Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Best practice from Alibaba’s caching technology team on how to best deploy non-volatile memory(NVM) to production environments

Effective data storage is essential in any computing task, but when you run a multi-sector ecosystem of e-commerce platforms serving billions of consumers, there is simply no substitute for it. For Alibaba who runs the world’s largest online marketplaces, that meant developing its own package of non-volatile memory (NVM) caching services collectively known as Tair MDB, first launched to support the Tmall 6.18 online shopping festival before undergoing optimization for broader rollout.
To diagnose necessary improvements, the Tair team subjected the system to two full-link pressure tests, exposing a range of problems including imbalanced writing and lock overhead. Today we look more closely at the fundamentals of NVM as found in Alibaba’s production environment, with emphasis on best practices uncovered during their optimization work. As well as three strategic design rules which can help ensure long-term operability, readers working in related areas will find abundant insights on NVM optimization widely applicable to other products.
The Case for NVM
At the time of NVM’s adoption, Tair MDB was already widely deployed within the Alibaba Group. With the introduction of its user space network protocol stack and lock-free data structure, the QPS limit of a single unit had pushed beyond the 1000-watt caliber. All Tair MDB data was stored in memory, with the elevated single-unit QPS limit making memory capacity the most important factor determining cluster size.
NVM offered a much higher single DIMM capacity while also being far less expensive than DRAM, indicating a possible approach to breaking the limit for single-unit memory capacity.
NVM Enters the Production Environment: Initial Results
End-to-end, with an average reading and writing latency level using DRAM’s node data under the same software version, services proved able to run as normal using NVM, and pressure for the production environment was well below the Tair MDB node limit. In subsequent sections, problems encountered during the pressure test and the approaches taken to solve them will be explained in greater detail.
As previously mentioned, the maximum DIMM capacity of a single NVM is higher than that of DIMM, translating into lower cost for the same DIMM capacity than with DRAM. Using NVM to make up for insufficient memory capacity, it was possible to greatly reduce the size of the Tair MDB-capacity cluster. When factoring in device costs, electricity fees, and racks, overall costs were reducible by 30 to 50 percent.
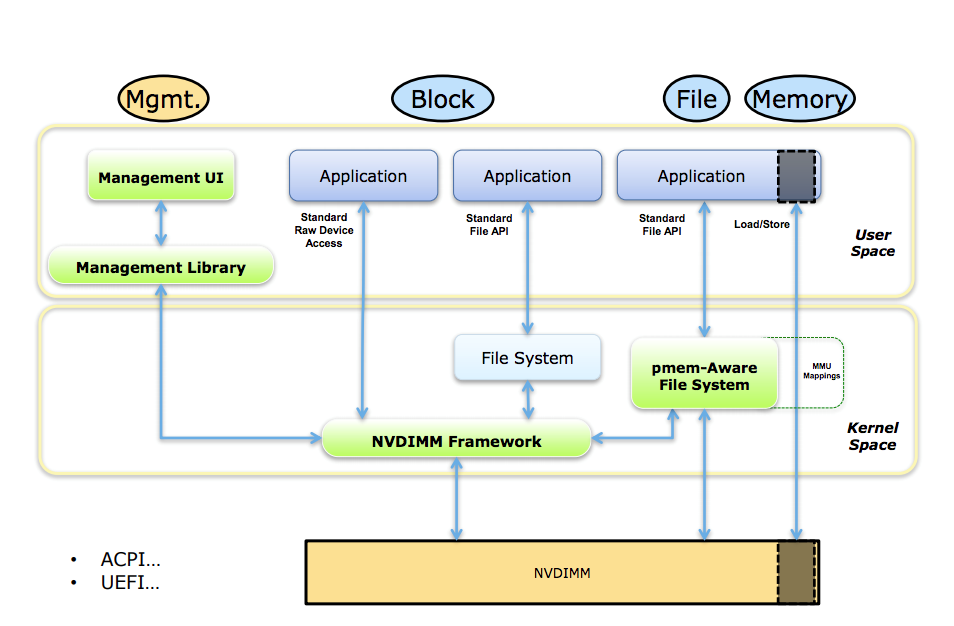
Principles in Action: A Guide to Implementing NVM
Tair MDB uses NVM as a block device while using PMem-Aware File System mounting (DAX mounting). When allocating NVM space, the first step is to create and open the file in the corresponding file system path, and use posix_fallocate to allocate space.
