Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.

Why Probability? Why can’t we leave linear regression just the way it is! Why to make it difficult? All these question were in my mind, when i was heading through this topic but as we know when there is loads of data suddenly randomness appears, she calls her sister probability with her. When there is probability we can’t leave Gaussian alone. All these words are so heavy that i will make sure to put some magic and make it easy for you. Let’s dive together.
Do you remember these equation from linear regression?
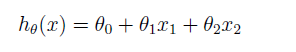
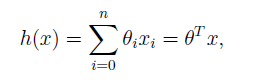 If not, Please read the article on Supervised Learning.
If not, Please read the article on Supervised Learning.
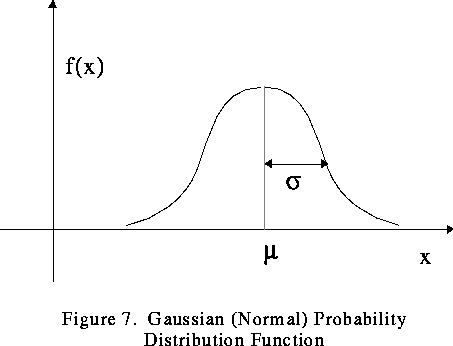
In probability theory, the very common continuous probability distribution is also known as Normal Distribution or Gaussian Distribution. This normal distribution is sometimes informally called as the bell curve as shown in the below image :
The probability density of above normal distribution or Gaussian is given by :
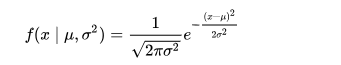
Where,
- ‘mu’ is the mean
- sigma is the standard deviation
- sigma square is the variance
Now, as we have probability distribution equation and if we write the probability distribution of the predicted values ‘Y’ of the given ‘X’ and the parameter Theta is given as follows:
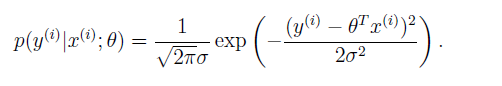
Still the question remains, why always Gaussian? Why not something else? The answer lies in the “Central Limit Theorem”. This gives us an idea that when you take a bunch of random numbers from almost any distribution and add them together, you get something which is normally distributed. The more numbers you add, the more normally distributed it gets. In a typical machine learning problem, you will have errors from many different sources (e.g. measurement error, data entry error, classification error, data corruption…) and it’s not completely unreasonable to think that the combined effect of all of these errors is approximately normal.
When we wish to explicitly view the probability distribution function of theta θ, we will instead call it the Likelihood function:
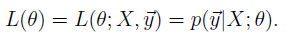
When taken for ‘m’ training examples, the likelihood function is modified as follows :
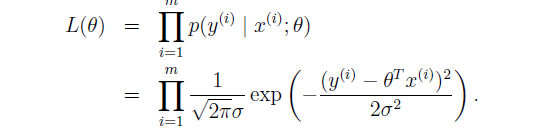
Likelihood and Probability are the same things. It is called likelihood because when we want to see the above equation as function of theta while keeping ‘X’ and ‘Y’ constant.
Principle of maximum likelihood says that “Choose theta to maximize the likelihood or choose parameters that makes data more probable as possible”. Instead of maximizing L(theta), we can also maximize any strictly increasing function of L(theta). In particular, the derivations will be a bit simpler if we instead maximize the log likelihood we call it as ℓ(theta):
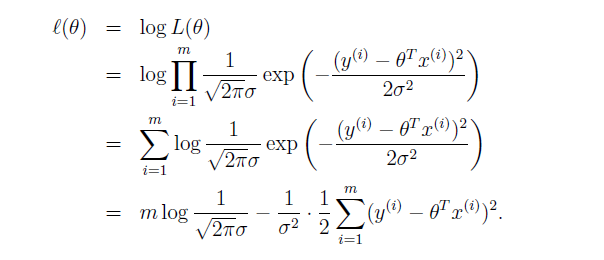
which gives similar answer as minimizing J(theta):
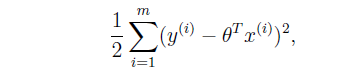
This probabilistic Interpretation will be further used in Logistic Regression.
If you find any inconsistency in my post, please feel free to point out in the comments. Thanks for reading.
If you want to connect with me. Please feel free to connect with me on LinkedIn.
Sameer Negi - autonomous Vehicle Trainee - Infosys | LinkedIn

What happens when Probability defines Linear Regression was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.