Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Working out the best way to serve up files to your users can be a tricky business. There’s so many different scenarios, different technologies, different terminology.
In this post I hope to give you everything you need so that you can:
- know what file-splitting strategy will work best for your site and your users
- know how to do it
 Chop
Chop
According the Webpack glossary, there are two different types of file splitting. The terms sound interchangeable, but are apparently not:
Bundle splitting: creating more, smaller files (but loading them all on each network request anyway) for better caching.
Code splitting: dynamically loading code, so that users only download the code they need for the part of the site that they’re viewing.
That second one sounds far more appealing, doesn’t it? And in fact, many articles on the matter seem to make the assumption that this is the only worthwhile case for making smaller JavaScript files.
But I’m here to tell you that the first one is far more valuable on many sites, and should be the first thing you do for all sites.
Let’s dive in.
Bundle splitting
The idea behind bundle splitting is pretty simple. If you have one giant file, and change one line of code, the user must download that entire file again. But if you’d split it into two files, then the user would only need to download the one that changed, and the browser would serve the other file from cache.
It’s worth noting that since bundle splitting is all about caching, it makes no difference to first time visitors.
(I think too much performance talk is all about first time visits to a site. Maybe this is partially because ‘first impressions matter’, and partly because it’s nice and simple to measure.)
When it comes to frequent visitors, it can be tricky to quantify the impact that performance enhancements have, but quantify we must!
This is going to need a spreadsheet, so we’ll need to lock in a very specific set of circumstances that we can test each caching strategy against.
Here is the scenario I mentioned in the previous paragraph:
- Alice visits our site once a week for 10 weeks
- We update the site once a week
- We’re updating our ‘product list’ page every week
- We also have a ‘product details’ page, but we’re not working on it at the moment
- In week 5 we add a new npm package to the site
- In week 8 we update one of our existing npm packages
Certain types of people (like me) will want to try and make this scenario as realistic as possible. Don’t do that. The actual scenario doesn’t matter, and we’ll find out why later. (Suspense!)
The baseline
Let’s say our total JavaScript package is a meaty 400 KB, and we’re currently loading this as a single file called main.js.
We have a Webpack config looking something like this (I’m leaving out non-relevant config stuff):
(For those new to cache busting: any time I say main.js, what I actually mean is something like main.xMePWxHo.js where the crazy string of letters is a hash of the contents of the file. This means a different file name when the code in your application changes, thus forcing the browser to download the new file.)
Each week when we push some new changes to the site, the contenthash of this package changes. So each week, Alice visits our site and has to download a new 400 KB file.
If we were to make a sexy table of these events, it would look like this.
 World’s most unnecessary total row
World’s most unnecessary total row
That’s 4.12 MB, over 10 weeks.
We can do better.
Splitting out vendor packages
Let’s split our packages into a main.js and vendor.js file.
This is easy, sort of:
Webpack 4 makes an effort to do the best thing for you, without you having to tell it exactly how you want to split your bundles.
This lead to several instances of “hey that’s neat. Nice one, Webpack!”
And many instances of “WHAT THE HELL ARE YOU DOING TO MY BUNDLES!?”
Anyhoo, adding optimization.splitChunks.chunks = 'all' is a way of saying “put everything in node_modules into a file called vendors~main.js".
With this basic bundle splitting in place, Alice still downloads a new 200 KB main.js on each visit, but only downloads the 200 KB vendors.js in week one, eight and five (not in that order).
 In a moment of serendipity, both packages turn out to be exactly 200 KB.
In a moment of serendipity, both packages turn out to be exactly 200 KB.
That’s 2.64 MB.
A 36% reduction. Not bad for adding five lines of code to our config. Go do that now before reading any further. If you need to upgrade from Webpack 3 to 4, don’t fret, it’s pretty painless (and still free!).
I think this performance improvement seems somehow more abstract because it’s spread out over 10 weeks, but it’s a real 36% reduction in bytes shipped to a loyal user and we should be proud of ourselves.
But we can do better.
Splitting out each npm package
Our vendors.js suffers the same problem that our original main.js file did — a change to one part of it means re-downloading all parts of it.
So why not have a separate file for each npm package? It’s easy enough to do.
So let’s split out our react, lodash, redux, moment, etc., into different files:
The docs will do a good job of explaining most things in here, but I’ll explain a bit about the groovy parts, because they took me so damn long to get right.
- Webpack has some clever defaults that aren’t so clever, like a maximum of 3 files when splitting the output files, and a minimum file size of 30 KB (all smaller files would be joined together). So I have overridden these.