 First considerations: The memory allocator
First considerations: The memory allocator
NVM is intrinsically non-volatile. The caching service Tair MDB recognizes NVM as a volatile device, without need to consider the atomicity and post-crash recovery, or to explicitly call commands like clflush/clwb to forcefully flush CPU Cache contents back to medium.
When using DRAM space, memory allocators such as tcmalloc/jemalloc are optional. NVM space exposes a file (or a character device) to the upper layer, so the first consideration is how to use the memory allocator. The open source program pmem[1] protects the volatile memory management library libmemkind, and easy-to-use APIs that are similar to malloc/free. This mode offers a good option when switching in most apps.
Implementation of Tair MDB did not use libmemkind[2]. To explain this choice, the Tair MDB memory layout is introduced in the following section.
Memory layout
Tair MDB employs the slab mechanism for memory management, which does not allocate anonymous memory dynamically when in use, but rather allocates a large memory when the system starts. Subsequently, built-in memory management modules continuously distribute metadata and data pages across this large memory block, as shown in the diagram below:
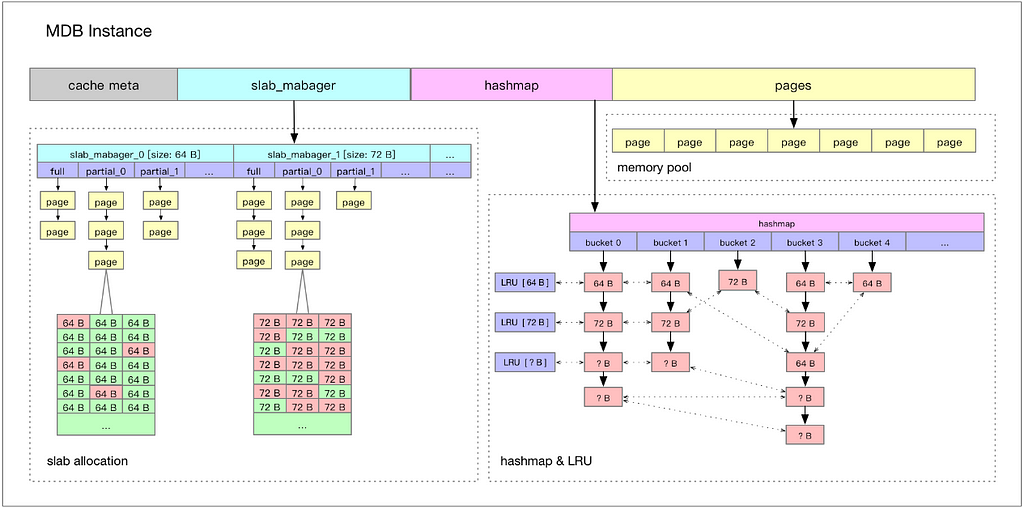
Tair MDB’s memory use is divided into the following portions:
· Cache Meta: This stores metadata information such as the maximum number of shards, and index information for the Slab Manager.
· Slab Manager: Each Slab Manager manages a Slab of a fixed size.
· Hashmap: The index of global hash tables, which uses linear conflict chains to handle hash conflicts, and where all accesses to keys are processed by Hashmap.
· Page pool: On starting, the page pool divides the memory into pages, each with a size of 1M. The Slab Manager requests pages from the page pool and formats them into slabs of a specified size.
On starting, Tair MDB initializes all available memory. Thus, subsequent data storage sections no longer require dynamic allocation of memory from the operating system.
When using NVM, it is necessary to mmap corresponding files to the memory to obtain virtual address space. The built-in memory management modules can then use this space in a transparent way. In this process, therefore, there is no need to call malloc/free again so as to manage space on NVM.
