELECT thanks FROM you
Photos credits: kevin laminto on Unsplash

BigQuery: level up your queries with these advanced tricks was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.