- cacheGroups is where we define rules for how Webpack should group chunks into output files. I have one here called ‘vendor’ that will be used for any module being loaded from node_modules. Normally, you would just define a name for the output file as a string. But I’m defining name as a function (which will be called for every parsed file). I’m then returning the name of the package from the path of the module. As a result, we’ll get one file for each package, e.g. npm.react-dom.899sadfhj4.js.
- NPM package names must be URL-safe in order to be published, so we don’t need to encodeURI that packageName. BUT, I had trouble with a .NET server not serving files with an @ in the name (from a scoped package), so I’ve replaced that in this snippet.
- This whole setup is great because it’s set-and-forget. No maintenance required — I didn’t need to refer to any packages by name.
Alice will still be re-downloading our 200 KB main.js file each week, and will still download 200 KB of npm packages on her first visit, but she will never download the same package twice.
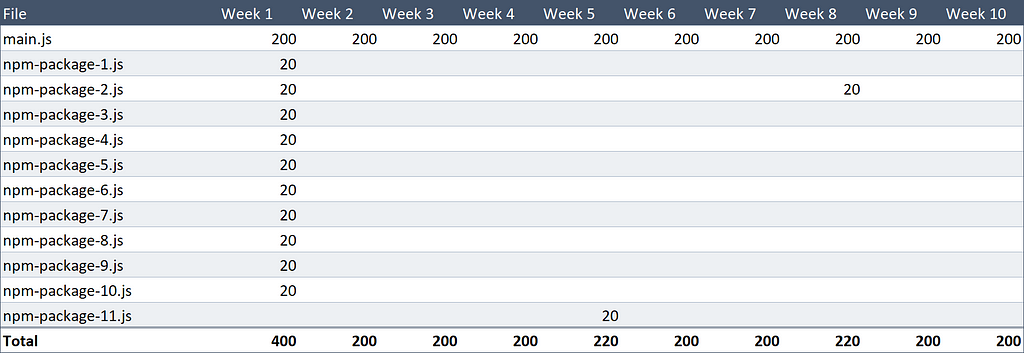 It turns out that every npm package was exactly 20 KB. What are the odds!
It turns out that every npm package was exactly 20 KB. What are the odds!
That’s 2.24 MB.
A 44% reduction from the baseline, that’s pretty cool for some code that you can copy/paste from a blog post.
I wonder if it’s possible to surpass 50%?
Wouldn’t that be something.
Splitting out areas of the application code
Let’s turn to the main.js file which poor old Alice is downloading again and again (and again).
I mentioned earlier that we have two distinct sections on this site: a product list, and a product detail page. The unique code in each of these areas is 25 KB (leaving 150 KB of shared code).
Our ‘product detail’ page isn’t changing much nowadays, because we made it so perfect. So if we make it a separate file, it can be served from cache most of the time.
Also, did you know that we have a giant file of inline SVG for rendering icons, weighing in at a hefty 25 KB and rarely changing?
We should do something about that.
We’ll just manually add some entry points, telling Webpack to create a file for each of those items.
Good ol’ Webpack will also create files for things that are shared between, say, ProductList and ProductPage so that we don’t get duplicated code.
This’ll save dear Alice an extra 50 KB of downloads most weeks.
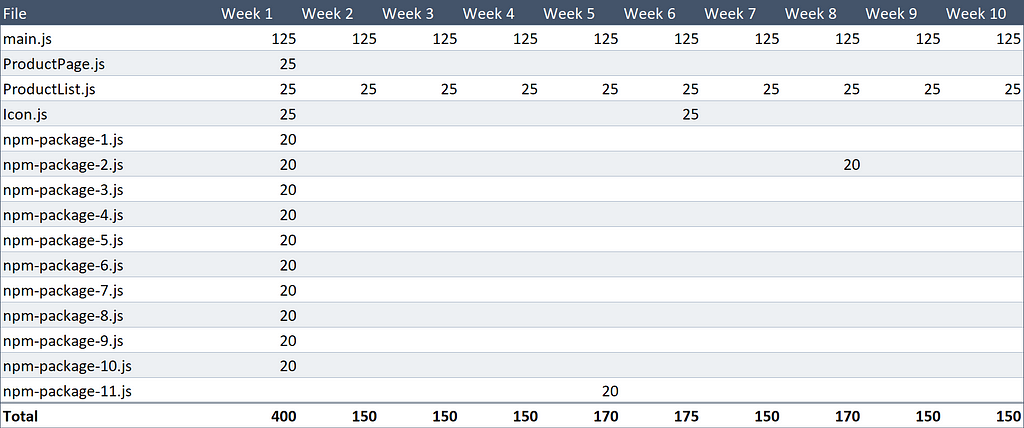 We tweaked an icon in week six, as I’m quite sure you recall
We tweaked an icon in week six, as I’m quite sure you recall
That’s only 1.815 MB!