Pressure Tests Begin: Issues Exposed
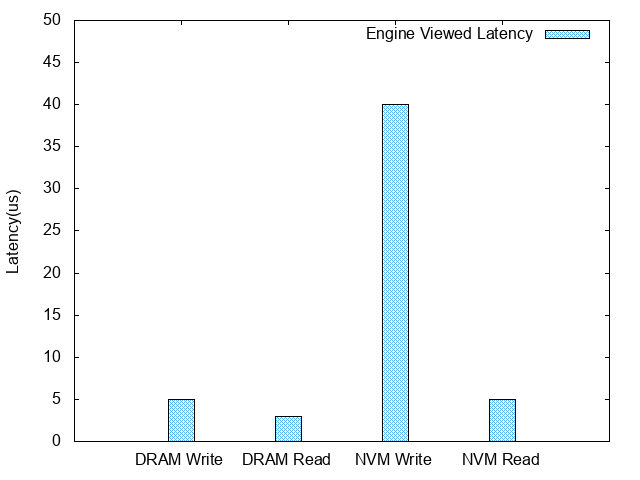
After the deployment of NVM, 100 bytes of entries were used to perform a pressure test on Tair MDB, yielding the following data:
Engine viewed latency:
Client viewed QPS:
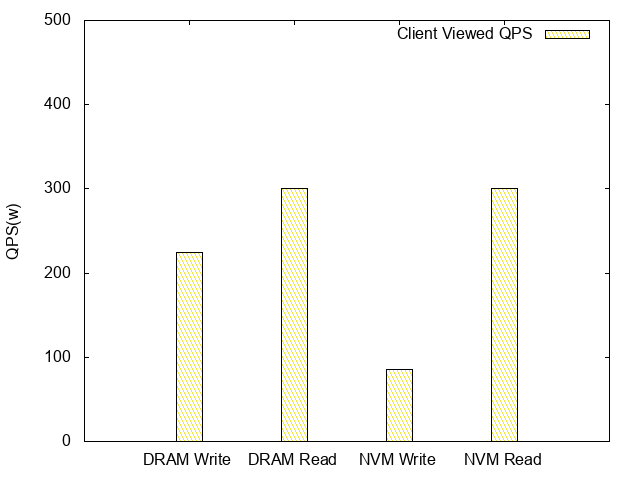
As these charts indicate, NVM-based read QPS latency is roughly equivalent to that of DRAM, while its write TPS latency is approximately one third of DRAM’s.
Analysis
The perf result indicates that all writing performance loss takes place on the lock. The critical section that this lock manages includes page writing operations mentioned in the previously specified memory layout. The likely cause, in this case, is the higher writing latency on NVM as compared with DRAM.
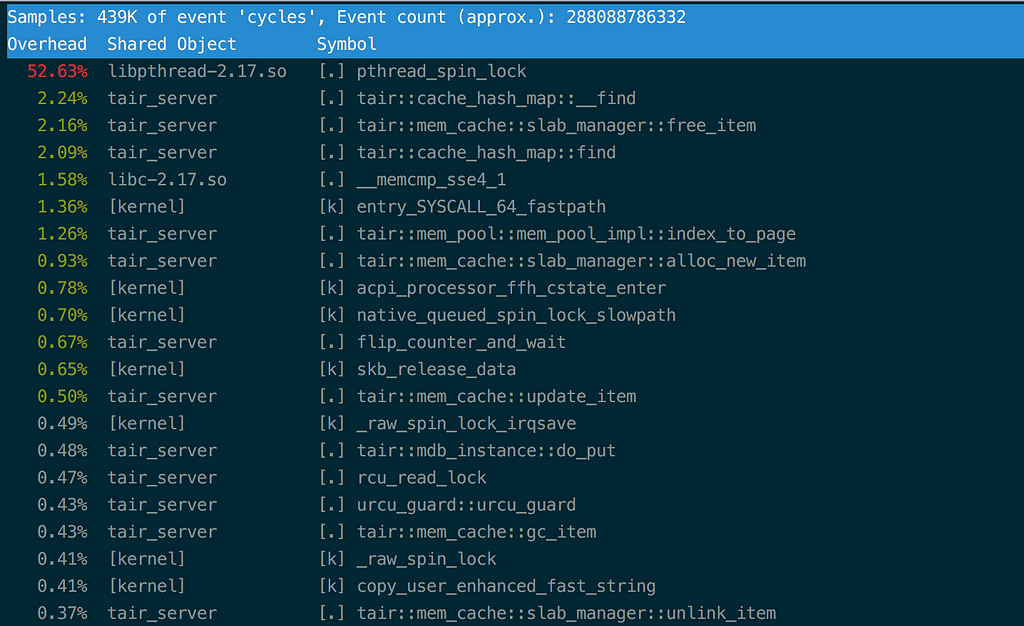
During pressure tests, pcm[3] was used to view the bandwidth statistics of NVM DIMMS, revealing highly imbalanced writing on one DIMM. In stable state, writing on this DIMM exceeded writing on other DIMMs by a factor of two.