We’ve saved Alice a whopping 56% in downloads, and this saving will (in our theoretic scenario) continue until the end of time.
And all of this is done only with changes in our Webpack config — we haven’t made any changes to our application code.
I mentioned earlier that the exact scenario under test doesn’t really matter. This is because, no matter what scenario you come up with, the conclusion will be the same: split your application into sensible little files so your users download less code.
Soon, I’m going to talk about ‘code splitting’ — the other type of file-chopping — but first I want to address the three questions you’re thinking of right now.
#1: Isn’t it slower to have lots of network requests?
The answer to that is a very loud “NO”.
This used to be the case back in the days of HTTP/1.1, but it is not the case with HTTP/2.
Although, this post from 2016 and Khan Academy’s post from 2015 both reached the conclusion that even with HTTP/2, downloading too many files was still slower. But in both of these posts, ‘too many’ files meant ‘several hundred’. So just keep in mind that if you’ve got hundreds of files, you might start hitting concurrency limits.
If you’re wondering, support for HTTP/2 goes back to IE 11 on Windows 10. I’ve done an exhaustive survey of everyone using an older setup than that and they unanimously assured me that they don’t care how quickly websites load.
#2: Isn’t there overhead/boilerplate code in each webpack bundle?
This is true.
#3: Won’t I lose out on compression by having multiple small files?
Yep, that’s true too.
Well, shit:
- more files = more Webpack boilerplate
- more files = less compression
Let’s quantify this so we know exactly how much to fret.
…
OK I just did a test and a 190 KB site split into 19 files added about 2% to the total bytes sent to the browser.
So … 2% more on the first visit and 60% less on every other visit until the end of the universe.
The correct amount to fret is: not at all.
While I was testing 1 file vs 19, I thought I’d give it a go on some different networks, including HTTP/1.1
Here’s my table that is wildly supportive of the ‘more files is better’ idea:
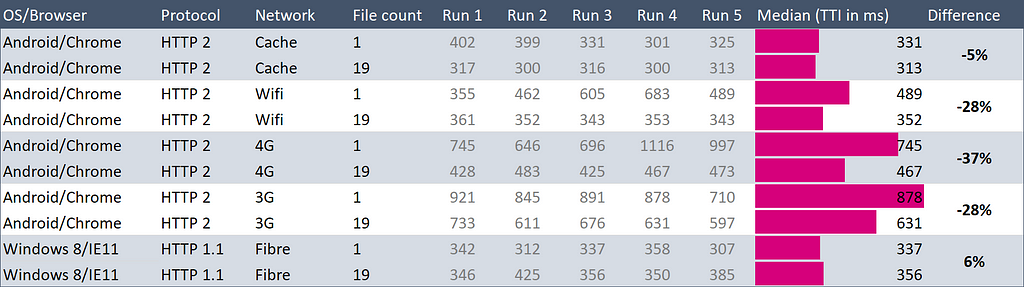 Loading two versions of the same 190 KB site (from Firebase static hosting)
Loading two versions of the same 190 KB site (from Firebase static hosting)
On 3G and 4G this site loaded in 30% less time when there were 19 files.
Or did it?
This is pretty noisy data. For example, on 4G on run 2, the site loaded in 646ms, then two runs later it took 1,116ms — 73% longer, with no change. So it seems a bit sneaky to claim that HTTP/2 is ‘30% faster’.
(Coming soon: a custom chart type designed to visualise the difference in page load times.)
I created this table to try and quantify what difference HTTP/2 made, but really the only thing I can say is “it probably makes no significant difference”.
The real surprise was those last two rows. That’s old Windows and HTTP/1.1 which I would have bet would be much slower. I guess I need slower internet.
Story time! I downloaded a Windows 7 virtual machine from Microsoft’s site to test these things.
It came with IE8, which I wanted to update to IE9.
So I headed over to Microsoft’s download page for IE9 and …
 OMG. SMH. FML.
OMG. SMH. FML.
One final word on HTTP/2, did you know it’s built into Node now? If you want to have a play, I wrote a little 100-line HTTP/2 server with gzip, brotli and response caching for your testing pleasure.
That’s everything I have to say about bundle splitting. I think the only downside to this approach is constantly having to convince people that loading lots of small files is OK.