Details of the above are illustrated in the following figure:
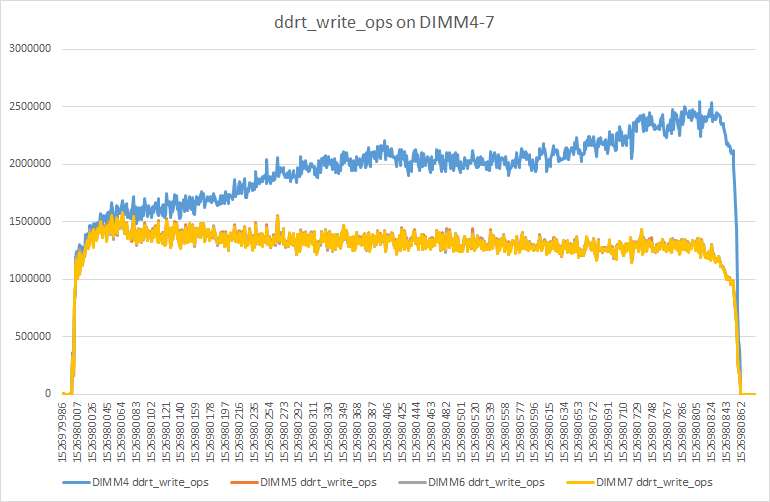
Before exploring these details further, the following section will offer an overview of the DIMM placement strategy used for NVM.
DIMM placement strategy
A single socket is arranged with four pieces of NVM DIMM in the following distribution:
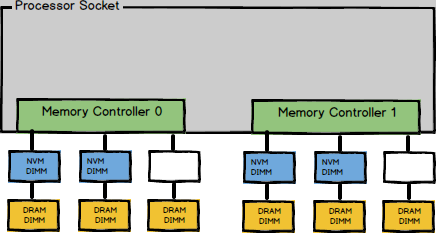
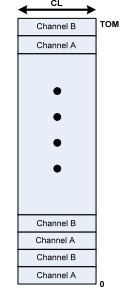
This placement strategy is called 2–2–1. Every socket comes with 4 pieces of DIMM belonging to four different channels, respectively. When using multiple channels, the CPU interleaves in order to use memory bandwidth more effectively. In the current placement strategy and configuration, the CPU has a unit of 4K, and interleaves in the DIMM sequence.
 Diagnosing hotspots: Causes of imbalance
Diagnosing hotspots: Causes of imbalance
From the memory interleaving strategy, it can be deduced that all writing is done in a single zone located on the imbalanced DIMM, causing this DIMM to retain significantly more writing than other DIMMs.
The next task in this case was identifying the processing logic that had led to the writing hotspot. A simplistic approach is locating suspected points and ruling them out one by one. The following section describes the approach the Tair team took to determine the processing logic.
Optimization begins: Locating hotspots
As mentioned above, writing hotspots result in imbalanced NVM DIMM access. Therefore, the first step in optimization is to find and process writing hotspots, such as by scattering hotspot accesses or placing access hotspots into DRAM.
The Tair team used Pin to look for hotspots [4]. The aforementioned Tair MDB obtains logic addresses to operate memory by performing mmap on files. Therefore, Pin can be used to grab mmap’s return value and further obtain NVM’s logic address in the program memory space. The team then continued using Pin to stub the programmed instructions of all operation memories and count the number of writings for every byte mapped from NVM to the address space.
Finally, the existence of writing hotspots was confirmed, and their corresponding zones were established as the page’s metadata. The team considered several options for tackling the writing hotspot problem, including adding padding and interleaving hotspots to each DIMM, storing fundamentally similar hot data in groups by DIMM, and moving hotspots back to DRAM. The team’s ultimate decision was to move slab_manager and page_info back to DRAM. The revised structure is as follows:
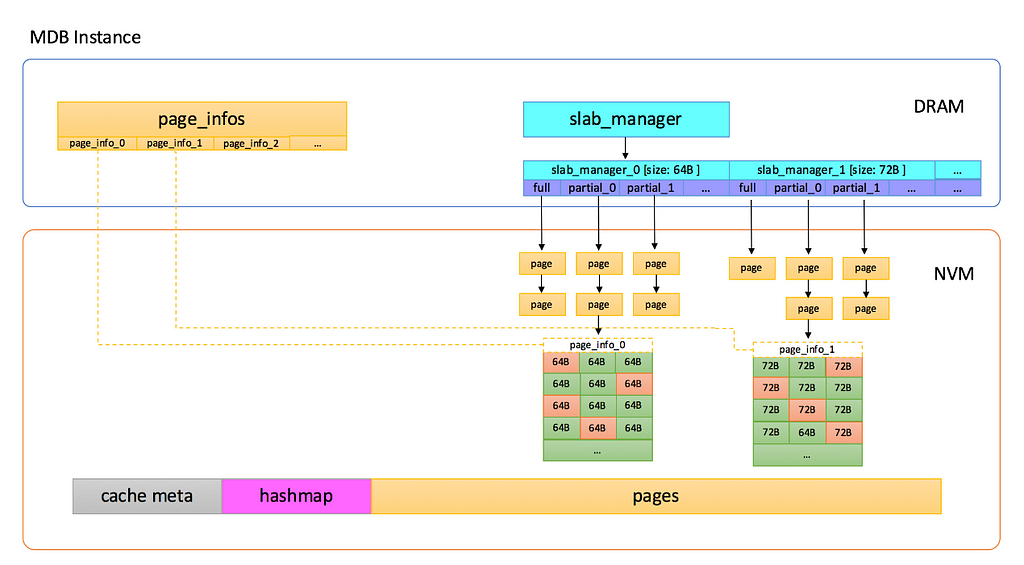
Upon making these changes the imbalance issue was effectively solved, increasing TPS from 85w to 140w while decreasing in-engine writing latency from 40us to 12us.
Solving excessive lock overhead
When TPS is at 140w, the overhead of the aforementioned pthread_spin_lock remains very high. The perf record result indicates that pthread_spin_lock consumes this call stack:
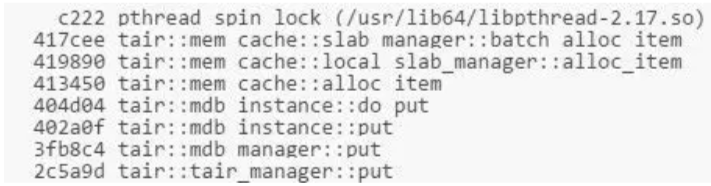
Analysis of the batch_alloc_item reveals that initializing items in the page can write huge volumes into NVM. This is where massive amounts of time are lost, as writing into NVM is slower than writing into DRAM.
According to Tair MDB’s logic, locking is only needed when linking the page into the slab_manager. Thus, the initialization operations on the item can be moved out of the critical section. Following this discovery, all writing operations into NVM in the Tair MDB code were then screened and optimized accordingly.
After optimization, the overhead of pthread_spin_lock dropped to normal range and TPS increased to 170w, while in-engine latency was 9us.
Optimization results
Balanced writing and lock granularity refinement, among other optimization efforts, effectively reduced latency and increased TPS to 170w, a 100% growth over the previous data. The difference in medium still retained a 30% deficit over the writing performance of DRAM. However, as caching service features more reading than writing, this deficit does not significantly affect the overall performance.
Channeling Findings: A New Design Guide
Based on their optimization efforts and production environment trials, the Tair team was able to determine a set of three key design rules for implementing NVM-based caching services. These rules are closely linked with specific NVM hardware features which significantly impact construction for caching services. Specifically, NVM is denser, less expensive, and features higher latency and smaller bandwidth than DRAM. It also presents imbalanced reading and writing issues and a higher writing latency than reading latency, and is prone to rapid wear when writing is done repeatedly at the same position.
The first rule: Avoid writing hotspots
Tair MDB experienced writing hotspot problems following the implementation of NVM, where writing hotspots aggravated medium wear and led to imbalanced load conditions. Before optimization, writing pressure fell squarely on just one DIMM, reflecting a failure to make full use of the entire DIMM bandwidth. In addition to memory layout (featuring mixed storage of metadata and data), access from transactions can also result in writing hotspots.