Now, to talk about the other type of file-chopping…
Code splitting (don’t load code you don’t need to)
This particular approach only makes sense on some sites, says me.
I like to apply the 20/20 rule that I just made up: if there’s a part of your site that only 20% of users go to, and it’s bigger than 20% of your site’s JavaScript, then you should only load that code on demand.
Adjust those numbers to taste, obviously, and there’s more complex scenarios that that, obviously. The point is, there’s a balance, and it’s OK to decide that code splitting simply doesn’t make sense for your site.
How to decide?
Let’s say you’ve got a shopping site and you’re wondering if you should split out the code for the ‘checkout’, because only 30% of your visitors make it there.
The first thing to do is sell better stuff.
The second thing is to work out how much code is completely unique to the checkout. Since you should always do ‘bundle splitting’ before you do ‘code splitting’, you might already know how big this part of your code is.
(It might be smaller than you think, so do the sums before you get too excited. If you have a React site, for example, then your store, reducers, routing, actions, etc. will all be shared across the whole site. The unique parts will mostly be components and their helpers.)
So, you note that the code that is completely unique to your checkout page is 7 KB. The rest of the site is 300 KB. I would look at this and say meh, I’m not going to bother code-slitting this, for a few reasons:
- Loading it up front is no slower. Remember that you’re loading all these files in parallel. See if you can record a difference in the load times between 300 KB and 307 KB.
- If you load this code later, the user will have to wait for that file after clicking on ‘TAKE MY MONEY’ — the very time at which you want the least friction.
- Code splitting requires changes to your application code. It introduces asynchronous logic where previously there was only synchronous logic. It’s not rocket science, but it’s complexity that I think should be justified by a perceivable improvement to the user experience.
OK, that’s all the party pooper “this exciting tech might not apply to you” stuff.
Let’s look at two examples of code-splitting…
Polyfills
I’ll start with this because it applies to most sites, and is a nice simple introduction.
I’m using a bunch of fancy features in my site, so I’ve got a file that imports all the polyfills I need. It includes these eight lines:
I import this file right at the top of my entry point, index.js.
With the Webpack config from the bundle splitting section, my polyfills will be automatically split into four different files since there’s four npm packages here. They’re about 25 KB all up, and 90% of browsers don’t need them, so it’s worth loading these dynamically.
With Webpack 4 and the import() syntax (not to be confused with the import syntax), conditionally loading the polyfills is pretty easy.
Make sense? If all that stuff is supported, then render the page. Otherwise, import polyfills then render the page. When this code runs in the browser, Webpack’s runtime will handle the loading of those four npm packages, and when they’ve been downloaded and parsed, will call render() and things will carry on.
(BTW, to use import(), you’ll need Babel’s dynamic-import plugin. Also, as the Webpack docs explain, import() uses promises, so you’ll need to polyfill that separate to the other polyfills.)
Easy, right?
Here’s something a bit trickier…
Route-based dynamic loading (React specific)
Going back to the Alice example, let’s say that the site now has an ‘administration’ section, where sellers of products can log in and administer the crap that they have for sale.
This section has many wonderful features, plenty of charts, and a big fat charting library from npm. Because I was already doing bundle splitting, I could see that these were a shade over 100 KB all up.
Currently, I have a routing setup that will render <AdminPage> when the user is viewing an /admin URL. When Webpack bundles everything up, it’s going to find import AdminPage from './AdminPage.js' and say “hey, I need to include this in the initial payload”.
But we don’t want it to. We need to put that reference to the admin page inside a dynamic import, like import('./AdminPage.js') so that Webpack knows to load it dynamically.
It’s pretty cool, no config required.
So instead of referring to AdminPage directly, I could create another component that will be rendered when the user goes the the /admin URL. It might look something like this:
The concept is pretty straightforward, right? When this component mounts (meaning that the user is at the /admin URL), we’ll dynamically load ./AdminPage.js and then save a reference to that component in state.
In the render method, we simply render <div>Loading...</div> while we’re waiting for the <AdminPage> to load, or the <AdminPage> once it’s been loaded and stored in state.
I wanted to do this myself for fun, but in the real world, you’d just use react-loadable, as described in the React docs on code-splitting.
Righto, I think that’s everything. Is there any point in saying what I already said above, but in fewer words?
- If people ever visit your site more than one time, split your code up into many little files.
- If you have large parts of your site that most users don’t visit, load that code dynamically.
Thanks for reading, have a tops day!
Dammit I forgot to mention CSS.

The 100% correct way to split your chunks with Webpack was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.