The Tair team’s methods for avoiding writing hotspots include the following:
· Separate metadata and data by moving the former into DRAM. Metadata is more frequently accessed than data. One example of metadata is the aforementioned page_info for Tair MDB. This makes NVM’s higher writing latency (compared with DRAM’s) less of a disadvantage from upper layers.
· Apply the logic for implementing Copy-On-Write in upper layers. In some scenarios, this can reduce wear to the hardware of specified zones. Updates to a data entry in Tair MDB do not in-place update the previous entry, but add a new entry to the head of the hashmap conflict chain. Such previous entries will be deleted asynchronously.
· Regularly check writing hotspots and dynamically migrate to DRAM for merges. For writing hotspots caused by accessing the aforementioned transactions, Tair MDB regularly checks and merges writing hotspots to limit access to medium in low layers.
The second rule: Reduce access to the critical section
NVM has higher writing latency than DRAM. Therefore, when the critical section includes operations on NVM, the concurrency degree of upper layers decreases as a result of amplified influence from the critical section.
The previously mentioned issue with lock overhead did not appear when running Tair MDB on DRAM, because running on DRAM automatically assumes that this critical section has a low overhead. However, this assumption becomes untrue when using NVM.
A common problem with using new media is that assumptions which are valid in previous software processes may no longer apply in a new medium, and procedures must shift to account for this. In this case, the Tair team recommends employing lock-free design wherever possible (based on data storage) when using NVM in caching services. This limits access to the critical section and avoids cascading connection effects caused by higher latency.
Tair MDB made most operations on the access path lock-free by introducing user space RCU, which significantly reduced the influence of NVM latency on upper layers.
The third rule: Implement an appropriate allocator
Allocators are fundamental components in transactions using NVM. The concurrency of allocators directly impacts the efficiency of the software, and the space management of allocators determines the space utilization rate. Designing and implementing allocators suited to specific software contexts is crucial in caching services using NVM.
Tair MDB studies show that allocators suitable for use with NVM must offer the following functions and features:
· Defragmentation: NVM is dense and has a large capacity. As a result, NVM wastes more space than DRAM under the same fragmentation ratio. The existence of the shard finish mechanism requires that upper layer apps avoid in-place updating and that allocators allocate spaces of fixed size wherever possible.
· A threadlocal quota: Similar to when reducing accesses to the critical section as discussed above, the latency of allocating resources from global resource pools will reduce the concurrency of allocation operations unless there is a quota for threadlocal.
· Capacity awareness: Allocators need to interpret the spaces they manage, and caching services must scale the spaces they manage accordingly. Allocators therefore must feature corresponding functions to meet those demands.
Experiments have shown the above design rules are both feasible and effective in real application scenarios and can be extended to other products where NVM implementation could prove beneficial.
Looking forward
As discussed in previous sections, Tair MDB still treats NVM as a volatile device, reducing the overall cost of services due to NVM’s high density and low price. Going forward, the Tair team will pursue new hardware and methods for capitalizing on NVM’s non-volatility, enabling transactions and other upper layer services.
(Original article by Fu Qiulei付秋雷)
If you are interested in contributing to Alibaba’s work on Tair, the group is currently welcoming applications from engaged developers at the Alibaba recruitment page.
References:
[1]https://github.com/pmem
[2]https://github.com/memkind/memkind
[3]https://github.com/opcm/pcm
[4]https://software.intel.com/en-us/articles/pin-a-dynamic-binary-instrumentation-tool
[5]Uncovered Technology! Tair, Distributed Caching System That Handles Thousands of Billions of Visits on Double 11
[6] Persistent Memory Programming: The Current State of the Ecosystem
(http://storageconference.us/2017/Presentations/Rudoff.pdf)
[7] Persistent Memory: What’s Done, Coming Soon, Expected Long-term
(https://blog.linuxplumbersconf.org/2015/ocw/system/presentations/3015/original/plumbers_2015.pdf)
Alibaba Tech
First hand and in-depth information about Alibaba’s latest technology → Facebook: “Alibaba Tech”. Twitter: “AlibabaTech”.

Going on a Tair: A Guide to NVM Caching Optimization was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.